Файл: Технологии интеллектуального анализа данных или Data mining технологии.docx
Добавлен: 07.12.2023
Просмотров: 72
Скачиваний: 3
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
6. Инструментарий технологии Data Mining
Индустриальные системы
В настоящее время большинство ведущих в мире производителей программного обеспечения предлагает свои продукты и решения в области Data Mining. Как правило - это масштабируемые системы, в которых реализованы различные математические алгоритмы анализа данных. Они имеют развитый графический интерфейс, богатые возможности в визуализации и манипулирования с данными, предоставляют доступ к различным источникам данных, функционирую в архитектуре клиент/сервер на Intel или UNIX платформах. Вот несколько примеров таких систем:
-
PolyAnalyst (Мегапьютер Интеллидженс); -
Intelligent Miner (IBM); -
Interprise Miner (SAS); -
Clementine (Integral Solutions); -
MineSet (Silicon Graphics); -
Knowledge Studio (Angoss Software).
Предметно-ориентированные аналитические системы
Эти системы решают узкий класс специализированных задач. Хорошим примером являются программы технического анализа финансовых рынков:
-
MetaStock (Equis International, USA); -
SuperCharts (Omega Research, USA); -
Candlestick Forecaster (IPTC, USA); -
Wall Street Money (Market Arts, USA).
Статистические пакеты
Это мощные математические системы, предназначенные для статистической обработки данных любой природы. Они включают многочисленные инструменты статистического анализа, имеют развитые графические средства. Примеры систем:
-
SAS (SAS Institute, USA); -
SPSS (SPSS, USA); -
Statgraphics (Statistical Graphics, USA).
Нейроннoсетевые пакеты
Это широкий класс разнообразных систем, представляющих собой иерархические сетевые структуры, в узлах которых находятся так называемые нейроны. Сети тренируются на примерах, и во многих случаях дают хорошие результаты предсказаний. Основным недостатком нейронных сетей являются трудности в интерпретации результатов. Тренированная нейронная сеть представляет собой "умный черный ящик", работу которого невозможно понять и контролировать. Примеры нейронно-сетевых пакетов:
-
BrainMaker (CSS, USA); -
NeuroShell (Ward Systems Group, USA); -
OWL (Hyperlogic, USA).
Пакеты, реализующие алгоритмы "Decision trees"
Этот метод используется только для решения задач классификации. Это является его серьезным ограничением. Результатом работы метода является иерархическая древовидная структура классификационных правил типа "IF...THEN...". Достоинством метода является естественная способность классификации на множество классов. Примеры систем:
-
C5.0 (Rule Quest, Australia); -
SIPINA (University of Lyon, France); -
IDIS (Information Discovery, USA).
7. Важное положение Data Mining - нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные (unexpected) регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). К обществу пришло понимание, что сырые данные (raw data) содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки. То есть уровень знаний может быть поверхностный, неглубокий и скрытый.
8. Специальные приложения
8.1. Медицина
Известно много экспертных систем для постановки медицинских диагнозов. Они построены главным образом на основе правил, описывающих сочетания различных симптомов различных заболеваний. С помощью таких правил узнают не только, чем болен пациент, но и как нужно его лечить. Правила помогают выбирать средства медикаментозного воздействия, определять показания - противопоказания, ориентироваться в лечебных процедурах, создавать условия наиболее эффективного лечения, предсказывать исходы назначенного курса лечения и т. п. Технологии Data Mining позволяют обнаруживать в медицинских данных шаблоны, составляющие основу указанных правил.
8.2. Молекулярная генетика и генная инженерия
Пожалуй, наиболее остро и вместе с тем четко задача обнаружения закономерностей в экспериментальных данных стоит в молекулярной генетике и генной инженерии. Здесь она формулируется как определение так называемых маркеров, под которыми понимают генетические коды, контролирующие те или иные фенотипические признаки живого организма. Такие коды могут содержать сотни, тысячи и более связанных элементов.
На развитие генетических исследований выделяются большие средства. В последнее время в данной области возник особый интерес к применению методов Data Mining. Известно несколько крупных фирм, специализирующихся на применении этих методов для расшифровки генома человека и растений.
8.3. Прикладная химия
Методы Data Mining находят широкое применение в прикладной химии (органической и неорганической). Здесь нередко возникает вопрос о выяснении особенностей химического строения тех или иных соединений, определяющих их свойства. Особенно актуальна такая задача при анализе сложных химических соединений, описание которых включает сотни и тысячи структурных элементов и их связей.
Можно привести еще много примеров различных областей знания, где методы Data Mining играют ведущую роль. Особенность этих областей заключается в их сложной системной организации. Они относятся главным образом к надкибернетическому уровню организации систем [4], закономерности которого не могут быть достаточно точно описаны на языке статистических или иных аналитических математических моделей [5]. Данные в указанных областях неоднородны, гетерогенны, нестационарны и часто отличаются высокой размерностью.
9. Data Mining. Мультидисциплинарная область
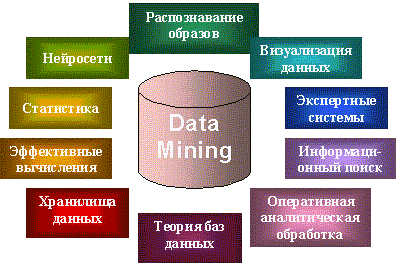
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. (рис. 3). Отсюда обилие методов и алгоритмов, реализованных в различных действующих системах Data Mining. Многие из таких систем интегрируют в себе сразу несколько подходов. Тем не менее, как правило, в каждой системе имеется какая-то ключевая компонента, на которую делается главная ставка. Ниже приводится классификация указанных ключевых компонент на основе работы [6]. Выделенным классам дается краткая характеристика.
10. Класиффикация стадий Data Mining
Data Mining может состоять из двух или трех стадий:
Стадия 1. Выявление закономерностей (свободный поиск).
Стадия 2. Использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование).
В дополнение к этим стадиям иногда вводят стадию валидации [10], следующую за стадией свободного поиска. Цель валидации - проверка достоверности найденных закономерностей. Однако, мы будем считать валидацию частью первой стадии, поскольку в реализации многих методов, в частности, нейронных сетей и деревьев решений, предусмотрено деление общего множества данных на обучающее и проверочное, и последнее позволяет проверять достоверность полученных результатов.
Стадия 3.Анализ исключений - стадия предназначена для выявления и объяснения аномалий, найденных в закономерностях.
Итак, процесс Data Mining может быть представлен рядом таких последовательных стадий:
-свобдный поиск ( в том числе валидация);
-прогностическое моделирование;
-анализ исключений.
10.1.Свободный поиск (Discovery)
На стадии свободного поиска осуществляется исследование набора данных с целью поиска скрытых закономерностей. Предварительные гипотезы относительно вида закономерностей
здесь не определяются.
Закономерность (law) - существенная и постоянно повторяющаяся взаимосвязь, определяющая этапы и формы процесса становления, развития различных явлений или процессов.
Система Data Mining на этой стадии определяет шаблоны, для получения которых в системах OLAP, например, аналитику необходимо обдумывать и создавать множество запросов. Здесь же аналитик освобождается от такой работы - шаблоны ищет за него система. Особенно полезно применение данного подхода в сверхбольших базах данных, где уловить закономерность путем создания запросов достаточно сложно, для этого требуется перепробовать множество разнообразных вариантов.
Свободный поиск представлен такимидействиями:
-
выявлениезакономерностейусловной логики (conditional logic); -
выявлениезакономерностейассоциативной логики (associations and affinities); -
выявление трендов и колебаний (trends and variations).
Допустим, имеется база данных кадрового агентства с данными о профессии, стаже, возрасте и желаемом уровне вознаграждения. В случае самостоятельного задания запросов аналитик может получить приблизительно такие результаты: средний желаемый уровень вознаграждения специалистов в возрасте от 25 до 35 лет равен 1200 условных единиц. В случае свободного поиска система сама ищет закономерности, необходимо лишь задать целевую переменную. В результате поиска закономерностей система сформирует набор логических правил "если ..., то ...".
Могут быть найдены, например, такие закономерности "Если возраст < 20 лет и желаемый уровень вознаграждения > 700 условных единиц, то в 75% случаев соискатель ищет работу программиста" или "Если возраст >35 лет и желаемый уровень вознаграждения > 1200 условных единиц, то в 90% случаев соискатель ищет руководящую работу". Целевой переменной в описанных правилах выступает профессия.
При задании другой целевой переменной, например, возраста, получаем такие правила: "Если соискатель ищет руководящую работу и его стаж > 15 лет, то возраст соискателя > 35 лет в 65 % случаев".
Описанные действия, в рамках стадии свободного поиска, выполняются при помощи :
-
индукции правил условной логики (задачи классификации и кластеризации, описание в компактной форме близких или схожих групп объектов); -
индукции правил ассоциативной логики (задачи ассоциации и последовательности и извлекаемая при их помощи информация); -
определения трендов и колебаний (исходный этап задачи прогнозирования).