Файл: Разработка бд для асу Московская доставка Курсовая работа Студента 4 курса дневного отделения группа Студент (подпись).docx
Добавлен: 04.12.2023
Просмотров: 516
Скачиваний: 11
СОДЕРЖАНИЕ
Глава 1. Анализ предметной области АСУ “Московская доставка”
1.1 Системный анализ предметной области АСУ “Московская доставка”
1.2 Обзор информационных технологий, подходящих для разработки БД
1.2.1 Настольные СУБД. Microsoft Access
1.2.2 Полупрофессиональные СУБД. SQLite
1.2.3 Профессиональные СУБД. Oracle database
1.3 Обзор продуктов аналогов АСУ “Московская доставка”
1.3.1 Информационная система службы доставки “UPS”
1.3.2 Информационная система службы доставки “IKEA”
1.4 Требования к разрабатываемой БД курьерской службы “Московская доставка”
2.1 Разработка инфологической модели БД курьерской службы “Московская доставка”
2.2 Обоснование выбора модели данных
2.2.3 Объектно-ориентированная модель данных
2.2.4 Реляционная модель данных
2.3 Логическое проектирование БД курьерской службы “Московская доставка”
2.4 Нормализация схемы базы данных
Глава 3. Программная реализация БД для курьерской службы “Московская доставка”
2.2 Обоснование выбора модели данных
Под даталогической моделью понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физические организации. При этом даталогическая (или просто логическая) модель строится на основе инфологической модели конкретной предметной области, с учётом её особенностей.
Существуют несколько типов даталогических моделей данных:
-
сетевая модель; -
иерархическая модель; -
объектно-ориентированная модель; -
реляционная модель;
Для того, чтобы создать даталогическую модель данных для информационной системы на основе инфологической, необходимо сначала выбрать один из ее типов, приведенных выше. Далее сделать выбор СУБД, в которой будет реализована БД, так как даталогическую модель строят в терминах конкретной СУБД. Рассмотрим каждый из типов даталогичской модели.
2.2.1 Иерархическая модель
Иерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней. Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья). Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных. Первую вершину называют корневой вершиной. Она удовлетворяет условиям:
-
Иерархия начинается с корневой вершины. -
Каждая вершина соответствует одному или нескольким атрибутам. -
Hа уровнях с большим номером находятся зависимые вершины. Вершин предшествующего уровня является начальной для новых зависимых вершин. -
Каждая вершина, находящаяся на уровне i, соединена с одной и только одной вершиной уровня i-1, за исключением корневой вершины. -
Корневая вершина может быть связана с одной или несколькими зависимыми вершинами. -
Доступ к каждой вершине происходит через корневую по единственному пути -
Существует произвольное количество вершин каждого уровня.
Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев.
Плюсы иерархической модели данных:
-
Простота использования и построения -
Обеспечение определенного уровня независимости данных -
Простота оценки операционных характеристик
Минусы иерархической модели данных:
-
Отношение “многие ко многим” реализуется очень громоздко и приводит к появлению избыточности данных, что нежелательно на физическом уровне -
Иерархическая упорядоченность усложняет операции удаления и включения -
Доступ к любой вершине возможен только через корневую, что увеличивает время доступа
П
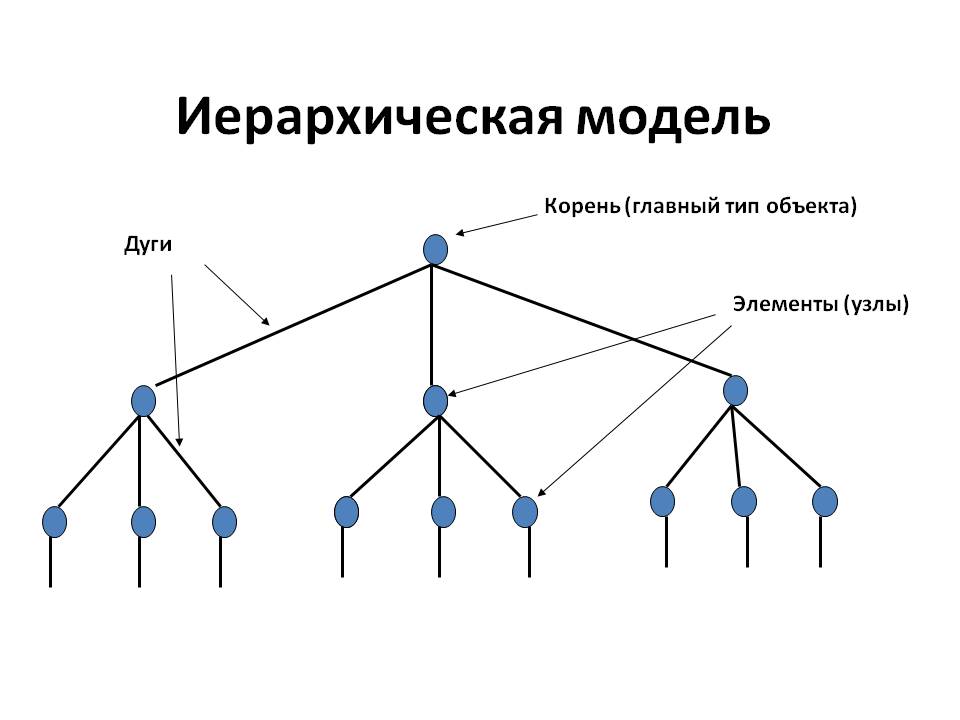 ример иерархической модели приведен на рисунке 5.
ример иерархической модели приведен на рисунке 5.Рисунок 5 – Иерархическая модель данных
2.2.2 Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков. Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
-
каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L; -
каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L
Плюсы сетевой модели данных:
-
Возможность эффективной реализации по показателям затрат памяти и оперативности
Минусы сетевой модели данных:
-
Высокая сложность и жесткость схемы БД -
Не является полностью независимой
П
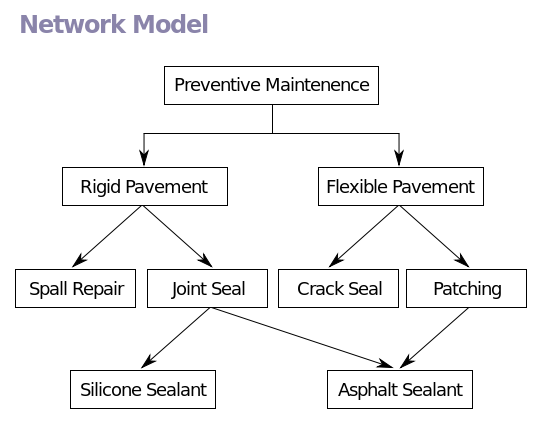 ример сетевой модели приведен на рисунке 6:
ример сетевой модели приведен на рисунке 6:Рисунок 6 – Сетевая модель данных
2.2.3 Объектно-ориентированная модель данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма.
Плюсы объектно-ориентированной модели:
-
Возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки.
Минусы объектно-ориентированной модели:
-
Высокая понятийная сложность -
Неудобство обработки данных -
Низкая скорость выполнения запросов
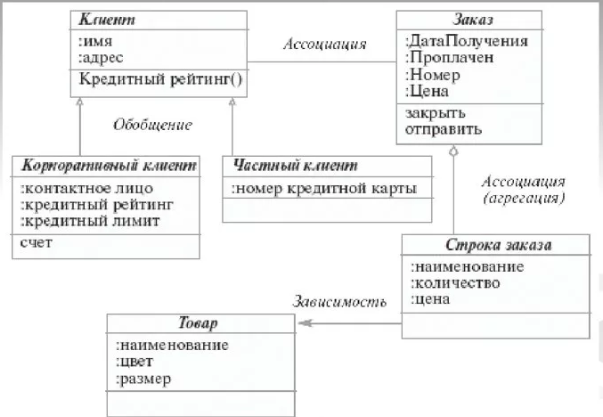 Пример объектно-ориентированной модели приведен на рисунке 7:
Пример объектно-ориентированной модели приведен на рисунке 7:Рисунок 7 – Объектно-ориентированная модель данных
2.2.4 Реляционная модель данных
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. Представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название "реляционная" происходит от английского relation - "отношение").
Реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
Ограничения реляционной модели:
-
Должны отсутствовать записи-дубликаты -
Столбцы реляционной таблицы поименованы, поэтому их порядок не важен. -
Порядок записей может быть произвольным -
Каждая запись уникальна и однозначно определяется значением ключа. -
Каждый элемент таблицы называется полем, может быть однозначно определен. -
В столбце записываются данные одного типа
Недостатки традиционных реляционных моделей:
-
Избыточность по полям (из-за создания связей) -
В качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных.
П
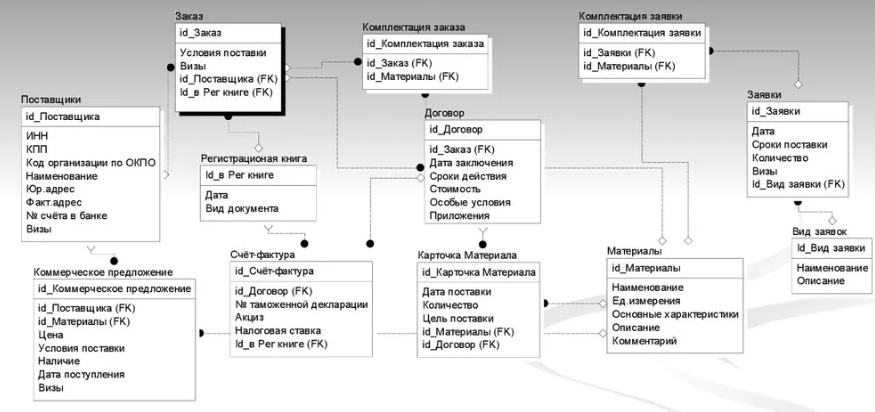 ример реляционной модели приведен на рисунке 8:
ример реляционной модели приведен на рисунке 8:Рисунок 8 – Реляционная модель данных
2.3 Логическое проектирование БД курьерской службы “Московская доставка”
Рассмотрев все типы моделей данных, было принято решение, что для логического проектирования будет использоваться реляционная модель данных, т.к. она наиболее полно соответствует требованиям, предъявленным к разрабатываемой информационной системе:
-
отсутствие дублируемой информации; -
поддержание целостности данных при вставке, удалении или изменении записей; -
возможность организации всех видов связи между отношениями 1:1, 1:M и M:M.
В реляционной базе данных даталогическое проектирование приводит к разработке корректной схемы базы данных, т.е. такой схемы, в которой отсутствуют нежелательные зависимости между атрибутами. При этом можно использовать процесс проектирования с помощью декомпозиции, т.е. последовательно нормализовать схему отношений, тем самым накладывая ограничения и избавляясь от нежелательных зависимостей между атрибутами.