ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 19.04.2024
Просмотров: 150
Скачиваний: 0
Нелинейные разветвленные списки Основные понятия
Нелинейным разветвленным списком является список, элементами которого могут быть тоже списки. Если один из указателей каждого элемента списка задает порядок обратный к порядку, устанавливаемому другим указателем, то такой двусвязный список будет линейным. Если же один из указателей задает порядок произвольного вида, не являющийся обратным по отношению к порядку, устанавливаемому другим указателем, то такой список будет нелинейным.
В обработке нелинейный список определяется как любая последовательность атомов и списков (подсписков), где в качестве атома берется любой объект, который при обработке отличается от списка тем, что он структурно неделим.
Если мы заключим списки в круглые скобки, а элементы списков разделим запятыми, то в качестве списков можно рассматривать такие последовательности:
(a,(b,c,d),e,(f,g))
( )
((a))
Первый список содержит четыре элемента: атом a, список (b,c,d) (содержащий в свою очередь атомы b,c,d), атом e и список (f,g), элементами которого являются атомы f и g. Второй список не содержит элементов, тем не менее нулевой список, в соответствии с нашим определением является действительным списком. Третий список состоит из одного элемента: списка (a), который в свою очередь содержит атом а.
Другой способ представления, часто используемый для иллюстрации списков, - графические схемы, аналогичен способу представления, применяемому при изображении линейных списков. Каждый элемент списка обозначается прямоугольником; стрелки или указатели показывают, являются ли прямоугольники элементами одного и того же списка или элементами подсписка. Пример такого представления дан на рисунке.
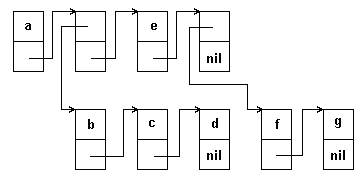
Разветвленные списки описываются тремя характеристиками: порядком, глубиной и длиной.
Порядок. Над элементами списка задано транзитивное отношение, определяемое последовательностью, в которой элементы появляются внутри списка. В списке (x,y,z) атом x предшествует y, а y предшествует z. При этом подразумевается, что x предшествует z. Данный список не эквивалентен списку (y,z,x). При представлении списков графическими схемами порядок определяется горизонтальными стрелками. Горизонтальные стрелки истолковываются следующим образом: элемент из которого исходит стрелка,предшествует элементу, на который она указывает.
Глубина. Это максимальный уровень, приписываемый элементам внутри списка или внутри любого подсписка в списке. Уровень элемента предписывается вложенностью подсписков внутри списка, т.е.числом пар круглых скобок, окаймляющих элемент.. Глубина списка является максимальным значением уровня среди уровней всех атомов списка.
Длина - это число элементов уровня 1 в списке.
Пример применения разветвленного списка - представление последнего алгебраического выражения в виде списка. Алгебраическое выражение можно представить в виде последовательности элементарных двухместных операций вида:
< операнд 1 > < знак операции > < операнд 2 >
Выражение:
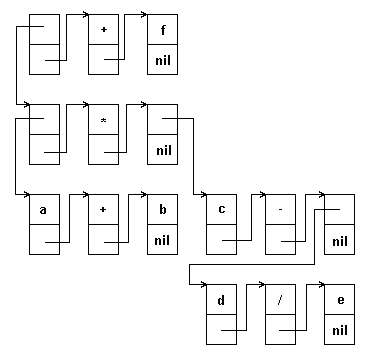
(a+b)*(c-(d/e))+f
будет вычисляться в следующем порядке:
a+b
d/e
c-(d/e)
(a+b)*(c-d/e)
(a+b)*(c-d/e)+f
При представлении выражения в виде разветвленного списка каждая тройка "операнд-знак-операнд" представляется в виде списка, причем, в качестве операндов могут выступать как атомы - переменные или константы, так и подсписки такого же вида. Скобочное представление нашего выражения будет иметь вид:
(((a,+,b),*,(c,-,(d,/,e)),+,f)
Глубина этого списка равна 4, длина - 3.
Представление списковых структур в памяти.
В соответствии со схематичным изображением разветвленных списков типичная структура элемента такого списка в памяти должна быть такой, как показано на рисунке.

Элементы списка могут быть двух видов: атомы - содержащие данные и узлы - содержащие указатели на подсписки. В атомах не используется поле down элемента списка, а в узлах - поле data. Поэтому логичным является совмещение этих двух полей в одно, как показано на рисунке
![]()
Поле type содержат признак атом/узел, оно может быть 1-битовым. Такой формат элемента удобен для списков, атомарная информация которых занимает небольшой объем памяти. В этом случае теряется незначительный объем памяти в элементах списка, для которых не требуется поля data. В более общем случае для атомарной информации необходим относительно большой объем памяти.
![]()
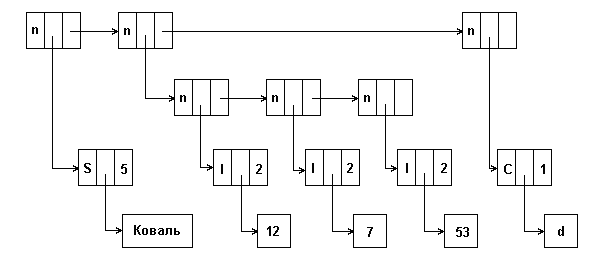
В этом случае указатель down указывает на данные или на подсписок. Поскольку списки могут составляться из данных различных типов, целесообразно адресовать указателем down не непосредственно данные, а их дескриптор, в котором может быть описан тип данных, их длина и т.п. Само описание того, является ли адресуемый указателем данных объект атомом или узлом также может находиться в этом дескрипторе. Удобно сделать размер дескриптора данных таким же, как и элемента списка. В этом случае размер поля type может быть расширен, например, до 1 байта и это поле может индицировать не только атом/подсписок, но и тип атомарных данных, поле next в дескрипторе данных может использоваться для представления еще какой-то описательной информации, например, размера атома. На рисунке показано представление элементами такого формата списка: (КОВАЛЬ,(12,7,53),d). Первая (верхняя) строка на рисунке представляет элементы списка, вторая - элементы подсписка, третья - дескрипторы данных, четвертая - сами данные. В поле type каждого элемента мы использовали коды: n - узел, S - атом, тип STRING, I - атом, тип INTEGER, C - атом, тип CHAR.
. Операции обработки списков
Базовыми операциями при обработке списков являются операции (функции): car, cdr, cons и atom.
Операция car в качестве аргумента получает список (указатель на начало списка). Ее возвращаемым значением является первый элемент этого списка (указатель на первый элемент). Например:
если X - список (2,6,4,7), то car(X) - атом 2;
если X - список ((1,2),6), то car(X) - список (1,2);
если X - атом то car(X) не имеет смысла и в действительности не определено.
Операция cdr в качестве аргумента также получает список. Ее возвращаемым значением является остаток списка - указатель на список после удаления из него первого элемента. Например:
если X - (2,6,4), то cdr(X) - (6,4);
если X - ((1,2),6,5), то cdr(X) - (6,5);
если список X содержит один элемент, то cdr(X) равно nil.
Операция cons имеет два аргумента: указатель на элемент списка и указатель на список. Операция включает аргумент-элемент в начало аргумента-списка и возвращает указатель на получившийся список. Например:
если X - 2, а Y - (6,4,7), то cons(X,Y) - (2,6,4,7);
если X - (1,2), Y - (6,4,7), то cons(X,Y) - ((1,2),6,4,7).
Операция atom выполняет проверку типа элемента списка. Она должна возвращать логическое значение: true - если ее аргумент является атомом или false - если ее аргумент является подсписком.
В программном примере приведена реализация описанных операций как функций языка PASCAL. Структура элемента списка, обрабатываемого функциями этого модуля определена в нем как тип litem и полностью соответствует рисунку .Помимо описанных операций в модуле определены также функции выделения памяти для дескриптора данных - NewAtom и для элемента списка - NewNode. Реализация операций настолько проста, что не требует дополнительных пояснений.
{==== Программный пример ====}
{ Элементарные операции для работы со списками }
Unit ListWork;
Interface
type lpt = ^litem; { указатель на элемент списка }
litem = record
typeflg : char; { Char(0) - узел, иначе - код типа }
down : pointer; { указатель на данные или на подсписок }
next: lpt; { указатель на текущем уровне }
end;
Function NewAtom(d: pointer; t : char) : lpt;
Function NewNode(d: lpt) : lpt;
Function Atom(l : lpt) : boolean;
Function Cdr(l : lpt) : lpt;
Function Car(l : lpt) : lpt;
Function Cons(l1, l : lpt) : lpt;
Function Append(l1,l : lpt) : lpt;
Implementation
{*** создание дескриптора для атома }
Function NewAtom(d: pointer; t : char) : lpt;
var l : lpt;
begin New(l);
l^.typeflg:=t; { тип данных атома }
l^.down:=d; { указатель на данные }
l^.next:=nil; NewAtom:=l;
end;
{*** создание элемента списка для подсписка }
Function NewNode(d: lpt) : lpt;
var l : lpt;
begin
New(l);
l^.typeflg:=Chr(0); { признак подсписка }
l^.down:=d; { указатель на начало подсписка }
l^.next:=nil;
NewNode:=l;
end;
{*** проверка элемента списка: true - атом, false - подсписок }
Function Atom(l : lpt) : boolean;
begin { проверка поля типа }
if l^.typeflg=Chr(0) then Atom:=false
else Atom:=true;
end;
Function Car(l : lpt) : lpt; {выборка 1-го элемента из списка }
begin Car:=l^.down; { выборка - указатель вниз } end;
Function Cdr(l : lpt) : lpt;{исключение 1-го элемента из списка}
begin Cdr:=l^.next; { выборка - указатель вправо } end;
{*** добавление элемента в начало списка }
Function Cons(l1,l : lpt) : lpt;
var l2 : lpt;
begin l2:=NewNode(l1); { элемент списка для добавляемого }
l2^.next:=l; { в начало списка }
Cons:=l2; { возвращается новое начало списка }
end;
{*** добавление элемента в конец списка }
Function Append(l1,l : lpt) : lpt;
var l2, l3 : lpt;
begin
l2:=NewNode(l1); { элемент списка для добавляемого }
{ если список пустой - он будет состоять из одного эл-та }
if l=nil then Append:=l2
else begin { выход на последний эл-т списка }
l3:=l; while l3^.next <> nil do l3:=l3^.next;
l3^.next:=l2; { подключение нового эл-та к последнему }
Append:=l; { функция возвращает тот же указатель }
end; end;
END.
В данном примере в модуль базовых операций включена функция Append - добавления элемента в конец списка. На самом деле эта операция не является базовой, она может быть реализована с использованием описанных базовых операций, без обращения к внутренней структуре элемента списка, хотя, конечно, такая реализация будет менее быстродействующей. В программном примере приведена реализация нескольких простых функций обработки списков, которые могут быть полезными при решении широкого спектра задач. В функциях этого модуля, однако, не используется внутренняя структура элемента списка.
{==== Программный пример ====}
{ Вторичные функции обработки списков }
Unit ListW1;
Interface
uses listwork;
Function Append(x, l : lpt) : lpt;
Function ListRev(l, q : lpt) : lpt;
Function FlatList(l, q : lpt) : lpt;
Function InsList(x, l : lpt; m : integer) : lpt;
Function DelList(l : lpt; m : integer) : lpt;
Function ExchngList(l : lpt; m : integer) : lpt;
Implementation
{*** добавление в конец списка l нового элемента x }
Function Append(x, l : lpt) : lpt;
begin
{ если список пустой - добавить x в начало пустого списка }
if l=nil then Append:=cons(x,l)
{ если список непустой
- взять тот же список без 1-го эл-та - cdr(l);
- добавить в его конец эл-т x;
- добавить в начало 1-й эл-т списка }
else Append:=cons(car(l),Append(x,cdr(l)));
end; { Function Append }
{*** Реверс списка l; список q - результирующий, при первом
вызове он должен быть пустым }
Function ListRev(l, q : lpt) : lpt;
begin
{ если входной список исчерпан, вернуть выходной список }