Файл: Мультипроцессоры (Мультипроцессорная когерентность кэш – памяти ).pdf
Добавлен: 04.04.2023
Просмотров: 108
Скачиваний: 1
В данном виде ЭВМ такие кэши могут содержать как общие данные, так и частные. Частные данные представляют собой ячейки памяти, к которым могут обращаться только конкретные процессоры, а общие данные, в свою очередь, доступны для всех, или части, процессоров. Общие данные в подобной архитектуре представляют собой инструмент для взаимодействия между процессорами. Когда происходит кэширование частных данных, они загружаются в кэш для сокращения среднего времени доступа, а также увеличения полосы пропускания. Так как к таким данным имеет доступ только один процесс, то сама операция кэширования частных данных ничем не отличается от подобной операции в однопроцессорных домашних системах. Когда происходит кэширование общих данных, то загружаемое значение может дублироваться сразу в несколько кэшей. Такой подход не только сокращает время доступа к данным, увеличивает полосу пропускания, но также сокращает накладные расходы на взаимодействие между процессорами и передачу данных. Несмотря на все положительные моменты использования кэша могут возникнуть проблемы когерентности, а другими словами целостности, общих данных, хранящихся в отдельных кэшах.
2.1 Мультипроцессорная когерентность кэш – памяти
Проблема целостности общих данных заключается в том факте, что процессоры имеют представление об этих данных только благодаря своему кэшу. Но может возникнуть ситуация, при которой один из процессоров эти данные может изменить. В таком случае, в кэше остальных процессоров будут находиться устаревшие данные, что может привести к некорректному результату расчётов. Данная проблема так же важна, как и описываемая выше проблема синхронизации работы с ячейкой памяти. По своей сути данную проблему так же можно охарактеризовать как проблему синхронизации. И так же, как и прошлая, эта проблема в явном виде скрыта от глаз программиста. На рисунке 3 показан простой пример, иллюстрирующий данную проблему.
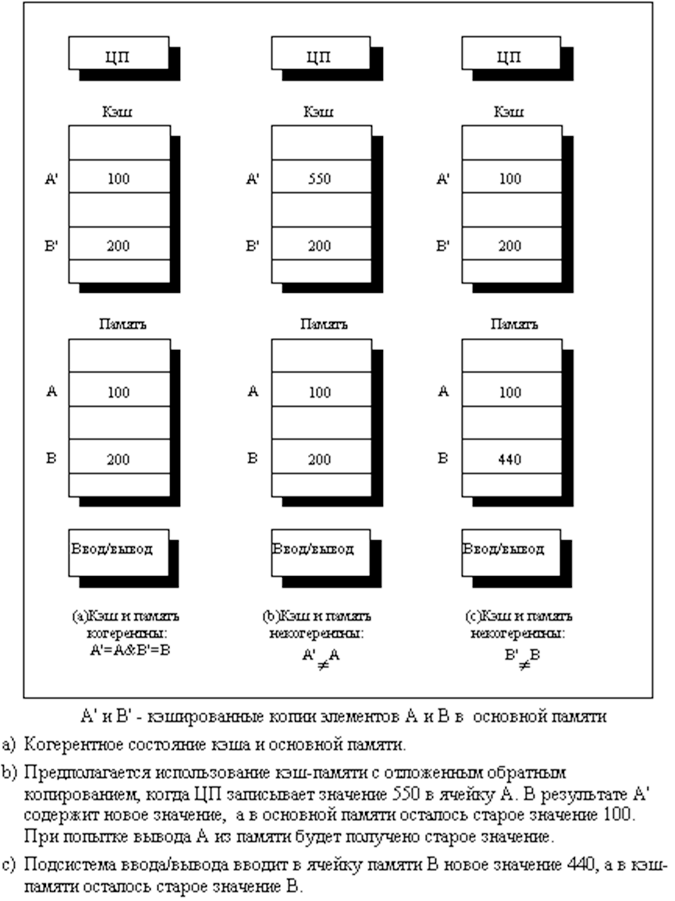
Рис. 3. Иллюстрация проблемы когерентности кэш-памяти
Проблема когерентности памяти для мультипроцессоров, а также для устройств ввода/вывода содержит большое количество аспектов. В небольших мультипроцессорных системах имеется аппаратное решение данной проблемы, называемое протоколом когерентности кэш – памяти. Такие протоколы делятся на два основных типа:
1) Протоколы на основе справочника (directory based). Вся информацию о состоянии физической памяти содержится в одном месте, называемом справочником. В то же время сам справочник физически может находится частично на различных узлах вычислительной системы.
2) Протоколы наблюдения (snooping). Каждый кэш содержит определённое количество ячеек памяти, а также служебную информацию о состоянии этого блока. Централизованно информация обо всей физической памяти нигде не содержится, но все кэши связаны с памятью одной общей шиной и «слушают» её, чтобы не упустить момент, когда какой – либо из процессоров не изменит тот блок общей памяти, который находится в кэше «слушающего» процессора. Это позволяет сохранять информацию в каждом из кэшей актуальной.
В мультипроцессорных системах, использующих ПЭ с кэш – памятью, большое распространение получили протоколы наблюдения. В случае подключения этих процессоров общей шиной не возникает проблем в опросе состояний кэшей, так как инфраструктура для передачи данных уже в системе присутствует в виде той самой общей шины памяти.
Проблема когерентности, простыми словами, заключается в том, что необходимо гарантировать, что в любой момент времени любой процессор, считывая данные из общей памяти, считает актуальные данные, записанные в эту память последними по времени. Такое описание проблемы не совсем корректно, так как нельзя требовать, чтобы операция считывания данных мгновенно видела данные, которые были записаны в эту ячейку другим процессором. Если операция считывания данных из ячейки памяти происходит после операции записи данных в туже самую ячейку памяти, в очень короткий период времени, то невозможно точно сказать, будут ли считанные данные теми данными, которые записывал предыдущий процессор, так как на самом деле, в конкретный момент времени эти данные процессор могли даже не покинуть. Вопрос о том, в какой именно момент данные должны быть доступны для чтения от выбранной модели согласования общей памяти и от реализации синхронизации памяти в параллельных вычислениях. Поэтому при обсуждении данного вопроса обычно принимают что данные, записанные операцией записи должны быть видны для операции чтения, выполняющейся немного позже операции записи и, данные изменяются согласно порядку выполнения операций.
2.2 Результаты исследования
Таблица 1: Результаты работы многопроцессорных систем, обрабатывающих очередь из 100 заданий
|
Кол-во процессоров |
Длина заявки 1-8 |
Длина заявки 3-6 |
||||
|
Сумма длин заявок 487 |
Сумма длин заявок 874 |
|||||
|
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
|
|
2 |
278 |
6,0 |
2,8 |
249 |
2,0 |
2,5 |
|
5 |
113 |
7,3 |
1,1 |
103 |
3,2 |
1,0 |
|
10 |
59 |
5,6 |
0,6 |
54 |
3,3 |
0,4 |
Таблица 2: Результаты работы многопроцессорных систем, обрабатывающих очередь из 1000 заданий
|
Кол-во процессоров |
Длина заявки 1-8 |
Длина заявки 3-6 |
||||
|
Сумма длин заявок 4456 |
Сумма длин заявок 8461 |
|||||
|
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
|
|
2 |
2736 |
6,2 |
2,7 |
2519 |
1,6 |
2,5 |
|
5 |
1098 |
5,5 |
1,1 |
1010 |
3,0 |
1,0 |
|
10 |
554 |
6,0 |
0,6 |
512 |
3,1 |
0,5 |
2.3 Описание процедур, используемых в программе
Глобальные переменные
procc: array [1..10] of integer- массив процессоров системы
c: integer - переменная для подсчета количества простаивавших процессоров;
k: integer - переменная для подсчета общего времени простоя процессоров;
cz: integer - переменная для хранения текущего числа заданий(100 или 1000);
na: integer - переменная для хранения суммы длин заданий;
max: integer - переменная для хранения количества времени , которое проработает система после того, как ей будет передано последнее задание на обработку; Процедуры
Procedure mass (chzad: integer; proc: integer) - процедура, имитирующая работу многопроцессорной системы с общей памятью, выполняет обработку массива, состоящего из cz заданий, в системе с pr процессорами. В качестве параметров получает количество заданий chzad и количество процессоров proc в системе;
s:integer - переменная для подсчета времени, в течении которого будут выполняться chzad заданий;
f:Boolean - переменная для проверки передано ли очередное задание свободному процессору;
procedure vizov - процедура создает массив заданий длинной 1-8 и 3-6 и отправляет его на обработку 2-х, 5-ти и 10-ти процессорной системе при помощи вызова процедуры mass. Процедура вызывается в основной программе для 100 и 1000 заданий отдельно;
pr:integer - переменная для хранения количества процессоров системы;
мультипроцессорный память заявка архитектура.
Заключение
В результате выполнения курсовой работы были получены такие характеристики работы мультипроцессорных систем с общей памятью, как общее время, необходимое для выполнения 100 и 1000 заданий различной длинны, среднее время простоя процессоров и среднее время, необходимое для выполнения одной заявки.
Полученные данные показали прямую зависимость общей производительности системы от количества процессоров, т.е. с ростом числа процессоров в системе растет и общая производительность системы. Как видно из Таблицы 1. для обработки одной и той же очереди заявок общей длинной 487 системе с 2-мя процессорами требуется почти в 2,5 раза больше времени, чем системе с 5-ю процессорами и в 4,7 раза больше, чем системе с 10-тью процессорами.
Как видно из Таблиц 3.1 и 3.2 на производительность многопроцессорной системы с общей памятью влияет и диапазон длин заявок очереди. Для обработки очереди длинной 487, состоящей из 100 заявок, длина которых изменяется от 1 до 8, потребовалось почти столько же времени, сколько и для обработки такой же очереди общей длинной 874(что почти в 2 раза больше предыдущей), заявки которой имеют длину 3-6. Это обусловлено тем, что при обработке первой очереди встречаются как очень короткие (длинной 1-4), так и длинные заявки, на обработку которых требуется больше времени. В связи с этим растет и среднее время простоя процессоров, т.к. некоторые процессоры могли выполнить короткие заявки и завершить работу, в то время как остальные продолжали выполнять длинные заявки. При обработке очереди длинной 3-6 разница в длине заявки составляет 1-2, т.е. процессоры выполняют заявки практически одновременно, таким образом, сокращается время простоя процессоров.
Среднее время выполнения одной заявки так же находится в прямой зависимости от числа процессоров системы. Затраты времени на выполнение одной заявки значительно сокращаются с ростом количества процессоров, как видно из Таблиц 1 и 2 среднее время, необходимое на выполнение одной заявки системе с двумя процессорами, составило 2,6. Системе с пятью процессорами потребовалось примерно 1,1 системного времени, что в 2,4 раза больше, чем первой. Десятипроцессорная система выполняла дону заявку за 0,5, т.е. в 2 раза быстрее, чем предыдущая система.
Таким образом, можно сделать вывод, что производительность многопроцессорной системы зависит, прежде всего, от количества процессоров в системе, а так же от диапазона длин заявок очереди. Полученные результаты показали, что наибольшей производительности система достигает при наличии 10 процессоров и наименьшем диапазоне длин заявок очереди ( в данном случае 3-6).
Непрерывное развитие производства процессорных элементов, и вычислительных систем в целом, заставляют разработчиков программных пакетов для высокопроизводительных вычислений постоянно «держать руку на пульсе» и быть готовыми в достаточно короткие сроки добавлять в свои исходные коды те или иные изменения для использования последних разработок.
Можно выделить несколько сложностей подобных разработок:
1) Малое количество примеров использования новых команд / технологий;
2) Не все задокументированные возможности новой разработки работают исправно;
3) Совместное использование новых и старых подходов не всегда возможно.
Но невозможно не выделить и плюсы активного развития суперкомпьютеров:
1) Повышение сложности решаемых задач;
2) Уменьшение физических размеров вычислительных систем;
3) Уменьшение потребления электропитания (в отдельных случаях);
В ближайшее время резких скачков в развитии высокопроизводительных систем не предвидится. Данный вывод можно сделать, наблюдая за тематиками докладов на международных конференциях, посвящённых суперкомпьютерам.
В целом после написания данной курсовой работы можно сделать следующие выводы:
Достоинства многопроцессорных систем (мультипроцессоров):
1. Производительность (очевидно несколько процессоров выполнят задачу быстрее чем один).
2. Надежность (относится к многопроцессорным системам с общей памятью. При реализации систем с разделенной памятью возникают некоторые проблемы).
3. Живучесть.
4. Устойчивость.
Недостатки мультипроцессоров:
1. ПО (приложения, языки, ОС) сложнее, чем для однопроцессорных ЭВМ.
2. Ограниченность при наращивании (физические размеры - близость к памяти, 64 процессора - максимально достигнуто).
А также то, что у мультипроцессорных систем с общей памятью производительность прямо пропорционально зависит от количества процессоров и быстродействия системы.
Список литературы
1. Беляев А.А. Векторные АЛУ и архитектура SIMD: два уровня параллелизма в архитектуре сигнальных процессоров / А.А. Беляев // Техника и технология. – 2011. - №2.