Файл: Принципы работы mpi в операционной системе Windows Краткая теория.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.12.2023
Просмотров: 40
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
MPI_WAIT(request, status)
INOUT request имя запроса
OUT status статус оъекта
int MPI_Wait(MPI_Request *request, MPI_Status *status)
Запрос к MPI_WAIT возвращает управление, после того как операция, идентифицированная request, выполнилась. То есть это блокированная функция. Если объект системы, указанный request был первоначально создан неблокированными посылающей или получающей функциями, то этот объект освобождается функцией MPI_WAIT, и request устанавливается в MPI_REQUEST_NULL. Статус объекта содержит информацию относительно выполненной операции.
MPI_TEST(request, flag, status)
INOUT request имя запроса
OUT flag true, если операция выполнилась, иначе
false
OUT status стаус объекта
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)
Запрос к MPI_TEST возвращает flag = true, если операция, идентифицированная request, выполнилась. В этом случае, статус состояния содержит информацию относительно законченной операции. Если объект системы, указанный request был первоначально создан неблокированными посылающей или получающей функциями, то этот объект освобождается функцией MPI_TEST, и request устанавливается в MPI_REQUEST_NULL. Запрос возвращает flag = false, если операция не выполнилась. В этом случае, значение статуса состояния неопределено. То есть это не блокированная функция.
Синхронные посылающие функции
MPI_SSEND(buf, count, datatype, dest, tag, comm)
IN buf адрес передаваемого буфера
IN count количество передаваемых элементов
IN datatype тип передаваемых элементов
IN dest ранг приемника
IN tag тег сообщения
IN comm коммуникатор (communicator)
int MPI_Ssend(void* buf, int count, MPI_Datatype datatype,intdest, int tag, MPI_Comm comm)
MPI_SSEND - блокированная, синхронная функция передачи данных.
MPI_ISSEND(buf, count, datatype, dest, tag, comm, request)
IN buf адрес передаваемого буфера
IN count количество передаваемых элементов
IN datatype тип передаваемых элементов
IN dest ранг приемника
IN tag тег сообщения
IN comm коммуникатор (communicator)
OUT request заголовок запроса
int MPI_Issend(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request)
MPI_ISSEND - неблокированная, синхронная функция передачи данных. Если соответствующей принимающей функцией является неблокированная принимающая функция MPI_IRECV, то передающая функция MPI_ISSEND синхронизуется с переданными в систему параметрами соответствующей не блокированной принимающей функции. А функции Wait и Test со стороны передающей функции только проверяют наличие этих выставленных параметров со стороны неблокированной принимающей функции.
При синхронных взаимодействиях пересылаемый буфер передается в принимаемый буфер "напрямую" (память-память) минуя сохранение в промежуточных буферах.
Коллективные взаимодействия
Коллективная связь обеспечивает обмен данными среди всех процессов в группе, указанной аргументом коммуникатора.
Коллективные сделаны более ограниченными чем point-to-point операции. В отличие от point-to-point операций, количество посланных данных в этих функциях должно быть точно согласовано с количеством данных, указанных приемником. Коллективные функции имеют только блокированные версии. Коллективные функции не используют аргумент тега. Аргумент типа данных должен быть одним и тем же во всех процессах, участвующих во взаимодействии. Внутри каждой области связи, коллективные запросы строго согласованы согласно порядку выполнения. В коллективном запросе к MPI_BCAST должны участвовать все процессы, объединенные коммуникатором. Коллективные функции не согласуются с функциями парных взаимодействий.
Синхронизация
MPI_BARRIER(comm)
IN comm коммуникатор
int MPI_Barrier(MPI_Comm comm)
MPI_BARRIER блокирует вызывающий оператор, пока все элементы группы не вызовут его. В любом процессе запрос возвращается только после того, как все элементы группы вошли в запрос.
Трансляционный обмен данными
MPI_BCAST(buffer, count, datatype, root, comm)
INOUT buffer адрес буфера
IN count количество элементов в буфере
IN datatype тип данных
IN root ранг корневого процесса
IN comm коммуникатор
int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm)
MPI_BCAST передает сообщение из процесса с рангом root ко всем процессам группы. Аргументы корня и на всех других процессах должены иметь идентичные значения, и comm должна представлять ту же самую область связи. После возвращения, содержимое буфера buffer из корня копируется ко всем процессам в буфер buffer.
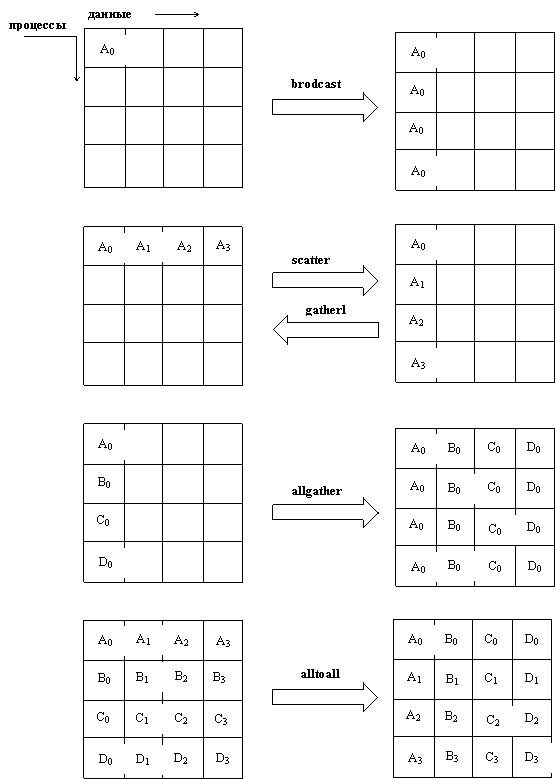
Рис. 4.1. Иллюстрация коллективных передающих функций для группы из шести процессов. В каждой клетке представленны локальные данные в одном процессе. Например, в broadcast передает данные A0 только первый процесс, а другие процессы принимают эти данные.
Сбор данных
MPI_GATHER(sendbuf, sendcount, sendtype, recvbuf, recvcount, recvtype, root, comm)
IN sendbuf адрес передаваемого буфера
IN sendcount количество передаваемых элементов
IN sendtype тип передаваемых элементов
OUT recvbuf адрес буфера приема
IN recvcount количество принимаемых элементов в
каждом процессе
IN recvtype тип принимаемых данных
IN root ранг принимающего процесса
IN comm коммуникатор
int MPI_Gather(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm)
Каждый процесс (включая процесс корня) посылает содержимое его посылаемого буфера к процессу корня. Процесс корня получает сообщения и хранит их в порядке рангов, посылающих процессов. Результат выглядит так, как будто каждый из n процессов в группе (включая процесс корня) выполнил запрос к MPI_SEND(sendbuf,sendcount,sendtype,root, ...), и корень выполнил n запросов к MPI_RECV(recvbuf+i*recvcount,recvcount, recvtype,i,...). Приемный буфер игнорируется для всех процессов не равных корню. Аргумент recvcount в корне указывает число элементов, которые получает корень от каждого процесса, а не общее число элементов, которые он получает всего.
ПРИМЕР 4.1.
Прием корнем 100 элементов от каждого процесса группы. (рис. 4.2).
MPI_Comm comm;
int gsize, sendarray[100];
int root, *rbuf;
...
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*100*sizeof(int));
MPI_Gather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
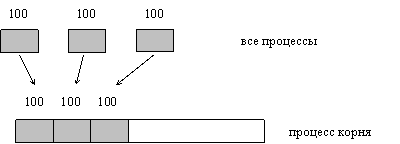
Рис. 4.2. Процесс корня принимает 100 элементов от каждого процесса группы.
Сбор данных (векторный вариант)
MPI_GATHERV(sendbuf, sendcount, sendtype, recvbuf, recvcounts, displs, recvtype, root, comm)
IN sendbuf адрес передаваемого буфера
IN sendcount количество передаваемых элементов
IN sendtype тип передаваемых элементов
OUT recvbuf адрес буфера приема
IN recvcounts целочисленный массив, указывающий
количество принимаемых элементов в
каждом процессе
IN displs целочисленный массив смещений принятых
пакетов данных относительно друг друга
IN recvtype тип принимаемых данных
IN root ранг принимающего процесса
IN comm коммуникатор (communicator)
int MPI_Gatherv(void* sendbuf, int sendcount, MPI_Datatype sendtype, void* recvbuf, int *recvcounts, int *displs, MPI_Datatype recvtype, int root,
MPI_Comm comm)
MPI_GATHERV расширяет функциональные возможности MPI_GATHER, позволяя изменяющийся counts данных из каждого процесса, так как recvcounts - теперь массив. Она также допускает большее количество гибкости относительно того, где данные размещаются на корне, обеспечивая новый аргумент, displs. Данные, посланные из процесса j, размещаются в j-м блоке в буфере приема recvbuf на процессе корня. Блок j-й в буфере recvbuf начинается в смещении от начала предыдущего пакета в displs[j] элементов (в терминах recvtype). Буфер приема игнорируется для всех процессов, не принадлежащих корню. Все аргументы в функции на корне процесса значимы, в то время как на других процессах, значитмы только аргументы sendbuf, sendcount, sendtype, root, и comm. Аргументы должны иметь идентичные значения на всех процессах, и comm должна представлять ту же самую область связи.
ПРИМЕР 4.2
Каждый процесс посылают 100 элементов. В принимающем процессе пакеты (в 100 элементов) нужно разместить на растоянии с некоторым шагом. Используется MPI_GATHERV и аргумент displs, чтобы достичь этого эффекта. Допустим шаг stride ≥ 100. (рис. 4.3).
MPI_Comm comm;
int gsize, sendarray[100];
int root, *rbuf, stride;
int *displs, i, *rcounts;
...
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*stride*sizeof(int));
displs = (int *)malloc(gsize*sizeof(int));
rcounts = (int *)malloc(gsize*sizeof(int));
for(i = 0; i < gsize; ++i)
{
displs[i] = i*stride;
rcounts[i] = 100;
}
MPI_Gatherv(sendarray, 100, MPI_INT, rbuf, rcounts, displs, MPI_INT, root, comm);
Программа ошибочна, если –100 < stride < 100.
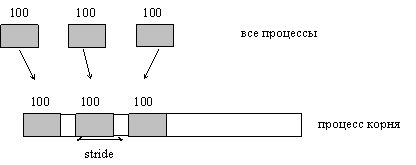
Рис. 4.3 Процесс корня принимает 100 элементов от каждого процесса в группе; каждый набор размещается с шагом stride элементов друг от друга.
ПРИМЕР 4.3.
Тот же самый как пример 1.13 в посылающей стороне, но в получающей стороне делается разный шаг между полученными блоками (рис. .4.4).
MPI_Comm comm;
int gsize,
sendarray[100][150],
*sptr;
int root,
*rbuf,
*stride,
myrank,
bufsize;
MPI_Datatype stype;
int *displs,
i,
*rcounts,
offset;
...
MPI_Comm_size(comm, &gsize);
MPI_Comm_rank(comm, &myrank);
stride = (int *)malloc(gsize*sizeof(int));
...
/* Устанослен stride[i] от i = 0 до gsize-1 */
displs = (int *)malloc(gsize*sizeof(int));
rcounts = (int *)malloc(gsize*sizeof(int));
offset = 0;
for(i = 0; i < gsize; ++i)
{
displs[i] = offset;
offset += stride[i];
rcounts[i] = 100-i;
scounts[i] = 100-myrank;
}
bufsize = displs[gsize-1]+rcounts[gsize-1];
rbuf = (int *)malloc(bufsize*sizeof(int));
sptr = &sendarray[0][myrank];
MPI_Gatherv(sptr, scounts, MPI_INT, rbuf, rcounts, displs, MPI_INT, root, comm);
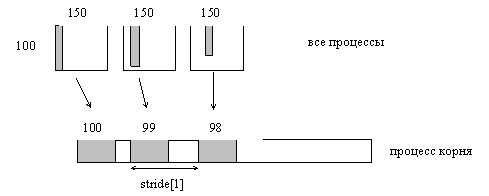
Рис. 4.4. Процесс корня принимает 100-i элементов из колонки i массива 100*150, и каждый набор размещается c изменяющимся шагом stride[1] элементов.
Написание MPI-программы
Инициализация MPI
int MPI_Init( int* argc, char** argv)
Инициализация параллельной части приложения. Реальная инициализация для каждого приложения выполняется не более одного раза, а если MPI уже был инициализирован, то никакие действия не выполняются и происходит немедленный возврат из подпрограммы. Все остальные MPI-процедуры могут быть вызваны только после вызова MPI_Init.
Возвращает: в случае успешного выполнения - MPI_SUCCESS, иначе - код ошибки. (То же самое возвращают и все остальные функции).
Сложный тип аргументов MPI_Init предусмотрен для того, чтобы передавать всем процессам аргументы main: