ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.12.2023
Просмотров: 48
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Жұмыстың орындалу мысалы
Тапсырма. Кездейсоқ іріктеу негізінде Еуропаның, Ресейдің және Қазақстанның Data Scients арасында жүргізілген статистикалық зерттеу нәтижесінде жалпы айлық кірістің (мың АҚШ доллары) құны туралы келесі деректер алынды.
Таблица 1 – Месячный доход Data Scientist-ов стран Европы, России и Казахстана
| 1,806 | 10,53 | 7,54 | 5,347 | 4,601 | 6,115 | 2,189 | 6,992 | 5,479 | 3,829 |
| 4,519 | 3,188 | 4,496 | 7,868 | 5,201 | 7,337 | 7,293 | 4,439 | 2,712 | 3,283 |
| 6,37 | 3,324 | 4,891 | 3,83 | 3,782 | 5,703 | 6,135 | 4,537 | 8,074 | 3,942 |
| 8,025 | 4,685 | 3,749 | 4,582 | 6,58 | 5,43 | 6,252 | 6,928 | 6,508 | 6,377 |
| 7,602 | 3,852 | 5,564 | 4,005 | 3,954 | 4,185 | 4,324 | 0,502 | 5,958 | 4,869 |
Алынған мәліметтерді статистикалық өңдеуді орындау.
Шешуі
- Статистикалық таралу қатарын құрыңыз, алынған қатарды гистограмма арқылы графикалық түрде көрсетіңіз. Бөлу функциясын табыңыз, оның графигін құрыңыз.
Гистограмманы құру үшін Python тілінде бағдарлама кодын жазу керек, бұған дейін Pandas, NumPy, Matplotlib үлкен деректерді өңдеуге арналған негізгі
кітапханаларды импорттаған жөн.
Кітапханалар әртүрлі жолдармен импортталады, соның ішінде: import pandas as pd
import matplotlib.pyplot as plt import numpy as np
Кейін опцияға сәйкес үлгі деректерін импорттау керек. Мұны үш жолмен жасауға болады:
-
Seriesқұруарқылы. -
DataFrameқұруарқылы. -
Файлдан деректерді импорттау арқылы деректер тізімін құру.a Құрумысалы:Series
s = pd.Series( [1, 2, 1, 4, 3, 5, 2, 3, 4, 1]) Кодтың нәтижесі 1-суретке сәйкес көрсетілген:
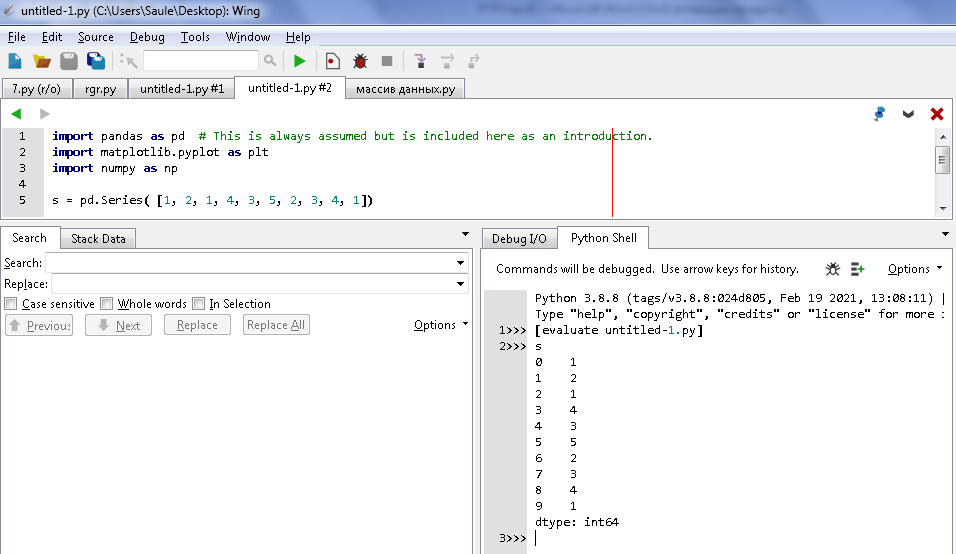
-
сурет - Серияларды құру нәтижесі
-
Құрумысалы:DataFrames
df = pd.DataFrame({'A': [1, 2, 1, 4, 3, 5, 2, 3, 4, 1],
'B': [12, 14, 11, 16, 18, 18, 22, 13, 21, 17], 'C': ['a', 'a', 'b', 'a', 'b', 'c', 'b', 'a', 'b', 'a']})
Кодтың нәтижесі 2-суретке сәйкес көрсетілген:
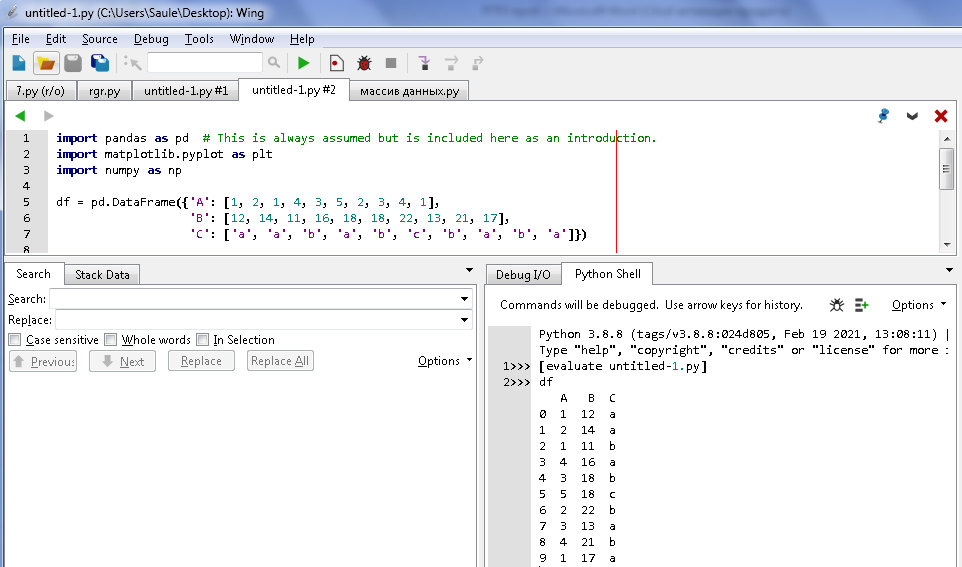
-
сурет – DataFrames құру нәтижесі
-
.csvфайлынандеректердіимпорттауарқылыдеректертізімінжасаумысалы
df.read_csv('file_name.csv’) # relative position
.csv файлынан деректерді импорттау кодының нәтижесі 3-суретке сәйкес көрсетілген
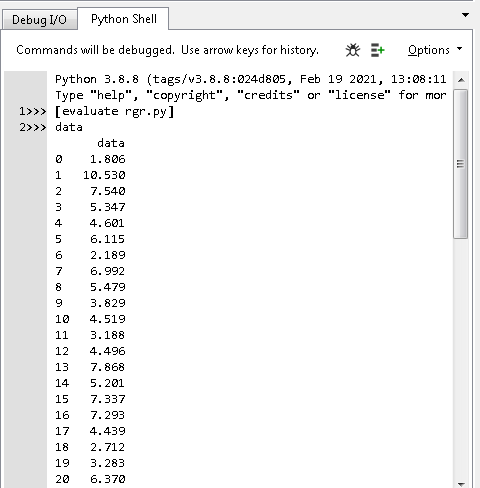
-
сурет - .csv файлынан деректерді импорттау кодының нәтижесі
Гистограмма құру:
Data_name.plot( kind='hist', title=' Қалыпты мәннің таралу гистограммасы ') # hist computes distribution
plt.show()
Гистограмманы салу нәтижесі 4-суретке сәйкес көрсетілген
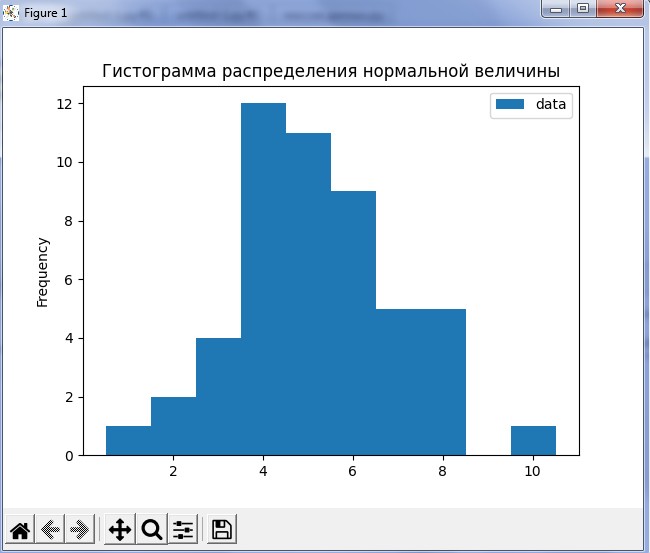
-
сурет – Matplotlib модулі арқылы опцияға сәйкес деректерден
гистограмма салу
-
Табыңыз: таңдаманың орташа мәні, таңдау дисперсиясы, таңдамалы стандартты ауытқу.
Есептеулер үшін математикалық модульді немесе Pandas кірістірілген сипаттама статистикасын пайдалануға болады.
Сандық бағандардың сипаттамалық статистикасын (орташа, стандартты ауытқу, бақылаулар саны, мин, макс және квартилдер) .describe () көмегімен есептеуге болады, ол .describe () пандалардың сипаттама статистикасын береді.
data_name.describe()
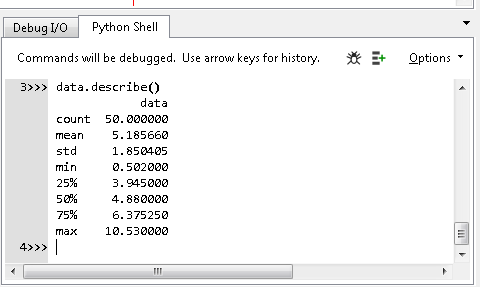 Бағдарлама кодының нәтижесі 5-суретке сәйкес көрсетілген
Бағдарлама кодының нәтижесі 5-суретке сәйкес көрсетілген-
сурет - ".describe ()" қолдану нәтижесі Құрылыс жинақтары. Алдымен екі тізім жасау керек:
-
Интервал мәндерінің тізімі - "ind" -
Жинақталған жиіліктер тізімі (№1 RGR, 4 кестені қараңыз) - "v"
ind = [0.502, 1.935, 3.367, 4.8, 6.232, 7.665, 9.097, 10.530]
v = [0, 0.04, 0.14, 0.48, 0.7, 0.9, 0.98, 1]
Серияны жасау кезінде деректер мәндерін деректер = v және индекс индексі = ind орнату керек. Содан кейін графикті құрастырыңыз.
s = pd.Series( data=v, index=ind )
Көрсетілген индекс мәндері бар Серияларды құру бағдарламасының кодының нәтижесі 6-суретке сәйкес көрсетілген.
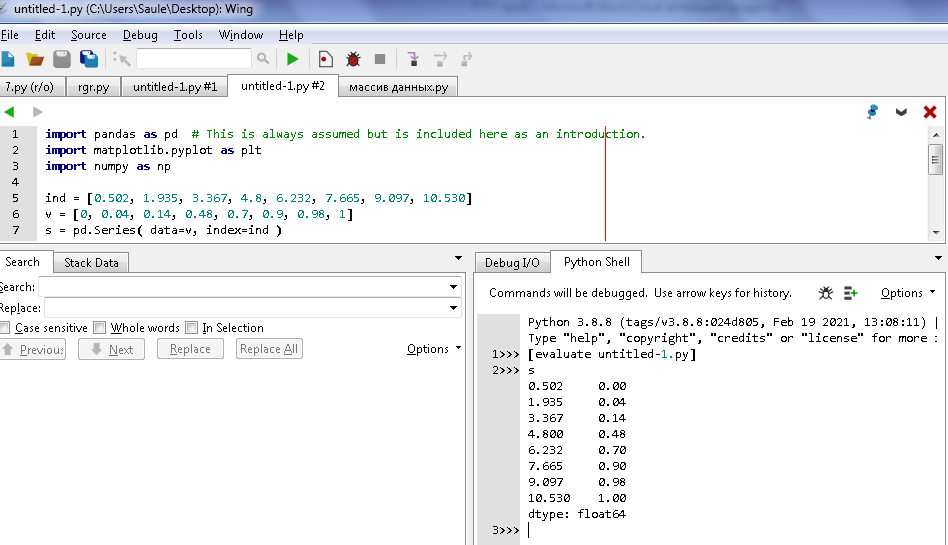
-
сурет – индекстердің берілген мәндері бар Серияларды құру бағдарламасының кодының нәтижесі
Кумуляттардың құрылысы қисық сызықтарды салу арқылы жүзеге асырылады «.plot( )». Кестенің атын беру үшін оны тіркеу керек «title»
s.plot( title='Kumulyata') plt.show()
Қисық бағдарламасы кодының нәтижесі 7-суретке сәйкес көрсетілген
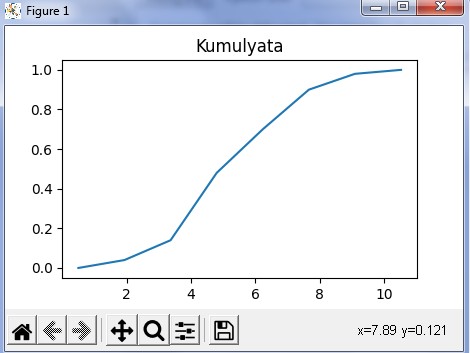
-
сурет – «Кумуляттар» қисығын салуға арналған программа кодының
нәтижесі
Әдебиеттер тізімі
-
Владимир Савельев. Статистика и котики. – Издательские решения, 2016. – С. 160 -
Анналин Ын, Кеннет Су. Теоретический минимум в BIG DATA. Все, что вам нужно знать о больших данных. – Питер, 2019. – С. 208 -
Андреас Вайгенд. BIG DATA. Вся технология в одной книге. – Эксмо, 2018. – С.384 -
Александр Сенько. Работа с BigData в облаках. – Питер, 2018. – С. 448 -
Интернет вещей (IoT). Что это и почему это важно. SAS. https://www.sas.com/ru_ru/insights/big-data/internet-of-things.html -
С.Г.Хан, Л.К. Ибраева Метрология, стандарттау, сертификаттау және сапаны басқару. 5В070200 – Автоматтандыру және басқару мамандығының студенттеріне есептеу-сызба жұмыстарын орындауға әдістемелік нұсқаулықтар
– Алматы: АЭжБУ, 2016.- 43 б.
Дополнительная:
-
Загоруйко Н.Г. Когнитивный анализ данных.Новосибирск: Академическое изд-во «ГЕО». -2012 . -186 с. ISBN 978-5-906284-04-4. -
White, Hadoop: The Definitive Guide. O'Reilly Media, 2012 -
https://www.ck12.org/c/statistics/?referrer=special -
https://towardsdatascience.com/how-to-read-csv-file-using-pandas- ab1f5e7e7b58 -
https://pandas.pydata.org/pandas-docs/stable/getting_started/index.html -
https://www.anaconda.com/products/individual -
https://docs.conda.io/en/latest/miniconda.html -
https://www.codabrainy.com/en/python-compiler/