ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 18.08.2024
Просмотров: 33
Скачиваний: 0
![]() ,
где
,
где
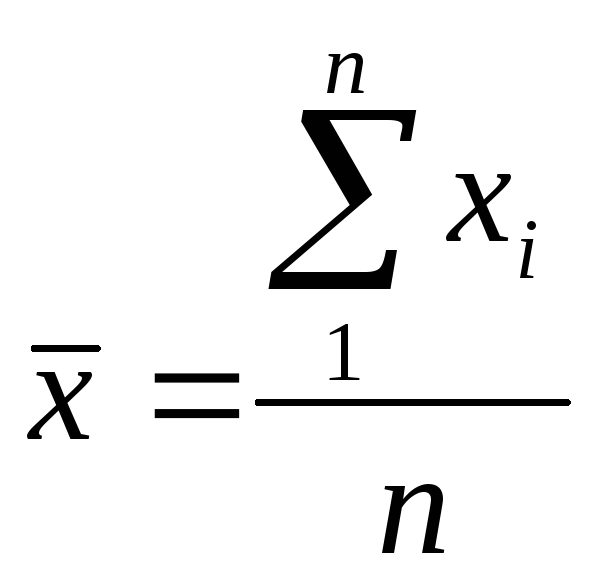 ,
,
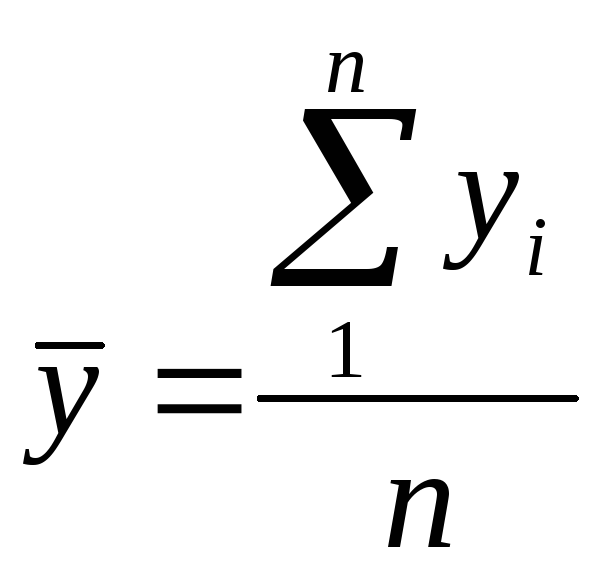 ,
, 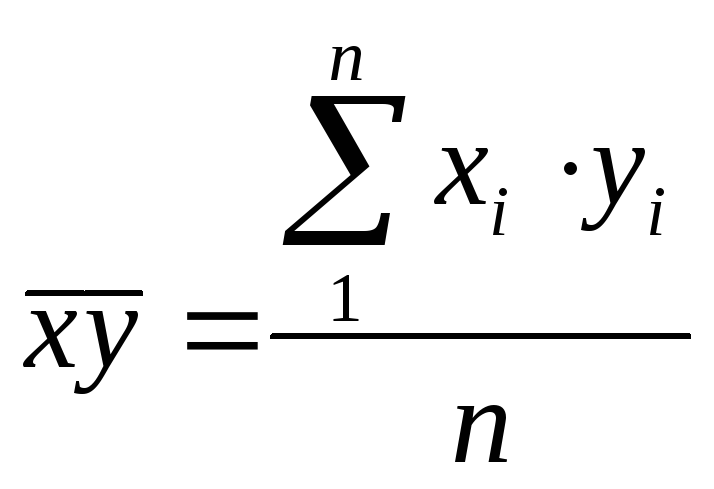 – средние значения,
– средние значения,
![]() .,
.,
![]() – средние квадратичные отклонения,
– средние квадратичные отклонения,
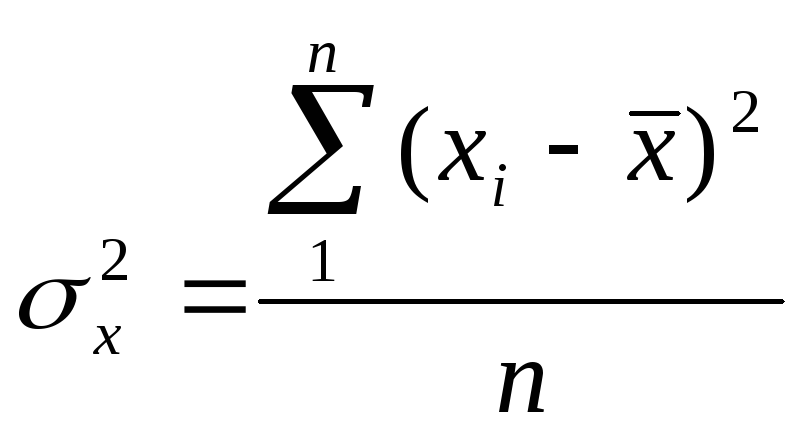 ,
,
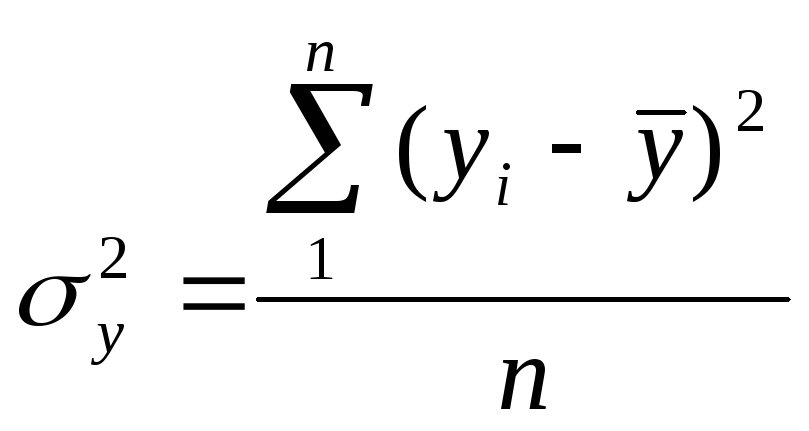 – дисперсия признаков,
– дисперсия признаков,
В таблице приведены качественные оценки степени тесноты связи между переменными Y и X с помощью коэффициента корреляции.
Таблица. Теснота связи и величина коэффициента корреляции
-
Коэффициент корреляции
Теснота связи
± 1
Функциональная связь
от ± 0,91 до ± 1,00
Очень сильная
от± 0,81 до ± 0,90
Весьма сильная
от± 0,65 до ± 0,80
Сильная
от± 0,45 до ± 0,64
Умеренная
от± 0,25 до ± 0,44
Слабая
От 0 до ± 0,25
Очень слабая
0
Связи нет
4. Оценка параметров уравнений регрессии осуществляется методом наименьших квадратов, в основе которого лежит предположение о независимости наблюдений исследуемой совокупности.
Основной принцип метода наименьших квадратов применим для случая, когда две величины (два показателя) X и Y взаимосвязаны между собой, причем Y находится в некоторой зависимости от X. Следовательно, Y будет зависимой, а X - независимой величинами.
Сущность метода
наименьших квадратов заключается в
нахождении параметров модели (а0,
а1).
Неизвестные параметры а0
и
a1
линейного уравнения парной регрессии
выбираются таким образом, чтобы сумма
квадратов
отклонений
эмпирических значений уi
от
расчетных значений
![]() ,
найденных
по уравнению регрессии была минимальной:
,
найденных
по уравнению регрессии была минимальной:
![]()
Рассматриваем S в качестве функции параметров а0, и а1, и проводим математические преобразования (дифференцирование). на основании необходимого условия экстремума функции двух переменных S=S(а0,a1) приравниваем к нулю ее частные производные и получаем:
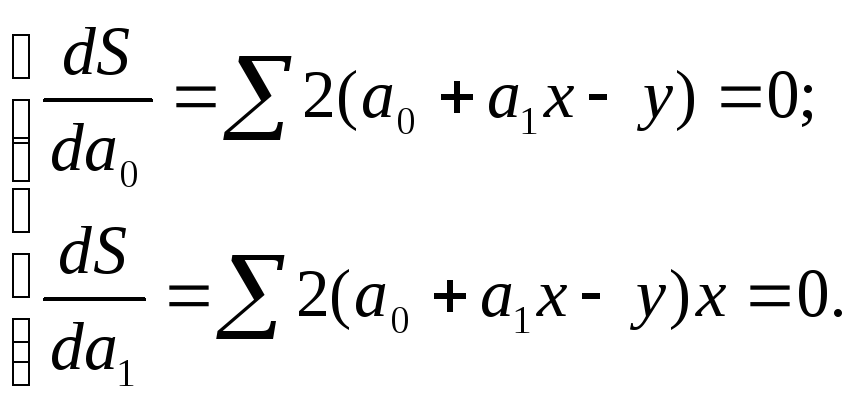
Откуда система нормальных уравнений для нахождения параметров линейной парной регрессии методом наименьших квадратов имеет следующий вид:
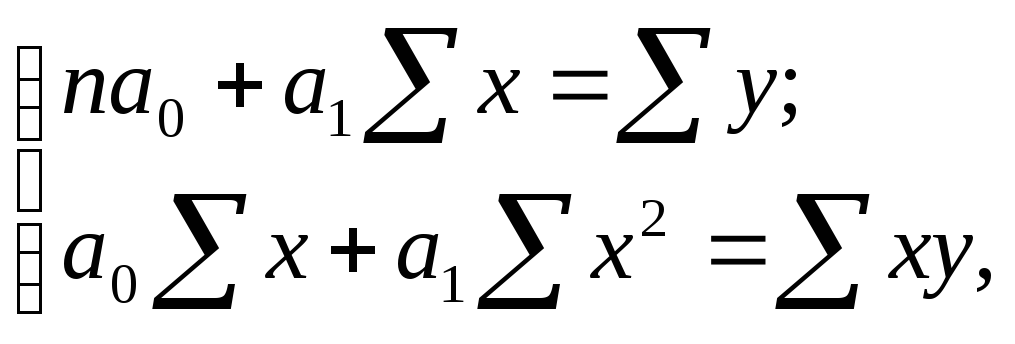
где n- объем исследуемой совокупности (число единиц наблюдений).
Коэффициент а1 называется выборочным коэффициентом регрессии y по x и характеризует влияние, которое оказывает изменение X на Y. Он показывает на сколько единиц в среднем изменяется переменная Y при увеличении переменной X на одну единицу. Если а1 > 0 , то связь – положительная, если а1 < 0, то увеличение Х на единицу влечет за собой уменьшение Y в среднем на а1.
Коэффициент a0 – постоянная величина в уравнении регрессии, которую можно рассматривать как начальное значение Y, если в этом есть экономический смысл.
Решая систему
найдем формулы для расчета коэффициентов
a0
и а1 уравнения
![]() ,
а именно:
,
а именно:
![]() ,
,
![]() .
.
Качество полученной модели оценивается с помощью средней ошибки аппроксимации (приближения), которая показывает среднее отклонение расчетных значений от фактических и определяется по формуле:
![]() , где
, где ![]()
При Ā < 8 –10% качество модели считается весьма хорошим, а допустимый предел составляют значения в 12 – 15%.
При
расчетах
![]() - исходные данные значений y,
а
- исходные данные значений y,
а
![]() - рассчитанные по формуле (т.е. по
полученному уравнению регрессии).
Причем одинаковый индекс указывает на
то, что эти значения соответствуют
одному и тому же значению х и находятся
в одной строке.
- рассчитанные по формуле (т.е. по
полученному уравнению регрессии).
Причем одинаковый индекс указывает на
то, что эти значения соответствуют
одному и тому же значению х и находятся
в одной строке.
Проверка адекватности всей модели производится на основе тестирования статистических гипотез.
Статистической гипотезой называется любое предположение о виде и параметре неизвестного закона распределения.
Проверяемую гипотезу обычно называют нулевой и обозначают H0. Наряду с нулевой гипотезой H0 рассматривают альтернативную, или конкурирующую, гипотезу Н1, являющуюся логическим отрицанием H0. Нулевая и альтернативная гипотезы представляют собой две возможности выбора, осуществляемого в задачах проверки статистических гипотез.
Правило, по которому гипотеза h0 отвергается или принимается, называется статистическим критерием или статистическим тестом.
Проверить значимость уравнения регрессии — значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Проверка значимости уравнения регрессии производится на основе дисперсионного анализа, который применяется как вспомогательное средство для изучения качества регрессионной модели.
На практике F-тест - оценивание качества уравнения регрессии - состоит в проверке гипотезы H0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fфакт определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
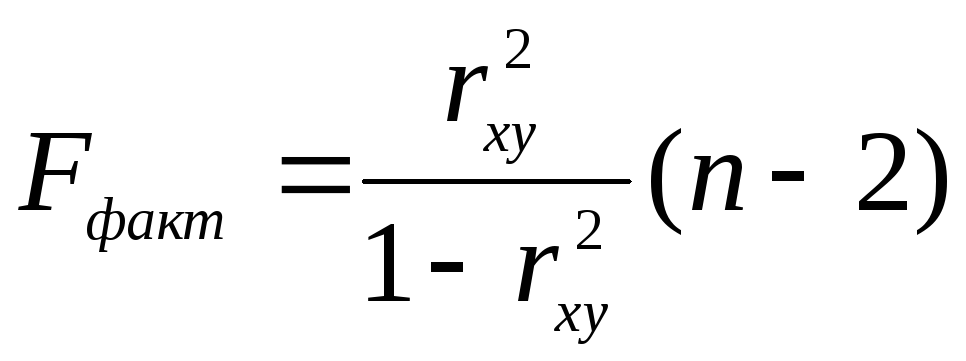
где п - число единиц совокупности; т - число параметров при переменных х.
Fтабл - это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости α. Уровень значимости α - вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно α принимается равной 0,05 или 0,01.
Если Fтабл < Fфакт, то H0 - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если Fтабл > Fфакт, то гипотеза Hо не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
. Для оценки статистической значимости коэффициентов регрессии рассчитываются t-критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Hо о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
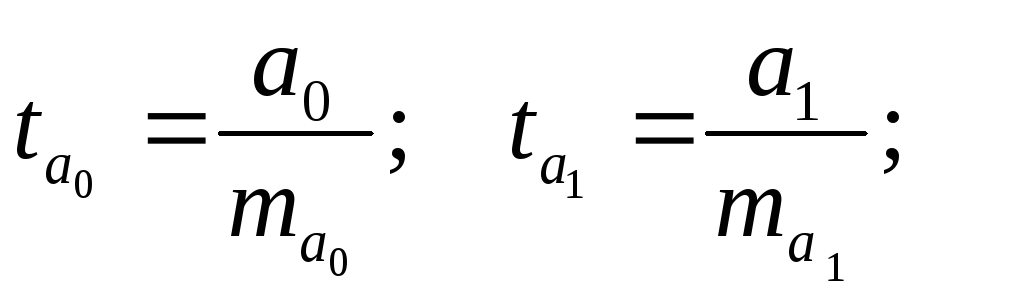
Сравнивая фактическое и критическое (табличное) значения t -статистики - tтабл и tфакт - принимаем или отвергаем гипотезу h0.
Если tтабл < tфакт, то Н0 отклоняется, т.е. a0 , a1 не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если tтабл > tфакт, то гипотеза h0 не отклоняется и признается случайная природа формирования a0 , a1 и rху.
. Одной из наиболее эффективных оценок адекватности регрессионной модели, мерой качества уравнения регрессии, характеристикой прогностической силы анализируемой регрессионной модели является коэффициент детерминации Kd, который показывает измерение степени тесноты статистической связи между у и X.
Для линейных регрессионных связей типа f(X)=a0 +a1x1 +...+ аnхn (где а0,а1,....,аn - числовые параметры) коэффициент детерминации совпадает с квадратом множественного коэффициента корреляции R2y,x,
Чем ближе R2 к единице, тем лучше регрессия аппроксимирует эмпирические данные, тем теснее наблюдения примыкают к линии регрессии. Если R2=1, то эмпирические точки (Xj, yi) лежат на линии регрессии и между переменными Y и X существует линейная функциональная зависимость. Если R2 = 0, то вариация зависимой переменной полностью обусловлена воздействием неучтенных в модели переменных, и линия регрессии параллельна оси абсцисс.
Средний
коэффициент эластичности
![]() показывает,
на сколько процентов в среднем по
совокупности изменится результат у
от
своей средней величины при изменении
фактора х
на
1%
от своего среднего значения:
показывает,
на сколько процентов в среднем по
совокупности изменится результат у
от
своей средней величины при изменении
фактора х
на
1%
от своего среднего значения:
![]()
множественная (многофакторная) регрессия
Изучение связи между тремя и более связанными между собой признаками носит название множественной (многофакторной) регрессии. При исследовании зависимостей методами множественной регрессии задача формулируется так же, как и при использовании парной регрессии, т.е. требуется определить аналитическое выражение связи между результативным признаком (У) и факторными признаками (х,, х2, х3, ... xk), найти функцию: .
![]()