Добавлен: 29.10.2018
Просмотров: 48172
Скачиваний: 190

626
Глава 8. Многопроцессорные системы
предназначенными только для чтения. Пока все обращения осуществляются только
для чтения, проблем не возникает.
Но если какой-нибудь процесс пытается вести запись в реплицированную страницу,
возникает потенциальная проблема непротиворечивости данных, поскольку изменение
одной копии страницы, не затрагивающее других ее копий, недопустимо. Эта ситу-
ация аналогична той, какая бывает на мультипроцессорах, когда один центральный
процессор пытается изменить слово, присутствующее в нескольких кэшах. Решение
заключается в том, чтобы центральный процессор, собравшийся делать запись, сна-
чала выставлял на шину сигнал, сообщающий другим центральным процессорам
о том, что они должны аннулировать свои копии блока кэша. Система DSM обычно
работает аналогичным образом. Перед записью в совместно используемую страницу
всем остальным центральным процессорам, имеющим эту страницу, отправляется со-
общение о том, чтобы они прекратили отображать эту страницу и аннулировали ее.
Как только все они отрапортуют о прекращении отображения, инициировавший эти
действия центральный процессор может приступить к записи.
Можно также допустить наличие нескольких копий модифицируемых страниц при
строго ограниченных обстоятельствах. Один из способов состоит в том, чтобы по-
зволить процессу получить блокировку части виртуального адресного пространства,
а затем осуществить несколько операций чтения и записи в заблокированной памяти.
Ко времени освобождения блокировки изменения должны быть распространены на
другие копии. Пока в определенный момент времени заблокировать страницу может
только один центральный процессор, эта схема защищает непротиворечивость данных.
Альтернативный вариант предусматривает, что при первой же записи потенциально
модифицируемой страницы создается ее оригинальная копия, которая сохраняется
в памяти центрального процессора, осуществляющего запись. Затем могут произойти
получение блокировки страницы, обновление страницы и освобождение блокировки.
Позже, когда процесс на удаленной машине пытается получить блокировку страницы,
центральный процессор, который ранее делал в нее запись, сравнивает текущее состо-
яние страницы с оригинальной копией и создает сообщение, в котором перечисляются
все измененные слова. Затем этот список отправляется запросившему блокировку
центральному процессору, чтобы он обновил свою копию вместо ее аннулирования
(Keleher et al., 1994).
8.2.6. Планирование мультикомпьютеров
В мультипроцессорах все процессы находятся в одной и той же памяти. Когда цен-
тральный процессор завершает свое текущее задание, он выбирает процесс и запу-
скает его. В принципе, потенциальными кандидатами являются все процессы. На
мультикомпьютере ситуация совершенно иная. У каждого узла есть собственная
память и собственный набор процессов. Центральный процессор 1 не может внезапно
принять решение о запуске процесса на узле 4, не выполнив сначала изрядного коли-
чества работы, чтобы получить этот процесс. Эта разница означает, что планирование
на мультикомпьютерах осуществляется проще, а распределение процессов по узлам
приобретает более важную роль. Эти вопросы и будут рассмотрены далее.
Планирование мультикомпьютерной системы чем-то напоминает планирование муль-
типроцессорных систем, но не все прежние алгоритмы могут быть применены к этому
планированию. Но простейший алгоритм, применяемый на мультипроцессорах, —

8.2. Мультикомпьютеры
627
ведение единого централизованного списка готовых процессов — в данном случае не
работает, потому что каждый процесс может выполняться лишь на том центральном
процессоре, в памяти которого в данный момент он находится. Тем не менее при созда-
нии нового процесса можно выбирать, куда его поместить, для того чтобы, к примеру,
сбалансировать нагрузку.
Поскольку у каждого узла имеются собственные процессы, может быть применен лю-
бой локальный алгоритм планирования. Тем не менее также можно применить такое же
бригадное планирование, как и на мультипроцессорах, поскольку для него требуются
всего лишь начальное соглашение о том, какой процесс в каком кванте времени будет
работать, и тот или иной способ координации начальных моментов квантов времени.
8.2.7. Балансировка нагрузки
О планировании мультикомпьютерных систем можно сказать относительно немного,
потому что как только процесс назначается какому-либо узлу, может использоваться
любой локальный алгоритм планирования, если только не используется бригадное
планирование. Но именно из-за ограниченных возможностей управления ситуацией
после того, как процесс уже будет назначен узлу, приобретает особую важность решение
о том, какой процесс какому узлу будет распределен. Это не похоже на мультипроцес-
сор, где все процессы находятся в одном и том же пространстве памяти и их работа
может планироваться на каком угодно центральном процессоре. Поэтому стоит рас-
смотреть, как процессы могут быть назначены узлам наиболее эффективным образом.
Алгоритмы и эвристические правила для осуществления этих назначений известны
как алгоритмы распределения процессоров (processor allocation algorithms).
С годами было предложено большое количество алгоритмов распределения процес-
соров (то есть узлов). Они различаются предположениями об известных исходных
данных и поставленными целями. К свойствам процесса, о которых должно быть из-
вестно, относятся требования к центральному процессору, объем необходимой памяти
и объем обмена данными с каждым из всех остальных процессов. Возможные цели
включают в себя сведение к минимуму холостых тактов центрального процессора из-
за отсутствия локальной нагрузки, сведение к минимуму суммарного объема обмена
данными и гарантирование справедливого распределения ресурсов между пользова-
телями и процессами. Далее будут рассмотрены некоторые алгоритмы, позволяющие
получить представление об имеющихся возможностях.
Детерминированный графовый алгоритм
Для систем, состоящих из процессов с хорошо известными требованиями к централь-
ным процессорам и памяти и известной матрицей, дающей средний объем обмена дан-
ными между каждой парой процессов, имеется хорошо изученный класс алгоритмов.
Если количество процессов превышает количество центральных процессоров k, то
каждому процессору должно быть назначено несколько процессов. Замысел заключа-
ется в том, чтобы назначения сводили к минимуму сетевой трафик.
Система может быть представлена в виде взвешенного графа, где каждая вершина
является процессом, а каждая дуга представляет собой поток сообщений между двумя
процессами. Тогда математически проблема сводится к поиску способа разбиения (то
есть разрезания) графа на k непересекающихся подграфов, отвечающих определенным
ограничениям (например, суммарные требования к центральному процессору и памя-
628
Глава 8. Многопроцессорные системы
ти для каждого подграфа не должны превышать определенный предел). Для каждого
решения, удовлетворяющего ограничениям, дуги, целиком находящиеся внутри от-
дельного подграфа, представляют собой внутримашинную передачу данных и могут
быть проигнорированы. Дуги, переходящие из одного подграфа в другой, представляют
собой сетевой трафик. Цель заключается в том, чтобы найти такой вариант разбиения,
который сводил бы к минимуму сетевой трафик и при этом отвечал всем ограничениям.
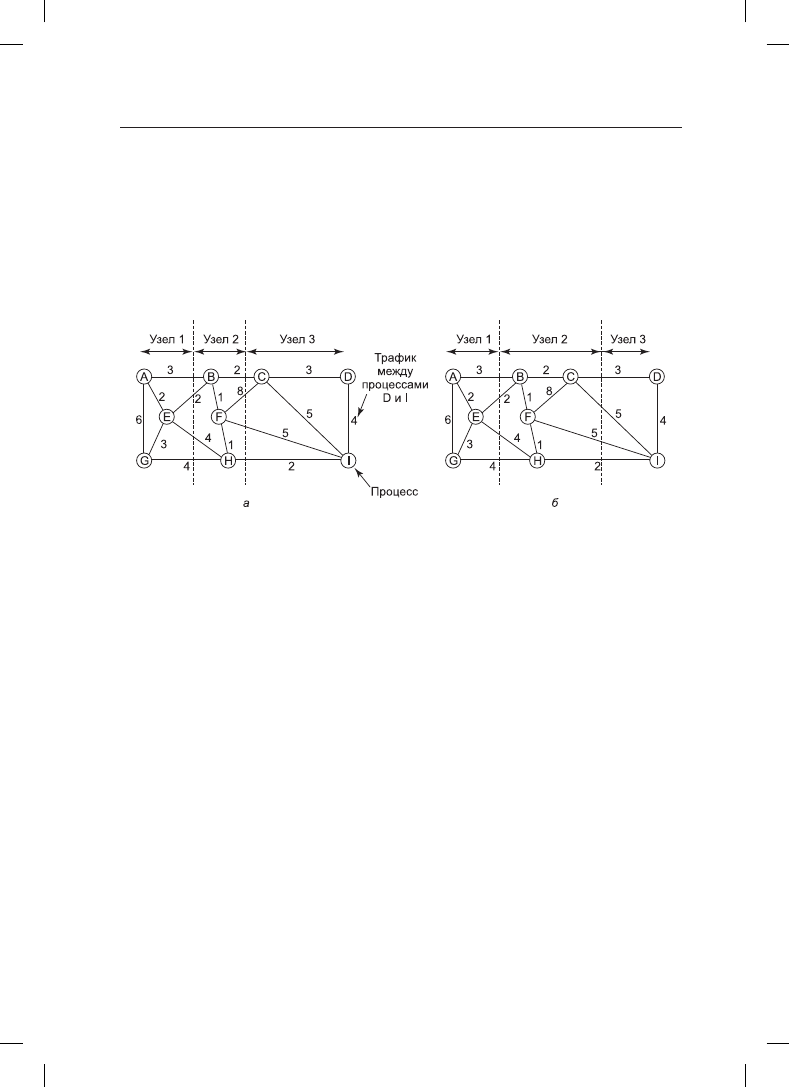
Для примера на рис. 8.24 показана система из девяти процессов от A до I, где каждая
дуга подписана значением нагрузки по передаче данных между двумя процессами (на-
пример, в мегабитах в секунду).
Рис. 8.24. Два способа распределения девяти процессов по трем узлам
На рис. 8.24, а граф разбит таким образом, что процессы A, E и G отнесены к узлу 1,
процессы B, F и H — к узлу 2, а процессы C, D и I — к узлу 3. Суммарный сетевой тра-
фик получается путем сложения трафика всех дуг, разрезанных при разбиении (пре-
рывистыми прямыми), и равен 30. На рис. 8.24, б показан другой вариант разбиения,
при котором сетевой трафик равен 28. Если предположить, что этот вариант отвечает
всем ограничениям по ресурсам центрального процессора и памяти, он является более
предпочтительным, поскольку требует меньшего объема передачи данных.
Интуитивно мы занимаемся поиском кластеров, тесно связанных друг с другом (у ко-
торых широкие потоки внутрикластерного обмена данными), но слабо взаимодей-
ствующих с другими кластерами (имеющих узкие потоки межкластерного обмена
данными). Самые первые статьи с обсуждениями этой проблемы были написаны Чоу
и Абрахамом, Ло, а также Стоуном и Бокхари (Chow and Abraham, 1982; Lo, 1984; Stone
and Bokhari, 1978).
Распределенный эвристический алгоритм,
инициируемый отправителем
Теперь рассмотрим некоторые распределенные алгоритмы. Один из них гласит, что
при создании процесс запускается на узле, который его создал, если тот не перегружен.
Перегрузка может оцениваться по числу процессов, их суммарной нагрузке на процес-
сор или какому-нибудь другому параметру. Если узел перегружен, он произвольным
образом выбирает другой узел и запрашивает у него данные о его загрузке (используя
ту же систему оценки). Если загрузка проверяемого узла оказывается ниже опреде-
ленного порогового значения, новый процесс отправляется на этот узел (Eager et al.,
8.2. Мультикомпьютеры
629
1986). Если проверяемый узел не отвечает этому требованию, для проверки выбира-
ется другая машина. Проверка не ведется до бесконечности. Если за N проверок найти
подходящий узел не удается, алгоритм завершает свою работу и процесс запускается
на породившей его машине. Замысел заключается в том, чтобы сильно загруженные
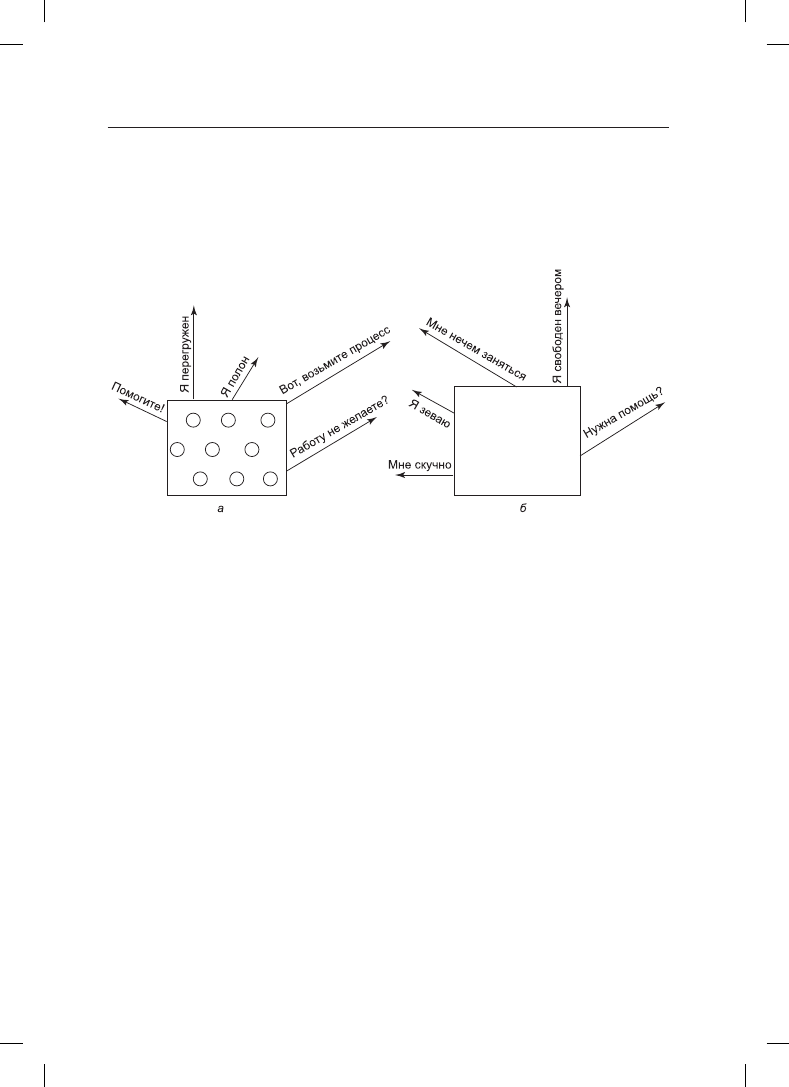
узлы пытались избавиться от чрезмерной работы, как показано на рис. 8.25, а, где изо-
бражено выравнивание нагрузки, инициированное отправителем.
Рис. 8.25. а — перегруженный узел ищет недогруженный узел, которому можно
было бы передать процесс; б — незагруженный узел ищет, чем бы заняться
Для данного алгоритма была создана аналитическая модель очередей (Eager et al.,
1986). При использовании этой модели было установлено, что алгоритм неплохо себя
ведет и работает стабильно в широком диапазоне параметров, включая различные
пороговые значения, затраты на перенос данных и ограничения по количеству проб.
Тем не менее следует заметить, что в условиях большой загруженности все машины
будут постоянно отправлять тестовые сообщения другим машинам, тщетно пытаясь
найти машину, желающую получить дополнительную работу. При этом машины изба-
вятся лишь от весьма незначительного количества процессов, но попытки избавления
приведут к значительным издержкам.
Распределенный эвристический алгоритм,
инициируемый получателем
На рис. 8.25, б показано, что в дополнение к вышеописанному алгоритму, инициируе-
мому перегруженным отправителем, существует еще один алгоритм, инициируемый
недогруженным получателем. Согласно этому алгоритму, когда процесс завершает свою
работу, система проверяет, достаточно ли у нее работы. Если нет, она произвольным
образом выбирает какую-нибудь машину и просит у нее работу. Если этой машине
нечего предложить, опрашивается вторая, а затем третья машина. Если за N попыток
работа так и не будет найдена, узел временно прекращает опрос, проделывает свою
очередную работу и повторяет попытку при завершении следующего процесса. Если
доступная работа отсутствует, машина простаивает. После некоторого определенного
интервала времени она опять возобновляет поиск работы.

630
Глава 8. Многопроцессорные системы
Преимущество этого алгоритма в том, что он не создает дополнительной нагрузки на
систему в критические периоды. Алгоритм, инициируемый отправителем, проводит
массу исследований именно тогда, когда они меньше всего допустимы для системы —
в момент ее максимальной загруженности. При использовании алгоритма, иниции-
руемого получателем, шанс найти недогруженную машину довольно низок. Но если
это и произойдет, то будет нетрудно найти работу, которую можно будет взять на себя.
Разумеется, когда предстоящей работы мало, алгоритм, инициируемый получателем,
создает большой объем тестирующего трафика, поскольку все незанятые машины от-
чаянно охотятся за работой. Но все-таки намного лучше нести издержки, когда система
недогружена, чем когда она перегружена.
Можно также объединить оба этих алгоритма и иметь машины, пытающиеся избавить-
ся от работы, когда ее слишком много, и машины, пытающиеся заполучить работу, когда
ее у них слишком мало. Более того, машины могут усовершенствовать произвольный
опрос за счет ведения истории прошлых тестирований, чтобы определить наличие
хронически недогруженных или перегруженных машин. Одна из таких машин может
быть протестирована первой в зависимости от того, что пытается сделать инициатор —
избавиться от работы или заполучить ее.
8.4. Распределенные системы
После знакомства с многоядерными системами, мультипроцессорами и мульти-
компьютерами настал черед рассмотреть последний тип многопроцессорных систем —
распределенные системы
. Они похожи на мультикомпьютеры тем, что у каждого узла
есть собственная закрытая оперативная память и в системе нет общей физической
памяти. Но узлы у распределенных систем имеют еще более слабую связь, чем у муль-
тикомпьютеров.
Начнем с того, что каждый узел мультикомпьютера имеет центральный процессор,
оперативную память, сетевой интерфейс и, возможно, жесткий диск для страничной
организации памяти. В отличие от этого каждый узел в распределенной системе пред-
ставляет собой полноценный компьютер с полным набором периферийных устройств.
Узлы мультикомпьютера обычно находятся в одном помещении, поэтому они могут
вести обмен данными по специальной высокоскоростной сети, а узлы распределенной
системы могут быть разбросаны по всему миру. И наконец, все узлы мультикомпьютера
работают под управлением одной и той же операционной системы, совместно исполь-
зуя единую файловую систему и находясь под общим администрированием, а каждый
узел распределенной системы может работать под управлением другой операционной
системы, у каждого из них имеется собственная файловая система, и каждый из них
администрируется отдельно. Типичный мультикомпьютер состоит из 1024 узлов, нахо-
дящихся в одном помещении, на нем работает какая-нибудь компания или университет,
занимаясь, скажем, фармацевтическим моделированием, а типичная распределенная
система состоит из нескольких тысяч машин, слабо связанных друг с другом через
Интернет. В табл. 8.1 приводится сравнение мультипроцессоров, мультикомпьютеров
и распределенных систем по обозначенным ранее пунктам.
По данным показателям мультикомпьютеры находятся где-то в середине. Возникает
вопрос: на что больше похожи мультикомпьютеры — на мультипроцессоры или на рас-
пределенные системы? Как ни странно, ответ сильно зависит от выбранной вами точки