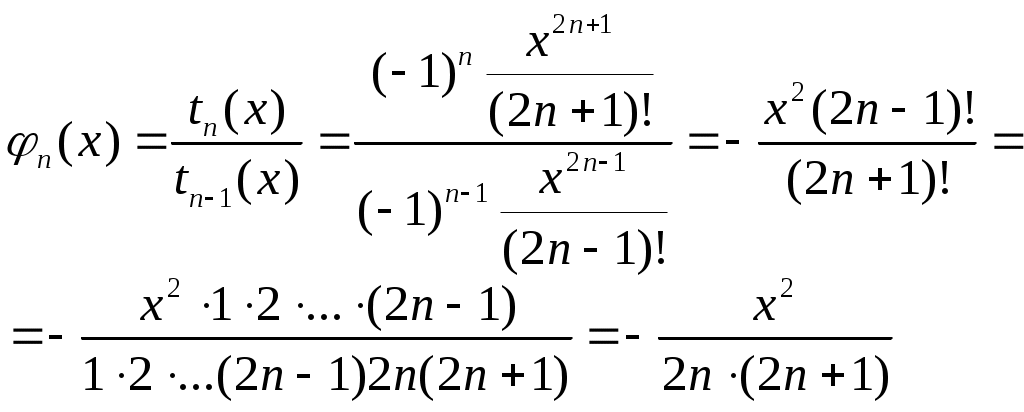Файл: Классификация эвм. Области применения эвм. Обобщенная структура эвм.doc
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.12.2023
Просмотров: 52
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Сетевые
Реляционные
Постреляционные
Объектно-реляционные
Объектно-ориентированные
Многомерные
Прочие (NoSQL)
Рассмотрим реляционную модель данных, в которой данные хранятся в виде двумерных таблиц.
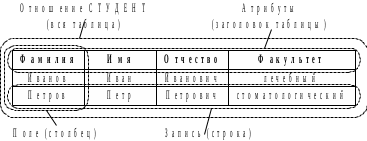
Структура данных реляционной модели данных
Таблицы обладают следующими свойствами:
- каждая ячейка таблицы является одним элементом данных;
- каждый столбец содержит данные одного типа (числа, текст и т. п.);
- каждый столбец имеет уникальное имя;
- таблицы организуются так, чтобы одинаковые строки отсутствовали;
- порядок следования строк и столбцов произвольный.
Каждая таблица представляет собой отношение, описываемое атрибутами:
СТУДЕНТ = (ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО, ФАКУЛЬТЕТ).
Для идентификации записей выделяют следующие виды ключей – полей, определяющих запись:
- первичный: однозначно определяет запись;
- вторичный: выполняет роль поисковых и группировочных признаков и позволяет найти несколько записей.
Ключ может быть простым, если он включает одно поле, или составным, если включает два и более полей. Если в отношении СТУДЕНТ нет однофамильцев, то первичным будет простой ключ – поле ФАМИЛИЯ. Иначе первичным будет составной ключ ФАМИЛИЯ + ИМЯ + ОТЧЕСТВО.
Первичный ключ должен обладать следующими свойствами:
- уникальность: не должно существовать двух или более записей, имеющих одинаковые значения полей, входящих в первичный ключ;
- не избыточность: первичный ключ не должен содержать поля, удаление которых из ключа не нарушит его уникальность.
-
Поразрядные операции И (&), ИЛИ (|), исключающее ИЛИ (^). -
Системы управления базами данных.
Система управления базами данных (СУБД) – приложение, обеспечивающее создание, хранения, обновление и поиск информации в базах данных. СУБД осуществляют взаимодействие между базой данных и пользователями системы, а также между базой данных и прикладными программами, реализующими определенные функции обработки данных.
К основным функциям СУБД относятся:
- непосредственность управления данными во внешней и оперативной памяти;
- поддержание целостности данных и управление транзакциями;
- обеспечение безопасности данных;
- обеспечение параллельного доступа к данным нескольких пользователей.
Состав СУБД:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти;
- процессор языка базы данных, обеспечивающий оптимизацию запросов и создания машинно-независимого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс;
- сервисные программы (внешние утилиты), обеспечивающие дополнительные возможности по обслуживанию информационной системы.
По технологии решения задач, решаемых СУБД, БД подразделяют на два вида:
- централизованная БД хранится целиком на ВЗУ одной вычислительной системы; если система входит в состав сети, то возможен доступ к этой БД других систем;
- распределенная БД состоит из нескольких, иногда пересекающихся или дублирующих друг друга БД, хранящихся на ВЗУ разных узлов сети.
СУБД предоставляет доступ к данным БД двумя способами:
- локальный доступ предполагает, что СУБД обрабатывает БД, которая хранится на ВЗУ той же ЭВМ;
- удаленный доступ – это обращение к БД, которая хранится на одном из узлов сети; удаленный доступ может быть выполнен по технологии файл-сервер или клиент-сервер.
Технология файл-сервер предполагает выделение одной из вычислительных систем, называемой сервером, для хранения БД. Все остальные компьютеры сети (клиенты) исполняют роль рабочих станций, которые копируют требуемую часть централизованной БД в свою память, где и происходит обработка.
Технология клиент-сервер предполагает, что сервер, выделенный для хранения централизованной БД, дополнительно производит обработку запросов клиентских рабочих станций. Клиент посылает запрос серверу. Сервер пересылает клиенту данные, являющиеся результатом поиска в БД по ее запросу.
-
Примеры использования поразрядных операций.
Поразрядные логические операции
К этой группе операций относятся:
· - побитовое отрицание (побитовое НЕ) - унарная операция;
· & - побитовая конъюнкция (побитовое И) - бинарная операция;
· | - побитовая дизъюнкция (побитовое ИЛИ) - бинарная операция;
· ^ - побитовое исключающее ИЛИ - бинарная операция.
Операндами этих операций целочисленных типов данных. Результат также целочисленный.
Операция побитовое отрицание () осуществляет инвертирование всех байтов двоичного представления своего операнда. Например:
int a = 14, r;
r = a;
cout << r << endl; //На экран выведено-15
Иллюстрация:
Номер разряда: 31 30 … 8 7 6 5 4 3 2 1 0
Значение a: 0 0 … 0 0 0 0 0 1 1 1 0 = 14
Значение r = a: 1 1 … 1 1 1 1 1 0 0 0 1 = -15
Остальные операции выполняют соответствующую логическую операцию над каждой парой соответствующих разрядов первого и второго операндов, интерпретируя значения двоичных разрядов как логические значения (1 - true; 0 - false). Например:
int a = 14, b = 7, r;
r = a & b;
cout << r << endl; //На экран выведено6
r = a | b;
cout << r << endl; //На экран выведено15
r = a ^ b;
cout << r << endl; //На экран выведено9
Иллюстрация:
Номер разряда: 31 30 … 8 7 6 5 4 3 2 1 0
Значение a: 0 0 … 0 0 0 0 0 1 1 1 0 = 14
Значение b: 0 0 … 0 0 0 0 0 0 1 1 1 = 7
Операция: a & b
Значение r: 0 0 … 0 0 0 0 0 0 1 1 0 = 6
Операция: a | b
Значение r: 0 0 … 0 0 0 0 0 1 1 1 1 = 15
Операция: a ^ b
Значение r: 0 0 … 0 0 0 0 0 1 0 0 1 = 9
Использование побитовых операций
Как уже говорилось, побитовые операции используются для обработки отдельных двоичных разрядов памяти. Для манипулирования отдельным битом необходимо научиться делать следующее:
· определять значение заданного бита;
· устанавливать значение заданного бита в значение 0 или 1;
· инвертировать значение заданного бита.
Это можно сделать так:
unsigned a = 1234; // Целое значение, битами которого мы будем управлять
unsigned short n = 4;// Номер необходимого бита (от 0 до 31)
bool r; // Значение результата (0 или 1)
/* Узнаем, чему равен n-й бит (двоичный разряд) значения a. Результат поместим в переменную r */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение1
/* Установим n-й бит (двоичный разряд) значения aв0. Результат поместим в переменную а */
a = a & ( (1U << n))
cout << "Значение а равно " << a << endl; //значение1218
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение0
/* Возвращаем n-й бит (двоичный разряд) значения a в 1. Результат поместим в переменную а*/
a = a | (1U << n);
cout << "Значение а равно " << a << endl; //значение1234
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение1
/* Инвертируем n-й бит (двоичный разряд) значения a. Результат поместим в переменную а *
a = a ^ (1U << n);
cout << "Значение а равно " << a << endl; //значение1218
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение0
/* Еще раз инвертируем n-й бит (двоичный разряд) значения a. Результат поместим в переменную а */
a = a ^ (1U << n);
cout << "Значение а равно " << a << endl; //значение1234
/* Проверяем */
r = a & (1U << n);
cout << "Разряд с номером " << n << " равен " << r << endl; //значение1
Изменяя значение переменной n в диапазоне от 0 до 31 можно выполнить все эти действия над любым битом переменной a какое бы значение она не содержала.
Таким образом, для того, чтобы узнать, чему равен двоичный разряд с номером n в значении переменной a, мы воспользовались выражением
a & (1U << n).
Иллюстрация вычисления этого выражения:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
a & (1U << n): 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0 = 16
Результатом вычисления этого выражения является целое значение не равное 0. Операция присваивания этого значения логической переменной r автоматически преобразует целое значение 16 в логическое значение true (т.е. 1).
Если бы значение a имело бы разряд с номером 4 равным 0, то результатом вычисления этого выражения было бы значение 0. При выполнении операции присваивания это значение было бы преобразовано в логическое значение false (т.е. 0).
Для установки значения разряда с номером n в переменной a в значение 0 используется выражение
a & ( (1U << n)).
Иллюстрация вычисления этого выражения:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
(1U << n): 1 1 … 1 1 1 1 1 1 1 0 1 1 1 1
Значение a: 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
a & (1U << n): 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
Для установки значения разряда с номером n в переменной a в значение 1 используется выражение
a | (1U << n).
Иллюстрация вычисления этого выражения:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
a | (1U << n): 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
Для инвертирования значения разряда с номером n в переменной a используется выражение
a ^ (1U << n).
Иллюстрация вычисления этого выражения при a = 1218:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
a ^ (1U << n): 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
Но, если a = 1234, то:
Номер разряда: 31 30 … 11 10 9 8 7 6 5 4 3 2 1 0
1U: 0 0 … 0 0 0 0 0 0 0 0 0 0 0 1 = 1
1U << n: 0 0 … 0 0 0 0 0 0 0 1 0 0 0 0
Значение a: 0 0 … 0 1 0 0 1 1 0 1 0 0 1 0 = 1234
a ^ (1U << n): 0 0 … 0 1 0 0 1 1 0 0 0 0 1 0 = 1218
-
Требования к базам данных. Реляционные модели данных. -
Составление таблиц значений функций. -
Основные функции СУБД.
Система управления базами данных (СУБД) – приложение, обеспечивающее создание, хранения, обновление и поиск информации в базах данных. СУБД осуществляют взаимодействие между базой данных и пользователями системы, а также между базой данных и прикладными программами, реализующими определенные функции обработки данных.
К основным функциям СУБД относятся:
- непосредственность управления данными во внешней и оперативной памяти;
- поддержание целостности данных и управление транзакциями;
- обеспечение безопасности данных;
- обеспечение параллельного доступа к данным нескольких пользователей.
-
Вычисление суммы бесконечного ряда с заданной погрешностью.
Характерным примером итерационных циклов является задача вычисления суммы бесконечного ряда:
где tn(x) – слагаемое, зависящее от параметра x (в общем случае) и номера n. Вычисляемая последовательность
где
Для контроля погрешности можно использовать последовательность
где tn(x) = sn(x) – sn-1(x) – слагаемые ряда n.
Условие выхода из итерационного цикла (справедливо при знакопеременном ряде {tn(x)}):
| tn ( x ) | < .
Алгоритм вычисления бесконечной суммы является модификацией одного из алгоритмов вычисления конечной суммы. Если применение рекуррентных формул нецелесообразно, то вычисления будут наиболее эффективными, если каждое слагаемое определять по общей формуле и полученные значения накапливать в некоторой переменной. Общий вид схемы алгоритма, реализующего вычисление бесконечной суммы с погрешностью с помощью цикла с предусловием, показан на рис. 5.10, а.
Если для вычисления слагаемых используются рекуррентные соотношения
то общая схема итерационного алгоритма для вычисления бесконечной суммы показана на рис. 5.10, б.
Например, тригонометрическая функция sin(x) может быть представлена в виде бесконечной суммы
В данном случае
тогда
Теперь можно определить