Добавлен: 29.10.2018
Просмотров: 48177
Скачиваний: 190
616
Глава 8. Многопроцессорные системы
Возникает вопрос о том, как осуществляется адресация. Поскольку мультикомпьютер
находится в статичном состоянии с фиксированным количеством центральных процес-
соров, проще всего справиться с адресацией, поместив в addr адрес, состоящий из двух
частей: номера центрального процессора и процесса или номера порта на адресуемом
центральном процессоре. Таким образом, каждый центральный процессор может без
возникновения конфликтов управлять своими собственными адресами.
Сравнение блокирующих и неблокирующих вызовов
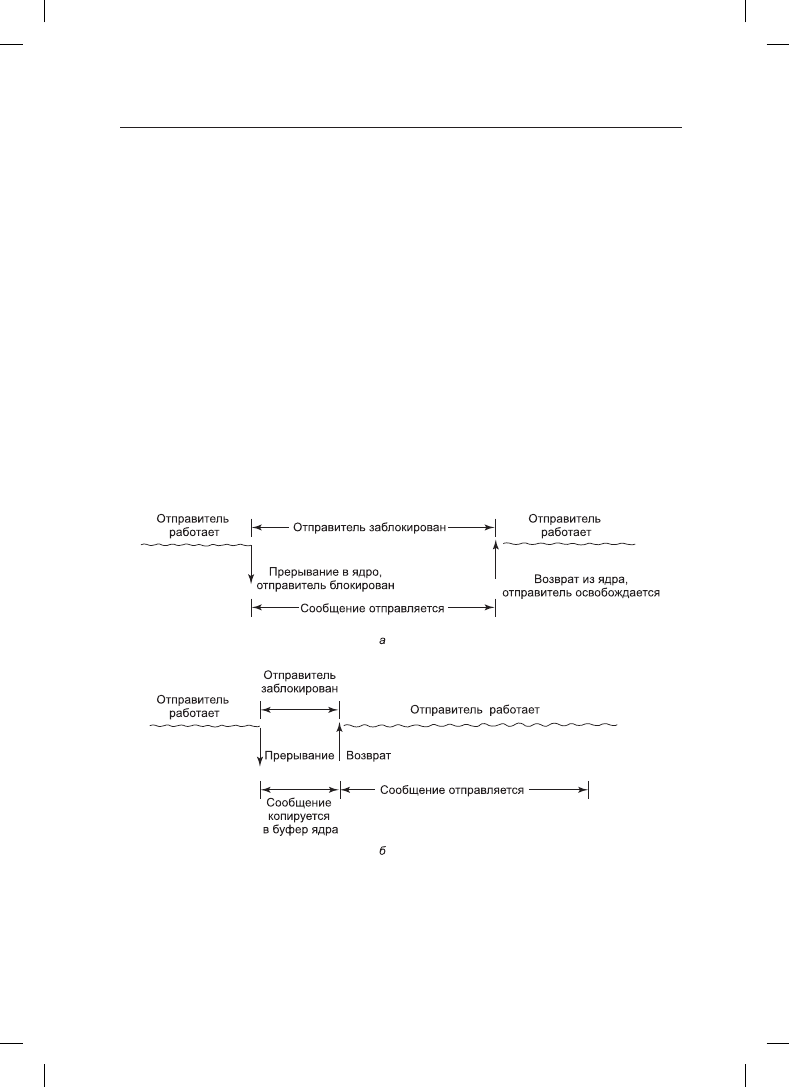
Описанные ранее вызовы являются блокирующими вызовами (иногда их называют
синхронными вызовами
). Когда процесс вызывает процедуру send, он указывает по-
лучателя и отправляемый ему буфер. Пока сообщение отправляется, отправляющий
процесс блокируется (то есть приостанавливается). Команда, следующая за вызовом
процедуры send, не выполняется до тех пор, пока не будет отправлено все сообщение
(рис. 8.19, а). Точно так же после вызова процедуры receive управление процессу не
возвращается до тех пор, пока сообщение не будет получено и помещено в буфер со-
общений, указанный в параметрах. Процесс находится в приостановленном состоянии
после вызова receive до тех пор, пока не поступит сообщение, даже если на это уйдет
несколько часов. На некоторых системах процесс, принимающий сообщение, может
указать, от кого он хочет его получить, в таком случае он остается заблокированным,
пока сообщение не придет от этого отправителя.
Рис. 8.19. Процедура send: а — блокирующий вызов; б — неблокирующий вызов
Альтернативой блокирующим вызовам являются неблокирующие вызовы (иногда
называемые асинхронными вызовами). Если вызов send является неблокирующим, он
возвращает управление немедленно, еще до того, как сообщение будет отправлено. Пре-
имущество такой схемы заключается в том, что отправляющий процесс может продол-

8.2. Мультикомпьютеры
617
жить вычисления одновременно с передачей сообщения, а не заставлять простаивать
центральный процессор (если предположить, что не имеется других готовых к работе
процессов). Обычно выбор между блокирующими и неблокирующими процедурами
делают разработчики системы (то есть доступна либо та, либо другая процедура), хотя
существует ряд систем, где доступны обе разновидности процедур и пользователи
могут выбирать их по своему усмотрению.
Но преимущества в росте производительности, предлагаемые неблокирующими про-
цедурами, скрадываются серьезным недостатком: отправитель не может изменять
содержимое буфера сообщений до тех пор, пока сообщение не будет отправлено. По-
следствия переписывания процессом сообщения в ходе его отправки настолько ужасны,
что о них лучше не упоминать. Хуже того, процесс, отправляющий сообщение, ничего
не знает о том, когда оно будет отправлено, поэтому он не в курсе, когда можно будет
повторно воспользоваться буфером безо всякого ущерба. Так может дойти до того, что
он будет избегать пользоваться им до бесконечности.
Можно воспользоваться тремя выходами из этой ситуации. Первое решение
(рис. 8.19, б) заключается в том, чтобы ядро копировало сообщение в свой внутрен-
ний буфер, а потом позволяло процессу продолжить работу. С точки зрения отпра-
вителя эта схема ничем не отличается от схемы с блокирующим вызовом: как только
управление будет получено обратно, процесс волен использовать буфер по своему
усмотрению. Разумеется, на тот момент сообщение еще не будет отправлено, но от-
правителю это уже не помешает. Недостаток этого метода в том, что каждое исходя-
щее сообщение должно копироваться из пространства пользователя в пространство
ядра. При использовании многих сетевых интерфейсов сообщение все равно чуть
позже должно быть скопировано в аппаратный буфер передачи, поэтому первое
копирование, по сути, будет лишним. Дополнительное копирование существенно
снижает производительность системы.
Второе решение заключается в прерывании работы отправителя (отправке сигнала),
как только сообщение будет полностью отправлено, чтобы проинформировать его, что
буфер опять доступен. Здесь не нужно заниматься копированием, что экономит время,
но прерывания на пользовательском уровне усложняют процесс программирования
и приводят к возникновению состязательных условий, а это делает код невоспроизво-
димым и практически не поддающимся отладке.
Третье решение заключается в том, чтобы копировать буфер при записи и помечать его
доступным только для чтения до тех пор, пока сообщение не будет отправлено. Если
буфер повторно используется еще до отправки сообщения, то создается его копия.
Проблема этого решения в том, что пока буфер не будет изолирован на собственной
странице, запись соседних переменных также будет вызывать копирование. Кроме это-
го, потребуется дополнительное администрирование, потому что отправка сообщения
теперь всецело влияет на статус чтения-записи страницы. И наконец, рано или поздно
страницу, скорее всего, придется записывать опять, инициируя создание копии, которая
уже никогда не понадобится.
Таким образом, у отправителя есть следующий выбор:
Использовать блокирующую процедуру send (центральный процессор будет про-
стаивать в течение всей передачи сообщения).
Использовать неблокирующую процедуру send с копированием (время централь-
ного процессора тратится впустую на дополнительное копирование).

618
Глава 8. Многопроцессорные системы
Использовать неблокирующую процедуру send с прерыванием (при этом усложня-
ется программирование).
Использовать копирование при записи (в конечном счете может понадобиться до-
полнительная копия).
При обычных условиях первый вариант наиболее удобен, особенно если доступны не-
сколько потоков. В этом случае, пока один поток заблокирован при попытке отправки
сообщения, другие потоки могут продолжить свою работу. Кроме того, не нужно будет
управлять никакими буферами ядра. И еще: при сравнении рис. 8.19, а и рис. 8.19, б
можно заметить, что если не нужно делать копию, то сообщение появится на выходе
быстрее.
Чтобы не было недоразумений, следует заметить, что некоторые авторы используют
различные критерии отличия синхронных примитивов от несинхронных. Есть мнение,
что вызов является синхронным, только если отправитель заблокирован до тех пор,
пока не будет получено сообщение и обратно не будет отправлено подтверждение
(Andrews, 1991). А в мире коммуникаций в реальном масштабе времени синхронизация
имеет несколько иной смысл, что, к сожалению, приводит к путанице.
Процедура receive так же, как и процедура send, может быть блокирующей и неблоки-
рующей. Блокирующий вызов просто приостанавливает вызывающий процесс до тех
пор, пока не поступит сообщение. Если есть возможность использования нескольких
потоков, то такой подход трудностей не вызывает. В отличие от него вызов неблоки-
рующей процедуры receive просто сообщает ядру, где находится буфер, и управление
практически тут же возвращается. Чтобы дать сигнал о поступлении сообщения,
можно использовать прерывание. Однако прерывания трудны в программировании
и довольно медленно работают, поэтому, может быть, лучше отдать предпочтение
периодическому опросу получателя о наличии входящего сообщения, осуществляе-
мому с помощью процедуры poll, сообщающей о том, есть ли какие-нибудь ожидаемые
сообщения. Если есть поступления, то можно вызвать функцию get_message, которая
вернет первое поступившее сообщение. В некоторых системах компилятор может
вставлять вызовы poll в соответствующие места кода, хотя определить, как часто это
следует делать, довольно сложно.
Еще один вариант заключается в схеме, при которой поступающее сообщение само-
произвольно порождает новый поток в адресном пространстве процесса — получателя
сообщения. Он называется всплывающим потоком (pop-up thread). Этот поток за-
пускает заранее определенную процедуру, чьим параметром служит указатель на вхо-
дящее сообщение. После обработки сообщения осуществляются выход из процедуры
и автоматическое удаление потока.
Вариант этого замысла предусматривает запуск кода получателя непосредственно
в обработчике прерывания, чтобы избежать хлопот с созданием всплывающего по-
тока. Дополнительно ускорить работу этой схемы помогает то, что само сообщение
снабжают адресом обработчика, чтобы при поступлении обработчик мог быть вы-
зван всего несколькими командами. Большой выигрыш этой схемы в том, что не
требуется никакого копирования. Обработчик забирает сообщение из интерфейсной
платы и обрабатывает его на лету. Такая схема называется активными сообщениями
(Von Eicken et al., 1992). Поскольку каждое сообщение содержит адрес обработчика,
активные сообщения работают только при условии полного доверия между отпра-
вителями и получателями.

8.2. Мультикомпьютеры
619
8.2.4. Вызов удаленной процедуры
Хотя модель передачи сообщений предоставляет удобный способ структурирования
мультикомпьютерной операционной системы, она страдает от одного неустранимого
недостатка: базовая парадигма, вокруг которой построена вся коммуникация, представ-
ляет собой ввод-вывод данных. Процедуры send и receive, по сути, заняты осуществлени-
ем ввода-вывода, а многие считают ввод-вывод неверной моделью программирования.
Эта проблема имеет давнюю историю, но не было практически никаких подвижек
вплоть до выхода статьи Биррелла и Нельсона (Birrell and Nelson, 1984), в которой
был предложен совершенно другой способ ее решения. Хотя сама идея на удивление
проста (после того, как кто-то до нее додумался), ее применение часто чревато труд-
ноуловимыми осложнениями. В этом разделе будет рассмотрены сама концепция, ее
реализация и все ее сильные и слабые стороны.
В кратком изложении, Биррелл и Нельсон предложили разрешить программам вызов
процедур, находящихся на других центральных процессорах. Когда процесс на первой
машине вызывает процедуру, находящуюся на второй машине, то вызывающий про-
цесс на первой машине приостанавливается, а вызванная процедура выполняется на
второй машине. Информация может перемещаться от вызывающего к вызываемому
в параметрах и возвращаться обратно в результатах процедуры. Программист не видит
ни передачи сообщений, ни вообще какого-нибудь ввода-вывода. Эта технология из-
вестна как вызов удаленной процедуры (Remote Procedure Call (RPC)) и положена
в основу огромного количества программного обеспечения, разработанного для мульти-
компьютеров. Традиционно вызывающая процедура известна как клиент, а вызываемая
процедура — как сервер, и мы также будем придерживаться этой терминологии.
Идея, положенная в основу RPC, заключается в том, чтобы сделать вызов удаленной
процедуры максимально похожим на вызов локальной процедуры. В простейшем виде,
чтобы вызвать удаленную процедуру, клиентская программа должна быть связана с не-
большой библиотечной процедурой, которая называется клиентской заглушкой (client
stub). Аналогично этому сервер связан с процедурой, которая называется серверной
заглушкой
(server stub). Эти процедуры скрывают тот факт, что вызов процедуры, по-
ступающий от клиента к серверу, не является локальным.
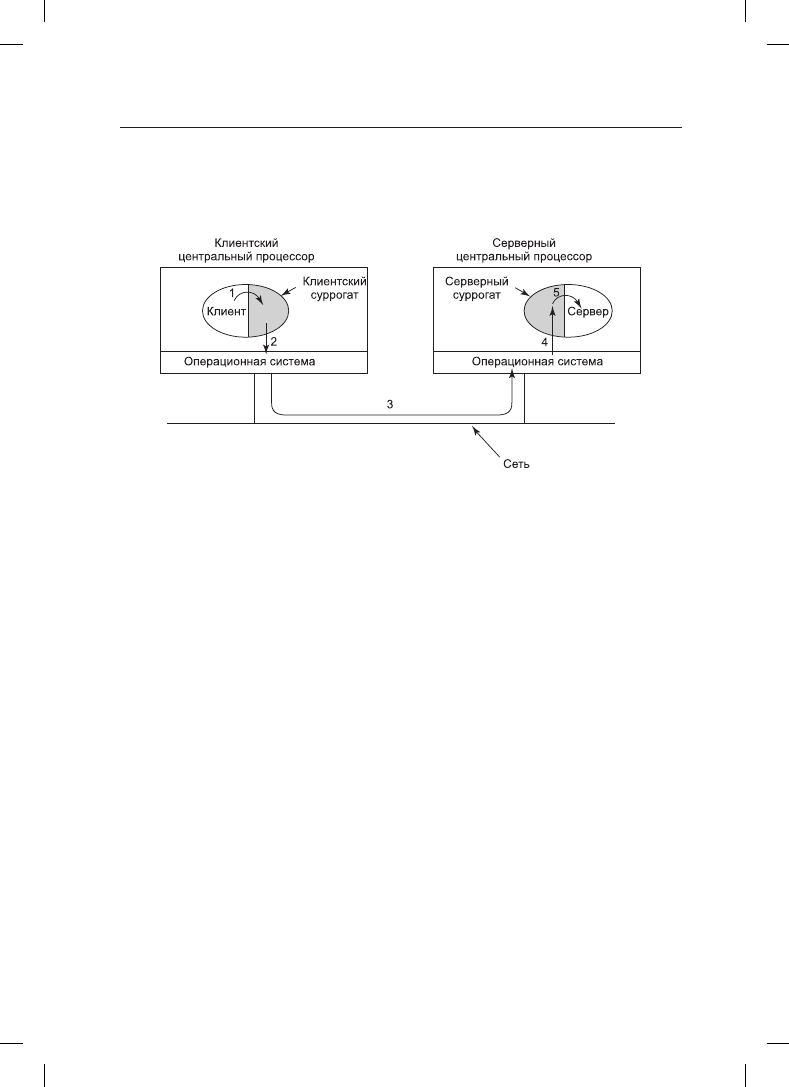
Реальные шаги осуществления RPC показаны на рис. 8.20. Шаг 1 заключается в вызове
клиентом клиентской заглушки. Этот вызов является вызовом локальной процедуры
с параметрами, помещенными в стек в обычном порядке. Шаг 2 заключается в том, что
клиентская заглушка упаковывает параметры в сообщение и осуществляет системный
вызов для его отправки. Упаковка параметров называется маршализацией (marshaling).
Шаг 3 заключается в том, что ядро отправляет сообщение с клиентской на серверную
машину. Шаг 4 состоит в том, что ядро передает входящий пакет серверной заглушке
(которая, как правило, еще раньше вызвала процедуру receive). И наконец, шаг 5 заклю-
чается в том, что серверная заглушка вызывает серверную процедуру. Ответ проходит
тот же путь, только в обратном направлении.
Основное, на что следует обратить внимание, заключается в том, что написанная
пользователем клиентская процедура осуществляет обычный (то есть локальный)
вызов процедуры клиентской заглушки, у которой такое же имя, как у серверной
процедуры. Поскольку клиентская процедура и клиентская заглушка находятся
в одном и том же адресном пространстве, параметры передаются обычным способом.
Аналогично этому серверная процедура вызывается процедурой в ее адресном про-
620
Глава 8. Многопроцессорные системы
странстве с ожидаемыми ею параметрами. Для серверной процедуры нет ничего не-
обычного. Таким образом, вместо осуществления операций ввода-вывода с помощью
процедур send и receive удаленный обмен данными осуществляется за счет имитации
обычного вызова процедуры.
Рис. 8.20. Этапы осуществления вызова удаленной процедуры;
заглушки закрашены серым цветом
Вопросы реализации
Несмотря на концептуальную элегантность RPC, в этой технологии кроется ряд под-
вохов. Самый большой из них заключается в использовании указателей в качестве па-
раметров. Обычно передача процедуре указателя не создает никакой проблемы. Вызы-
ваемая процедура может воспользоваться указателем точно так же, как и вызывающая
процедура, поскольку эти две процедуры находятся в едином виртуальном адресном
пространстве. При использовании технологии RPC передача указателей становится
невозможной, потому что клиент и сервер находятся в разных адресных пространствах.
В некоторых случаях, чтобы сделать возможной передачу указателей, можно восполь-
зоваться ухищрениями. Предположим, что первый параметр является указателем на
целочисленную переменную k. Клиентская заглушка может маршализовать перемен-
ную k и отправить ее на сервер. Затем серверная заглушка может создать указатель на
k и передать его серверной процедуре обычным порядком. Когда серверная процедура
вернет управление серверной заглушке, та отправит k обратно клиенту, где новое зна-
чение k будет скопировано поверх старого, на тот случай, если сервер изменил значение
этой переменной. В результате стандартная последовательность вызова с вызовом по
ссылке заменяется копированием с последующим восстановлением. К сожалению, этот
трюк срабатывает не всегда: к примеру, он не работает, если указатель имеет отношение
к графу или другой сложной структуре данных. Поэтому на параметры вызова удален-
ной процедуры должны накладываться определенные ограничения.
Вторая проблема заключается в том, что в слаботипизированных языках, подобных C,
вполне допустимо написать процедуру, вычисляющую скалярное произведение двух
векторов (массивов) без указания длины каждого из них. Каждый из них может за-
канчиваться специальным значением, известным только вызывающей и вызываемой