Добавлен: 29.10.2018
Просмотров: 48164
Скачиваний: 190

8.4. Распределенные системы
641
файла:
protocol://DNS-name/file-name
. Чаще всего в качестве протокола используется
http
(HyperText Transfer Protocol — протокол передачи гипертекстовых файлов), но есть
также протокол
ftp
и др. Затем следует DNS-имя того хоста, на котором хранится файл.
И наконец, следует имя локального файла, сообщающее, какой файл нужен. Таким обра-
зом URL-адрес однозначно определяет конкретный файл во всем мировом пространстве.
Система формируется в единое целое следующим образом. В своей основе Всемирная
паутина является клиент-серверной системой, где в качестве клиента выступает поль-
зователь, а в качестве сервера — веб-сайт. Когда пользователь предоставляет браузеру
URL, либо набирая его в поле адреса, либо щелкая на гиперссылке, расположенной на
текущей странице, браузер предпринимает определенные шаги для извлечения запро-
шенной веб-страницы. В качестве простого примера предположим, что ему предостав-
лен URL
http://www.minix3.org/getting-started/index.html
. Затем происходит следующее:
1. Браузер запрашивает у DNS IP-адрес, соответствующий имени
www.minix3.org
.
2. DNS в ответ выдает 66.147.238.215.
3. Браузер устанавливает TCP-соединение с портом 80 на хосте с IP-адресом
66.147.238.215.
4. Затем он отправляет запрос на файл
getting-started/index.html
.
5. Сервер
www.minix3.org
отправляет файл
getting-started/index.html
.
6. Браузер отображает весь текст из файла
getting-started/index.html
.
7. В то же время браузер извлекает и отображает все имеющиеся на странице изо-
бражения.
8. TCP-соединение разрывается.
Именно так в первом приближении и выглядят основа Всемирной паутины и порядок
ее работы. С тех пор к базовой Всемирной паутине было добавлено множество других
особенностей, включая таблицы стилей, динамические веб-страницы, генерируемые
на лету, веб-страницы, содержащие небольшие программы или сценарии, которые
выполняются на клиентской машине, и многое другое, но все это лежит за пределами
рассматриваемой области.
8.3.4. Связующее программное обеспечение на основе
файловой системы
Идея, заложенная в основу Всемирной паутины, заключается в приведении распре-
деленной системы к виду гигантской коллекции документов, имеющих гиперссылки.
Следующий подход состоит в создании распределенной системы, имеющей вид ко-
лоссально большой файловой системы. В этом разделе будут рассмотрены некоторые
вопросы, касающиеся разработки всемирной файловой системы.
Использование для распределенной системы модели файловой системы означает на-
личие единой глобальной файловой системы с пользователями по всему миру, имею-
щими возможность читать и записывать файлы, к которым у них есть право доступа.
Информационный обмен осуществляется за счет того, что один процесс записывает
данные в файл, а другой процесс считывает их оттуда. Здесь возникает множество
вопросов, связанных со стандартной файловой системой, появляется и ряд новых во-
просов, связанных с распределенностью.
642
Глава 8. Многопроцессорные системы
Модель передачи данных
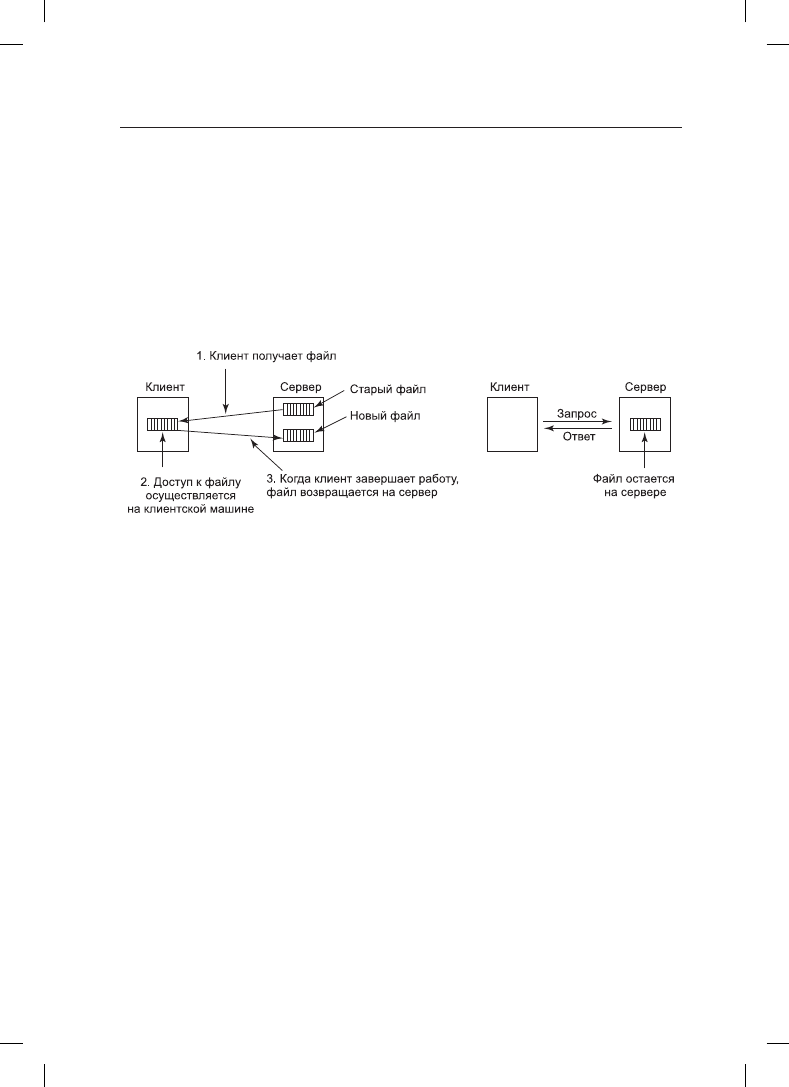
Первый вопрос касается выбора между моделью загрузки-выгрузки (upload/download
model) и моделью удаленного доступа (remote access model). При использовании пер-
вой из них (рис. 8.32, а) процесс обращается к файлу, сначала копируя его с удаленного
сервера, на котором он находится. Если файл предназначен только для чтения, то для
обеспечения более высокой производительности он читается локально. Если файл
должен быть записан, то он записывается локально. Когда процесс завершает работу
с файлом, обновленный файл возвращается на сервер. При использовании модели
удаленного доступа файл остается на сервере, а клиент отправляет команды, где и что
с ним нужно сделать (рис. 8.32, б).
Рис. 8.32. Модель: а — загрузки-выгрузки; б — удаленного доступа
Преимущество модели загрузки-выгрузки заключается в ее простоте и том факте, что
перенос файла целиком эффективнее, чем перенос его по частям. Недостаток этой
модели заключается в необходимости наличия достаточного места для локального
хранения всего файла целиком, нерациональности перемещения всего файла, когда
нужна лишь его часть, а также проблемах непротиворечивости, возникающих при
параллельном использовании файла несколькими пользователями.
Иерархия каталогов
Файлы — это только часть нашей истории. Другой ее частью является система ката-
логов. Все распределенные файловые системы поддерживают каталоги, содержащие
множество файлов. Следующий конструктивный вопрос касается необходимости
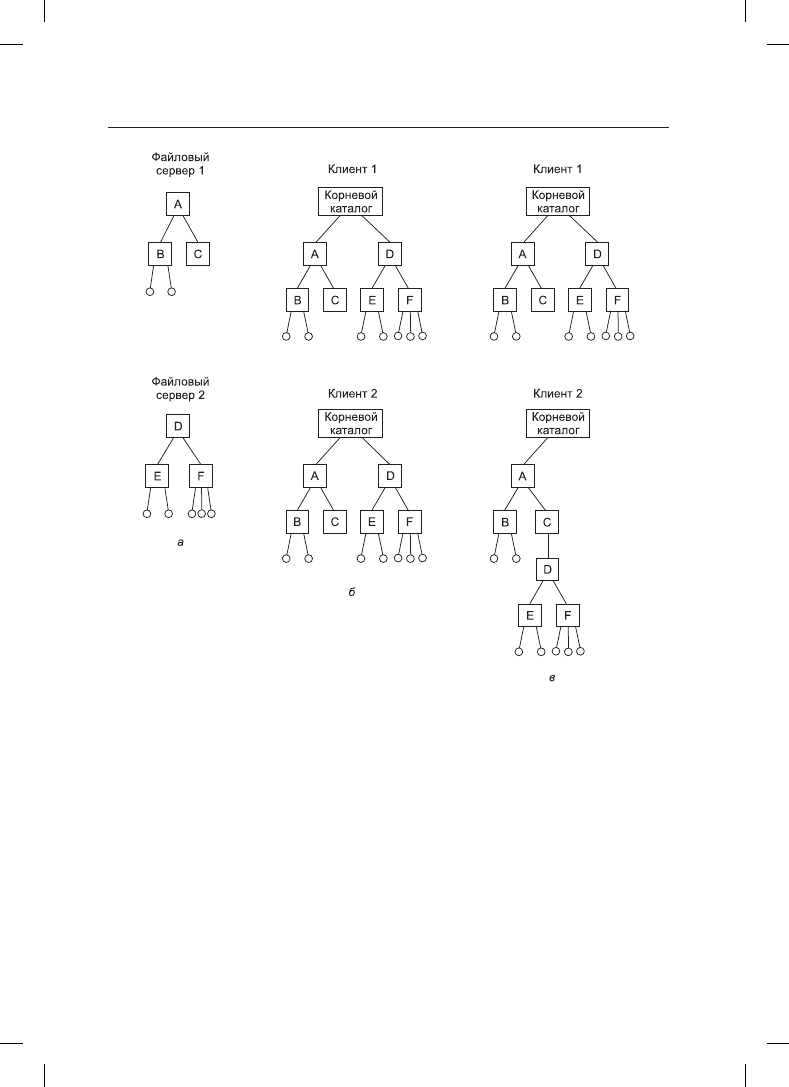
наличия у всех клиентов единого вида иерархии каталогов. Чтобы пояснить суть
вопроса, рассмотрим пример, приведенный на рис. 8.33. На рис. 8.33, а показаны два
файловых сервера, каждый из которых содержит по три каталога и по несколько фай-
лов. На рис. 8.33, б показана система, в которой все клиенты (и другие машины) имеют
одинаковую картину распределенной файловой системы. Если путь
/D/E/x
является
допустимым для одной машины, он допустим и на всех остальных машинах.
В отличие от этого на рис. 8.33, в разные машины имеют разный взгляд на файловую
систему. Если вернуться к предыдущему примеру, то путь
/D/E/x
может быть вполне
допустим для клиента 1, но не для клиента 2. В системе, управляющей несколькими
файловыми серверами за счет удаленного подключения (монтирования), ситуация,
показанная на рис. 8.33, в, является нормой. Это гибкая и простая в реализации
8.4. Распределенные системы
643
Рис. 8.33. Два файловых сервера: а — квадратами показаны каталоги, а окружностями —
файлы; б — все клиенты имеют одинаковую картину файловой системы;
в — разные клиенты могут иметь собственную картину файловой системы
система, но ее недостаток заключается в том, что всю систему нельзя заставить вести
себя так, как будто это единая старомодная система с разделением времени. В системе
с разделением времени файловая система выглядит одинаково для любого процесса,
как в модели, показанной на рис. 8.33, б. Это свойство делает систему проще для вос-
приятия и работы программ.
С этим вопросом тесно связан еще один вопрос, касающийся необходимости наличия
глобального корневого каталога, распознаваемого всеми машинами в качестве корнево-
го. Один из способов, позволяющий иметь глобальный корневой каталог, заключается
в наличии корневого каталога, содержащего всего одну запись для каждого сервера,
и ничего больше. При этом все пути примут вид
/сервер/путь
, у которого есть свои
недостатки, но они, по крайней мере, будут одинаковыми по всей системе.

644
Глава 8. Многопроцессорные системы
Прозрачность именования
Главная проблема такой формы именования заключается в том, что она не полностью
прозрачна. В данном контексте большое значение имеют две формы прозрачности,
которые следует различать. Первая форма, называемая прозрачностью местоположе-
ния
(location transparency), означает, что по имени пути невозможно определить, где
именно находится файл. Путь
/server1/dir1/dir2/x
сообщает всем, что файл
x
находится
на сервере
server1
, но он не сообщает о том, где именно находится этот сервер. Сервер
может как угодно перемещаться по сети, не требуя изменения имени пути. Это озна-
чает, что данная система имеет прозрачность местоположения.
А теперь предположим, что файл
x
имеет очень большой размер, а на сервере
server1
мало места. Кроме того, предположим, что на сервере
server2
избыток места. Для
системы было бы неплохо автоматически переместить файл
x
на сервер
server2
. К со-
жалению, когда первым компонентом всех имен путей является сервер, система не
может автоматически переместить файл на другой сервер, даже если каталоги
dir1
и
dir2
существуют на обоих серверах. Проблема в том, что автоматическое перемещение
файла изменит имя его пути с
/server1/dir1/dir2/x
на
/server2/dir1/dir2/x
. Программы,
имеющие встроенную в себя первую строку, не станут работать, если путь изменится.
Про системы, в которых файлы могут перемещаться без изменения их имен, говорится
что они обладают независимостью от местонахождения (location indenpendence). По-
нятно, что распределенные системы, в которых имена машин или серверов внедряются
в имена путей, не обладают независимостью местонахождения. Системы, основанные
на подключении (монтировании), также не обладают этим свойством, поскольку не-
возможно переместить файл из одной файловой группы (смонтированного блока)
в другую и сохранить возможность использования старого имени пути. Достичь неза-
висимости от местонахождения не так-то просто, но желательно, чтобы это свойство
все же присутствовало в распределенной системе.
Подводя итог всему сказанному, следует отметить, что существует три общепринятых
подхода к наименованию файлов и каталогов в распределенных системах:
1. Имя машины + имя пути, например
/машина
/путь
или
машина:путь
.
2. Подключение (монтирование) удаленной файловой системы к локальной фай-
ловой иерархии.
3. Единое пространство имен, которое выглядит одинаково на всех машинах.
Первые два подхода легко реализуются, особенно как способ подключения существую-
щих систем, которые не разрабатывались для распределенного использования. Послед-
ний подход труднореализуем и требует тщательной отработки при конструировании,
но облегчает жизнь программистам и пользователям.
Семантика совместного использования файлов
Когда с одним и тем же файлом работают вместе два и более пользователя, то во из-
бежание проблем необходимо точно определять семантику, используемую при чтении
и записи файла. В однопроцессорных системах семантические правила устанавливают,
что следование системного вызова read за системным вызовом write приводит к тому,
что read возвращает только что записанное значение (рис. 8.34, а). По аналогии с этим,
если системный вызов read следует сразу же за двумя последовательными системными
вызовами write, то считывается значение, записанное последним системным вызовом
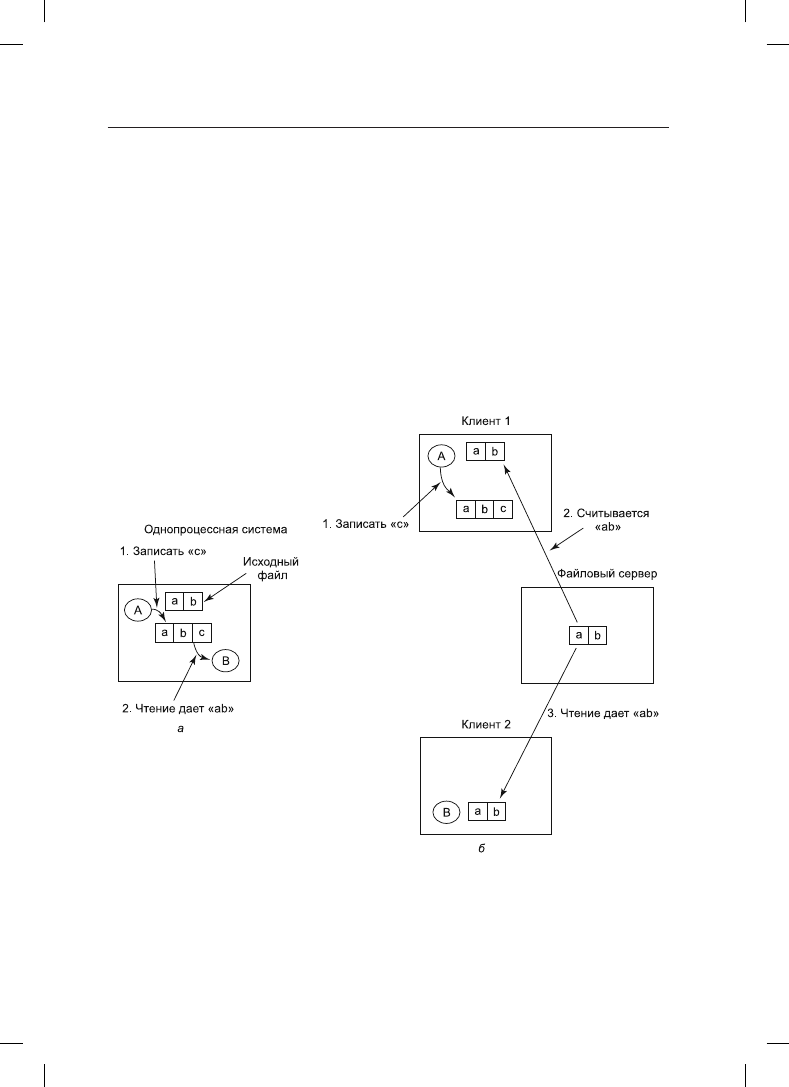
8.4. Распределенные системы
645
write. Таким образом, все системные вызовы упорядочиваются системой в единую по-
следовательность и все процессоры видят один и тот же порядок. Мы будем ссылаться
на такую модель как на последовательно непротиворечивую (sequential consistency).
В распределенной системе последовательная непротиворечивость легко достигается
при наличии всего лишь одного файлового сервера и отсутствии кэширования файлов
у клиентов. Все системные вызовы read и write поступают непосредственно на файло-
вый сервер, который обрабатывает их в строгой последовательности.
Тем не менее на практике производительность распределенной системы, в которой все
файловые запросы должны выполняться на единственном сервере, имеет зачастую
весьма низкие показатели. Довольно часто эта проблема решается за счет разрешения
клиентам работать с локальными копиями наиболее часто используемых файлов, со-
держащимися в их собственной кэш-памяти. Но если клиент 1 произведет локальные
изменения хранящегося в кэше файла, а вскоре после этого клиент 2 прочитает файл
с сервера, то второй клиент получит устаревшую версию файла (рис. 8.34, б).
Рис. 8.34. а — последовательная непротиворечивость; б — в распределенной системе
с кэшированием при чтении файла может быть возвращено устаревшее значение
Один из способов обхода этих затруднений заключается в немедленном возвращении
всех изменений кэшируемых файлов обратно на сервер. При всей простоте замысла
этот подход неэффективен. Альтернативное решение заключается в смягчении семан-