ВУЗ: Пермская государственная сельскохозяйственная академия имени академика Д. Н. Прянишникова
Категория: Методичка
Дисциплина: Базы данных
Добавлен: 25.10.2018
Просмотров: 1674
Скачиваний: 12
СОДЕРЖАНИЕ
Методическое пособие по контрольной работе
6.4. Использование методологии IDEF1X для разработки концептуальной модели данных
6.5. Пример описания модели данных информационной системы "Контингент студентов университета"
Концептуальная модель базы данных
Некоторые команды и функции для работы с базой данных
Команды для работы с базами данных, таблицами, индексами, связями
Идентификация сущностей. Представление о ключах.
Сущность описывается в диаграмме IDEF1X графическим объектом в виде прямоугольника. На рис.2 приведен пример IDEF1X диаграммы. Каждый прямоугольник, отображающий собой сущность, разделяется горизонтальной линией на часть, в которой расположены ключевые поля и часть, где расположены неключевые поля. Верхняя часть называется ключевой областью, а нижняя часть областью данных. Ключевая область объекта СОТРУДНИК содержит поле «Уникальный идентификатор сотрудника», в области данных находятся поля «Имя сотрудника», «Адрес сотрудника», «Телефон сотрудника» и т. д.
Ключевая область содержит первичный ключ для сущности. Первичный ключ — это набор атрибутов, выбранных для идентификации уникальных экземпляров сущности. Атрибуты первичного ключа располагаются над линией в ключевой области. Как следует из названия, неключевой атрибут — это атрибут, который не был выбран ключевым. Неключевые атрибуты располагаются под чертой, в области данных.
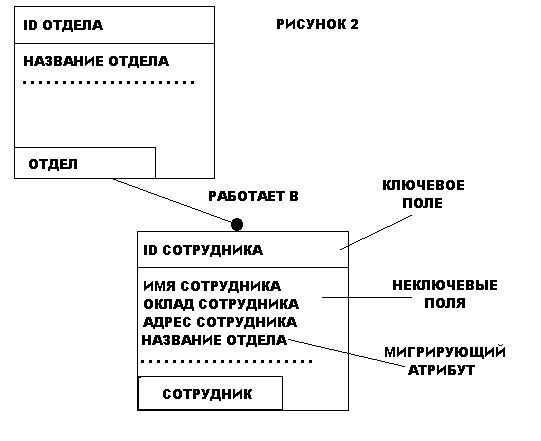
При создании сущности в IDEF1X модели, одним из главных вопросов, на который нужно ответить, является: «Как можно идентифицировать уникальную запись?». Для этого требуется уникальная идентификация каждой записи в сущности для того, чтобы правильно создать логическую модель данных. Напомним, что сущности в IDEF1X всегда имеют ключевую область и, поэтому в каждой сущности должны быть определены ключевые атрибуты.
Выбор первичного ключа для сущности является очень важным шагом, и требует большого внимания. В качестве первичных ключей могут быть использованы несколько атрибутов или групп атрибутов. Атрибуты, которые могут быть выбраны первичными ключами, называются кандидатами в ключевые атрибуты (потенциальные атрибуты). Кандидаты в ключи должны уникально идентифицировать каждую запись сущности. В соответствии с этим, ни одна из частей ключа не может быть NULL, не заполненной или отсутствующей.
Например, для того, чтобы корректно использовать сущность СОТРУДНИК в IDEF1X модели данных (а позже в базе данных), необходимо иметь возможность уникально идентифицировать записи. Правила, по которым вы выбираете первичный ключ из списка предполагаемых ключей, очень строги, однако могут быть применены ко всем типам баз данных и информации. Правила устанавливают, что атрибуты и группы атрибутов должны:
-
Уникальным образом идентифицировать экземпляр сущности.
-
Не использовать NULL значений.
-
Не изменяться со временем. Экземпляр идентифицируется при помощи ключа. При изменении ключа, соответственно меняется экземпляр.
-
Быть как можно более короткими для использования индексирования и получения данных. Если вам нужно использовать ключ, являющийся комбинацией ключей из других сущностей, убедитесь в том, что каждая из частей ключа соответствует правилам.
Для наглядного представления о том, как целесообразно выбирать первичные ключи, приведем следующий пример — выберем первичный ключ для знакомой нам сущности «СОТРУДНИК»:
-
атрибут «ID сотрудника» является потенциальным ключом, так как он уникален для всех экземпляров сущности СОТРУДНИК;
-
атрибут «Имя сотрудника» не очень хорош для потенциального ключа, так как среди служащих на предприятии может быть, к примеру, двое Иванов Петровых;
-
атрибут «Номер страхового полиса сотрудника» является уникальным, но проблема в том, что СОТРУДНИКА может не иметь такового;
-
комбинация атрибутов «имя сотрудника» и «дата рождения сотрудника» может оказаться удачной для наших целей и стать искомым потенциальным ключом.
После проведенного анализа можно назвать два потенциальных ключа — первый «Номер сотрудника» и комбинация, включающая поля «имя сотрудника» и «Дата рождения сотрудника». Так как атрибут «Номер сотрудника» имеет самые короткие и уникальные значения, то он лучше других подходит для первичного ключа.
При выборе первичного ключа для сущности, разработчики модели часто используют дополнительный (суррогатный) ключ, т. е. произвольный номер, который уникальным образом определяет запись в сущности. Атрибут «Номер сотрудника» является примером суррогатного ключа. Суррогатный ключ лучше всего подходит на роль первичного ключа потому, что является коротким и быстрее всего идентифицирует экземпляры в объекте. К тому же суррогатные ключи могут автоматически генерироваться системой так, чтобы нумерация была сплошной, т. е. без пропусков.
Потенциальные ключи, которые не выбраны первичными, могут быть использованы в качестве вторичных или альтернативных ключей. С помощью альтернативных ключей часто отображают различные индексы доступа к данным в конечной реализации реляционной базы.
Если сущности в IDEF1X диаграмме связаны, связь передает ключ (или набор ключевых атрибутов) дочерней сущности. Эти атрибуты называются внешними ключами. Внешние ключи определяются как атрибуты первичных ключей родительского объекта, переданные дочернему объекту через их связь. Передаваемые атрибуты называются мигрирующими.
Классификация сущностей в IDEF1X. Зависимые и независимые сущности
При разработке модели, зачастую, приходится сталкиваться с сущностями, уникальность которых зависит от значений атрибута внешнего ключа. Для этих сущностей (для уникального определения каждой сущности) внешний ключ должен быть частью первичного ключа дочернего объекта.
Дочерняя сущность, уникальность которой зависит от атрибута внешнего ключа, называется зависимой сущностью. В примере на рис. 1 сущность СОТРУДНИК является зависимой сущностью потому, что его идентификация зависит от сущности ОТДЕЛ. В обозначениях IDEF1X зависимые сущности представлены в виде закругленных прямоугольников.

Зависимые сущности далее классифицируются на сущности, которые не могут существовать без родительской сущности и сущности, которые не могут быть идентифицированы без использования ключа родителя (сущности, зависящие от идентификации). Сущность СОТРУДНИК принадлежит ко второму типу зависимых сущностей, так как сотрудники могут существовать и без отдела.
Напротив, существуют ситуации в которых сущность зависит от существования другой сущности. Рассмотрим две сущности: ЗАПРОС, используемый для отслеживания запросов покупателей, и ПОЗИЦИЯ ЗАПРОСА, который отслеживает отдельные элементы в ЗАПРОСе. Связь между этими двумя сущностями может быть выражена в виде ЗАПРОС <содержит> один или несколько ПОЗИЦИЙ ЗАПРОСА. В этом случае, ПОЗИЦИЯ ЗАПРОСА зависит от существования ЗАКАЗА.
Сущности, независящие при идентификации от других объектов в модели, называются независимыми сущностями. В вышеописанном примере сущность ОТДЕЛ можно считать независимой. В IDEF1X независимые сущности представлены в виде прямоугольников.
Типы связей между сущностями.
Идентифицирующие и неидентифицирующие связи
В IDEF1X концепция зависимых и независимых сущностей усиливается типом взаимосвязей между двумя сущностями. Если вы хотите, чтобы внешний ключ передавался в дочернюю сущность (и, в результате, создавал зависимую сущность), то можете создать идентифицирующую связь между родительской и дочерней сущность.
Идентифицирующие взаимосвязи обозначаются сплошной линией между сущностями
Неидентифицирующие связи, являющиеся уникальными для IDEF1X, также связывают родительскую сущность с дочерней. Неидентифицирующие связи используются для отображения другого типа передачи атрибутов внешних ключей — передача в область данных дочерней сущности (под линией).
Неидентифицирующие связи отображаются пунктирной линией между объектами. Так как переданные ключи в неидентифицирующей связи не являются составной частью первичного ключа дочерней сущности, то этот вид связи не проявляется ни в одной идентифицирующей зависимости. В этом случае и ОТДЕЛ, и СОТРУДНИК рассматриваются как независимые сущности.
Тем не менее, взаимосвязь может отражать зависимость существования, если бизнес правило для взаимосвязи определяет то, что внешний ключ не может принимать значение NULL. Если внешний ключ должен существовать, то это означает, что запись в дочерней сущности может существовать только при наличии ассоциированной с ним родительской записи.
Преимущества IDEF1X
Основным преимуществом IDEF1X, по сравнению с другими многочисленными методами разработки реляционных баз данных, такими как ER и ENALIM является жесткая и строгая стандартизация моделирования. Установленные стандарты позволяют избежать различной трактовки построенной модели, которая, несомненно, является значительным недостатком ER.
Приложение 3
Некоторые команды и функции для работы с базой данных
Далее при описании команд приводится их полный синтаксис. Следует помнить, что элементы команд, заключенные в квадратные скобки, являются необязательными, могут присутствовать или отсутствовать. Если элементы разделены вертикальной чертой - должен присутствовать один из них.
Полный список команд и функций с разъяснением их параметров и примерами использования можно найти в справочной системе VFP в разделе Language Reference.
Команды для работы с базами данных, таблицами, индексами, связями
-
Создать базу
CREATE DATABASE [DatabaseName | ?]
-
Создать таблицу базы данных (SQL-команда)
-
CREATE TABLE | DBF TableName1 [NAME LongTableName] [FREE]
-
[CODEPAGE = nCodePage]
-
( FieldName1 FieldType [( nFieldWidth [, nPrecision] )] [NULL | NOT NULL]
-
[CHECK lExpression1 [ERROR cMessageText1]]
-
[AUTOINC [NEXTVALUE NextValue [STEP StepValue]]] [DEFAULT eExpression1]
-
[PRIMARY KEY | UNIQUE [COLLATE cCollateSequence]]
-
[REFERENCES TableName2 [TAG TagName1]] [NOCPTRANS]
-
[, FieldName2... ]
-
[, PRIMARY KEY eExpression2 TAG TagName2 |, UNIQUE eExpression3 TAG TagName3
-
[COLLATE cCollateSequence]]
-
[, FOREIGN KEY eExpression4 TAG TagName4 [NODUP]
-
[COLLATE cCollateSequence]
-
REFERENCES TableName3 [TAG TagName5]] [, CHECK lExpression2 [ERROR cMessageText2]] )
-
| FROM ARRAY ArrayName
-
Открыть базу данных, представление (View) или таблицу базы
-
USE [[DatabaseName!]Table | SQLViewName | ?]
-
[IN nWorkArea | cTableAlias] [ONLINE] [ADMIN] [AGAIN]
-
[NOREQUERY [nDataSessionNumber]] [NODATA] [INDEX IndexFileList | ?
-
[ORDER [nIndexNumber | IDXFileName | [TAG] TagName [OF CDXFileName]
-
[ASCENDING | DESCENDING]]]] [ALIAS cTableAlias] [EXCLUSIVE]
-
[SHARED] [NOUPDATE] [CONNSTRING cConnectionString | (m.nStatementHandle) ]
-
Функция ALIAS([nWorkArea]) возвращает алиас для текущей или заданной рабочей зоны.
-
Выбрать свободную рабочую зону (0), заданную рабочую зону или выбрать таблицу
-
SELECT([ 0 | 1 | cTableAlias ])
-
SELECT(0) - возвращает номер выбранной рабочей зоны
-
SELECT(1) - возвращает наибольший номер свободной зоны
-
SELECT 0 - выбор свободной зоны с наименьшим номером
-
Создать индексный файл
-
INDEX ON eExpression TO IDXFileName | TAG TagName
-
[COLLATE cCollateSequence] [OF CDXFileName] [FOR lExpression]
-
[COMPACT] [ASCENDING | DESCENDING] [UNIQUE | CANDIDATE] [ADDITIVE]
-
[BINARY]
-
Открыть индекс
-
SET INDEX TO [IndexFileList | ? ]
-
ORDER nIndexNumber | IDXIndexFileName |
-
[TAG] TagName [OF CDXFileName] [ASCENDING |
-
DESCENDING]] [ADDITIVE]
-
Установить порядок по индексу
-
SET ORDER TO [nIndexNumber | IDXIndexFileName |
-
[TAG] TagName [OF CDXFileName] [IN nWorkArea |
-
cTableAlias][ASCENDING | DESCENDING]]
-
Установить связь между таблицами
-
SET RELATION TO [eExpression1 INTO nWorkArea1 |
-
cTableAlias1 [, eExpression2 INTO nWorkArea2 |
-
cTableAlias2 ] [IN nWorkArea | cTableAlias]
-
[ADDITIVE]]
-
Установить множественную связь между таблицами (используется при формировании отчетов)
SET SKIP TO [TableAlias1 [, TableAlias2] ...]
Команды перемещения по таблице, поиска и отбора данных
-
Перейти к записи...
-
GO [RECORD] nRecordNumber [IN nWorkArea |
-
IN cTableAlias]
-
GO TOP | BOTTOM [IN nWorkArea | IN cTableAlias]
-
(вместо GO можно использовать GOTO)
-
Переместиться по таблице (вперед или назад)
SKIP [nRecords] [IN nWorkArea | cTableAlias]
Для nRecords>0 - перемещение далее по таблице, для nRecords<0 - назад к предыдущим записям.
Функция BOF() возвращает .T., если текущая запись - первая и Вы пытаетесь выполнить команду SKIP -1, аналогично для последней записи - EOF()=.T.
-
Поиск для заданного логического условия
-
LOCATE [FOR lExpression1] [Scope] [WHILE]
[NOOPTIMIZE]
(Найти следующую запись, соответствующую условию - команда CONTINUE)
-
Поиск по значению индекса
-
SEEK eExpression ORDER nIndexNumber |
-
IDXIndexFileName | [TAG] TagName
-
[OF CDXFileName] [ASCENDING | DESCENDING]]
[IN nWorkArea | cTableAlias]
-
Установить фильтр
-
SET FILTER TO [lExpression]
[IN nWorkArea | cTableAlias]
-
Выполнить запрос (SQL-команда)
-
SELECT [ALL | DISTINCT] [TOP nExpr [PERCENT]] Select_List_Item [, ...]
-
FROM [FORCE] Table_List_Item [, ...]
-
[[JoinType] JOIN DatabaseName!]Table[[AS] Local_Alias]
-
[ON JoinCondition [AND | OR [JoinCondition | FilterCondition] ...]
-
[WITH (BUFFERING = lExpr)]
-
[WHERE JoinCondition | FilterCondition [AND | OR JoinCondition | FilterCondition] ...]
-
[GROUP BY Column_List_Item [, ...]] [HAVING FilterCondition [AND | OR ...]]
-
[UNION [ALL] SELECTCommand]
-
[ORDER BY Order_Item [ASC | DESC] [, ...]]
-
[INTO StorageDestination | TO DisplayDestination]
[PREFERENCE PreferenceName] [NOCONSOLE] [PLAIN] [NOWAIT]
В качестве StorageDestination можно использовать одно из следующих предложений:
-
ARRAY ArrayName - в массив переменных памяти;
-
CURSOR CursorName - в курсор;
-
DBF TableName | TABLE TableName - в таблицу.
В качестве DisplayDestination можно использовать одно из следующих предложений:
-
FILE FileName [ADDITIVE] - ASCII текстовый файл;
-
PRINTER [PROMPT] - вывод на принтер;
-
SCREEN - в главное окно системы VFP.
Команды для добавления, модификации и удаления данных
-
Открыть окно для работы в табличном формате с таблицей базы данных:
-
BROWSE [FIELDS FieldList] [FONT cFontName [, nFontSize]]
-
[STYLE cFontStyle] [FOR lExpression1 [REST]] [FORMAT]
-
[FREEZE FieldName] [KEY eExpression1 [, eExpression2]] [LAST | NOINIT]
-
[LOCK nNumberOfFields] [LPARTITION] [NAME ObjectName] [NOAPPEND]
-
[NOCAPTIONS] [NODELETE] [NOEDIT | NOMODIFY] [NOLGRID] [NORGRID]
-
[NOLINK] [NOMENU] [NOOPTIMIZE] [NOREFRESH] [NORMAL] [NOWAIT]
-
[PARTITION nColumnNumber [LEDIT] [REDIT]]
-
[PREFERENCE PreferenceName] [SAVE] [TIMEOUT nSeconds]
-
[TITLE cTitleText] [VALID [:F] lExpression2 [ERROR cMessageText]]
-
[WHEN lExpression3] [WIDTH nFieldWidth] [WINDOW WindowName1]
[IN [WINDOW] WindowName2 | IN SCREEN] [COLOR SCHEME nSchemeNumber]
При описании полей (в параметре FIELDS) список может содержать следующие параметры:
FieldName (имя поля)
[:R] (только чтение)
[:nColWidth] (ширина поля)
[:V = lExpr1 [:F] [:E = cTxt]] (функция, выполняемая при выходе из поля)
[:P = cFormatCodes] (формат)
[:B = eMin, eMax [:F]] (диапазон данных)
[:H = cHeadingText] (заголовок)
[:W = lExpr2] (функция,выполняемая
перед входом в поле)
Близкий синтаксис имеют команды EDIT и CHANGE для работы с таблицей при построчном расположении полей.
-
Добавление записей
-
APPEND [BLANK] [IN nWorkArea | cTableAlias] [NOMENU]
-
APPEND FROM FileName | ? [FIELDS FieldList]
-
[FOR lExpression][[TYPE] [DELIMITED
-
[WITH Delimiter | WITH BLANK | WITH TAB |
-
WITH CHARACTER Delimiter] | DIF | FW2 | MOD |
-
PDOX | RPD | SDF | SYLK | WK1 |WK3 | WKS | WR1 |
-
WRK | CSV | XLS | XL5 [SHEET cSheetName]| XL8
-
[SHEET cSheetName]]] [AS nCodePage]
-
APPEND FROM ARRAY ArrayName [FOR lExpression] [
-
FIELDS FieldList | FIELDS LIKE Skeleton |
FIELDS EXCEPT Skeleton]
SQL-команда INSERT INTO - добавить запись с заданными значениями полей:
INSERT INTO dbf_name [(FieldName1 [, FieldName2, ...])]
VALUES (eExpression1 [, eExpression2, ...])
INSERT INTO dbf_name FROM ARRAY ArrayName | FROM MEMVAR | FROM NAME ObjectName
INSERT INTO dbf_name [(FieldName1 [, FieldName2, ...])]
SELECT SELECTClauses [UNION UnionClause SELECT SELECTClauses ...]
-
Занести данные в поля таблицы
-
REPLACE FieldName1 WITH eExpression1 [ADDITIVE]
-
[, FieldName2 WITH eExpression2 [ADDITIVE]]
-
...[Scope][FOR lExpression1][WHILE lExpression2]