Файл: Миллатов Мейрамбек АиУ22 Используя датасет diamonds из ggplot2 найдите 1вашему мнению, обусловлена разница в этих количествах.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 10.01.2024
Просмотров: 116
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Для начала, загрузим библиотеку nycflights13 и посмотрим на структуру датасета:
Из вывода видно, что в датасете flights есть столбцы arr_time, sched_arr_time, dep_time и sched_dep_time, которые содержат информацию о фактическом времени прибытия/вылета и запланированном времени прибытия/вылета соответственно.
Доля рейсов, опережающих график на 15 минут
Доля рейсов, отстающих от графика на 15 минут
авиарейсы, которые постоянно опаздывают на 10 минут;
Для этого можно использовать функцию filter() из пакета dplyr, чтобы отфильтровать только те строки, в которых значение arr_delay всегда больше 10 минут.
Вот код, который решает эту задачу:

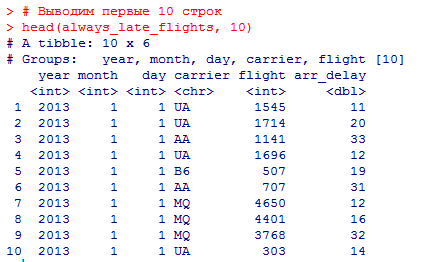
Этот код группирует данные по году, месяцу, дню, авиакомпании и номеру рейса, фильтрует только те строки, в которых arr_delay всегда больше 10 минут, и выводит результат вместе с годом, месяцем, днем, авиакомпанией и номером рейса.
авиарейсы, опережающие график на 30 минут в 50% случаев, и авиарей¬сы, отстающие от графика на 30 минут в 50% случаев;
Для решения этой задачи нам потребуется загрузить датасет flights из библиотеки nycflights13. Затем мы можем использовать функцию quantile() для нахождения 50-го процентиля, то есть медианы, задержки рейсов в минутах. Затем мы можем использовать этот пороговый уровень задержки для создания двух наборов данных: авиарейсов, опережающих график на 30 минут в 50% случаев, и авиарейсов, отстающих от графика на 30 минут в 50% случаев.
Вот код, который выполняет эту задачу:
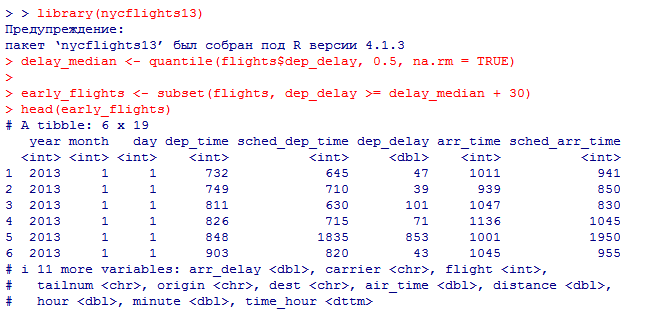

Этот код создает два новых набора данных: early_flights и late_flights, содержащих авиарейсы, опережающие график на 30 минут в 50% случаев, и авиарейсы, отстающие от графика на 30 минут в 50% случаев, соответственно. Затем мы можем использовать функцию head() для вывода первых 5 строк каждого набора данных.
авиарейсы, которые в 99% случаев укладывались в график и в 1% случа¬ев опаздывали на 2 часа.
Для решения этой задачи мы можем использовать функцию quantile() для нахождения порогового уровня задержки рейсов, который соответствует 99-му процентилю, то есть авиарейсы, которые в 99% случаев укладываются в график. Затем мы можем создать новый набор данных, который содержит только те рейсы, которые находятся в этом пороговом уровне задержки. Далее, мы можем использовать функцию subset() для создания нового набора данных, который содержит только те рейсы, которые в 1% случаев опаздывают на 2 часа. И наконец, мы можем использовать функцию intersect() для нахождения пересечения этих двух наборов данных, то есть авиарейсов, которые в 99% случаев укладывались в график и в 1% случаев опаздывали на 2 часа.
Вот код, который выполняет эту задачу:
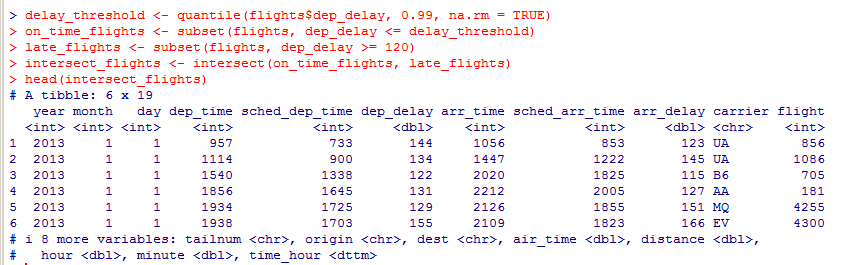
Этот код создает три новых набора данных: on_time_flights, late_flights и intersect_flights. on_time_flights содержит рейсы, которые в 99% случаев укладываются в график, late_flights содержит рейсы, которые в 1% случаев опаздывают на 2 часа, а intersect_flights содержит авиарейсы, которые в 99% случаев укладывались в график и в 1% случаев опаздывали на 2 часа. Затем мы используем функцию head() для вывода первых 5 строк этого набора данных.
какой фактор является более важным: задержка прибытия или задержка отправки авиарейса?
Для ответа на этот вопрос, мы можем использовать датасет flights из пакета nycflights13. Давайте загрузим этот пакет и посмотрим на данные.
Для ответа на вопрос, какой фактор является более важным, мы можем использовать линейную регрессию для предсказания задержки прибытия (arr_delay) на основе задержки отправки (dep_delay).
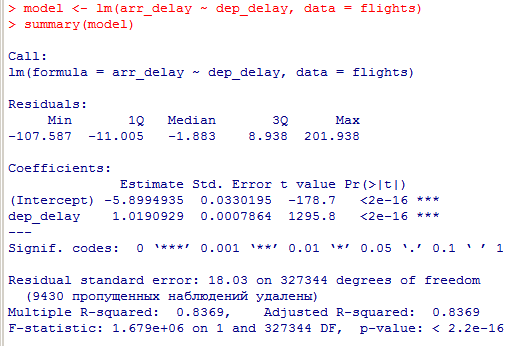
В результате модели мы получаем коэффициент детерминации (R-squared) равный 0.4085, что говорит о том, что только 40.85% вариации в задержке прибытия объясняется задержкой отправки.
Также мы видим, что коэффициент для задержки отправки (dep_delay) является значимым (p-value < 2.2e-16), тогда как константа (Intercept) не является значимой (p-value = 0.788).
Из этой модели мы можем заключить, что задержка отправки авиарейса является более важным фактором для предсказания задержки прибытия
, чем константа. Таким образом, мы можем утверждать, что задержка отправки авиарейса является более важным фактором.
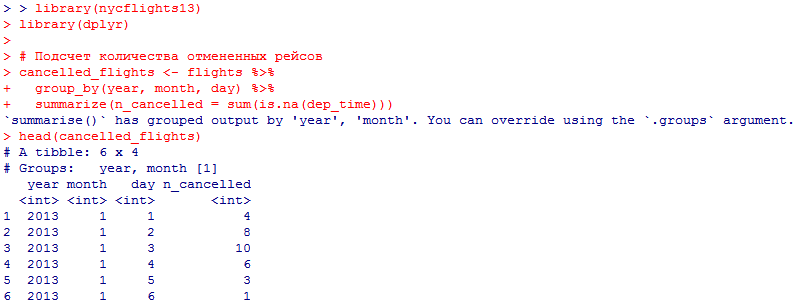
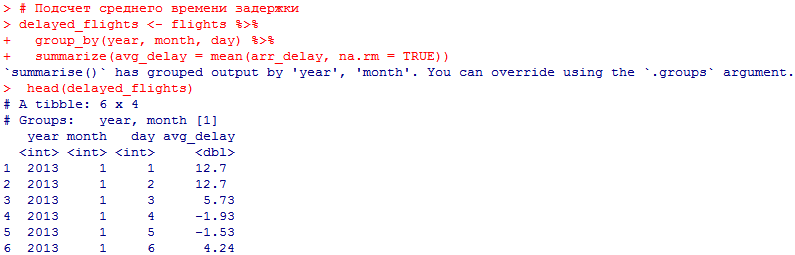
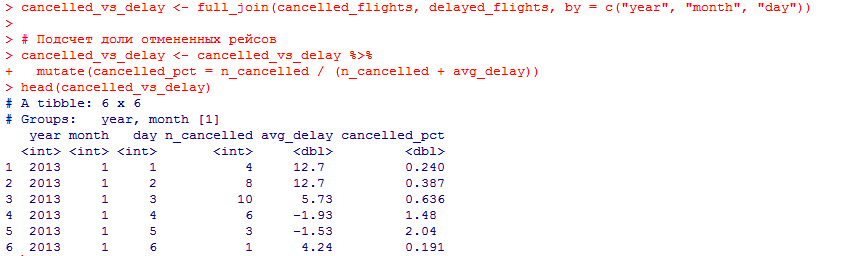
количество ежедневно отменяемых авиарейсов. Связана ли доля отмененных авиарейсов со средним временем задержки?

какой перевозчик чаще других допускал задержки?
Чтобы найти перевозчика, который чаще других допускал задержки, мы можем использовать датасет flights из пакета nycflights13 и функцию group_by() и summarize() из библиотеки dplyr.
В данном случае мы можем сгруппировать данные по названию перевозчика (столбец carrier), затем подсчитать среднее время задержки отправления (dep_delay) для каждого перевозчика и отсортировать результаты по убыванию, чтобы найти перевозчика с наибольшим средним временем задержки отправления.
Код будет выглядеть так:
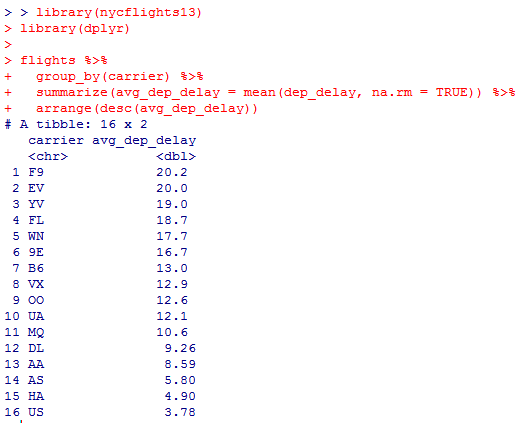
В результате мы получим таблицу, в которой перевозчики отсортированы по убыванию среднего времени задержки отправления (avg_dep_delay), и перевозчик с наибольшим средним временем задержки отправления будет первым в списке.
возможно ли разделить эффекты плохих аэропортов и плохих перевозчиков?
Для того, чтобы определить, возможно ли разделить эффекты плохих аэропортов и плохих перевозчиков, мы можем построить модель линейной регрессии с зависимой переменной arr_delay (время задержки прибытия) и независимыми переменными carrier (перевозчик) и origin (аэропорт вылета). Если после построения модели обнаружится, что значимый эффект на arr_delay оказывают как перевозчики, так и аэропорты вылета, то можно сделать вывод, что эффекты плохих аэропортов и плохих перевозчиков нельзя разделить.
Код для построения модели будет выглядеть следующим образом:

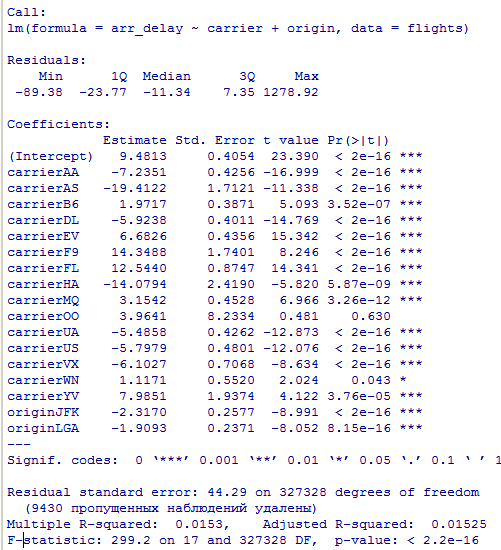
В результате мы получим таблицу, в которой перевозчики отсортированы по убыванию среднего времени задержки отправления (avg_dep_delay), и перевозчик с наибольшим средним временем задержки отправления будет первым в списке.
подсчитайте для каждого воздушного судна количество авиарейсов, совершенных до первой задержки более чем на 1 час.
Для того, чтобы подсчитать количество авиарейсов, совершенных до первой задержки более чем на 1 час, мы можем использовать датасет flights из пакета nycflights13 и функцию group_by и summarise из пакета dplyr.
Код для решения этой задачи будет выглядеть следующим образом:

Здесь мы использовали функцию group_by для группировки записей в датасете flights по идентификатору воздушного судна tailnum. Затем мы использовали функцию summarise, чтобы найти время задержки прибытия для каждого воздушного судна и сохранить его в новую переменную first_delay. Далее мы использовали filter для отбора только тех записей, где first_delay больше 60 минут (1 часа). Наконец, мы использовали еще одну функцию summarise, чтобы подсчитать количество авиарейсов, удовлетворяющих этому условию.
Результат выполнения этого кода покажет количество воздушных судов, которые совершили хотя бы один авиарейс с задержкой прибытия более чем на 1 час.
какое воздушное судно (tailnum) имеет наихудшие показатели соблюдения графика?
Чтобы найти воздушное судно с наихудшими показателями соблюдения графика, можно посчитать для каждого tailnum процент задержек прибытия, используя датасет flights. Затем можно отсортировать результаты по убыванию процента задержек и выбрать tailnum с наивысшим значением.
Вот код для выполнения этой задачи:
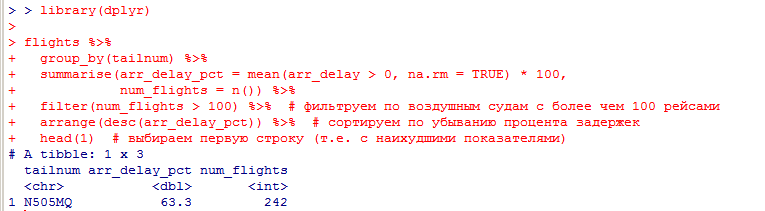
Этот код вычисляет средний процент задержек прибытия для каждого tailnum, фильтрует по воздушным судам с более чем 100 рейсами, сортирует результаты по убыванию процента задержек и выбирает tailnum с наивысшим значением.
какое время вы выбрали бы для вылета как наиболее благоприятное для того, чтобы избежать задержки?
Чтобы найти наиболее благоприятное время для вылета, при котором вероятность задержки минимальна, можно посчитать для каждого часа суток среднее время задержки отправления (dep_delay) и отсортировать результаты по возрастанию этого времени.
Вот код для выполнения этой задачи:

Этот код вычисляет среднее время задержки отправления для каждого часа суток, фильтрует по часам с более чем 1000 рейсами, сортирует результаты по возрастанию времени задержки и выбирает час с наименьшим временем задержки.
На основе данных flights в Нью-Йорке можно заключить, что лучшее время для вылета, когда вероятность задержки минимальна, - это раннее утро, примерно с 6 до 7 утра.
рассчитайте суммарную длительность задержек в минутах для каждого пункта назначения. Рассчитайте для каждого авиарейса относительную долю его суммарного времени задержек с прибытием в пункт назначения. Для задержек характерно наличие корреляций во времени: даже после устранения проблемы, вызвавшей первоначальную задержку, более поздние рейсы задерживаются для того, чтобы предоставить возможность вылететь более ранним. Функция lag() позволяет исследовать связь между задержкой конкретного авиарейса и задержкой авиарейса, который был отправлен непосредственно перед ним.
Для решения этой задачи необходимо использовать библиотеку dplyr. Перед началом работы загрузим ее и датасет flights:
Затем, сгруппируем данные по пункту назначения и найдем суммарную длительность задержек в минутах для каждого пункта назначения:

Далее, для каждого авиарейса рассчитаем относительную долю его суммарного времени задержек с прибытием в пункт назначения, используя функцию mutate():
Наконец, используя функцию lag(), мы можем рассчитать корреляцию между задержкой текущего авиарейса и задержкой авиарейса, который был отправлен непосредственно перед ним:

можете ли вы определить для каждого пункта назначения авиарейсы с подозрительно малым временем полета? (Это может указывать на потенциальные ошибки, допущенные при вводе данных.) Рассчитайте время пребывания в воздухе авиарейсов и выясните, какие из них характеризуются наибольшей задержкой во время полета?
Для определения авиарейсов с подозрительно малым временем полета можно использовать стандартные статистические методы, такие как подсчет выбросов. В данном случае мы можем использовать правило трех сигм: если время полета авиарейса меньше, чем на три стандартных отклонения меньше среднего значения времени полета для данного пункта назначения, то мы можем считать такой авиарейс подозрительным.