Добавлен: 29.10.2018
Просмотров: 48158
Скачиваний: 190
8.5. Исследования в области многопроцессорных систем
651
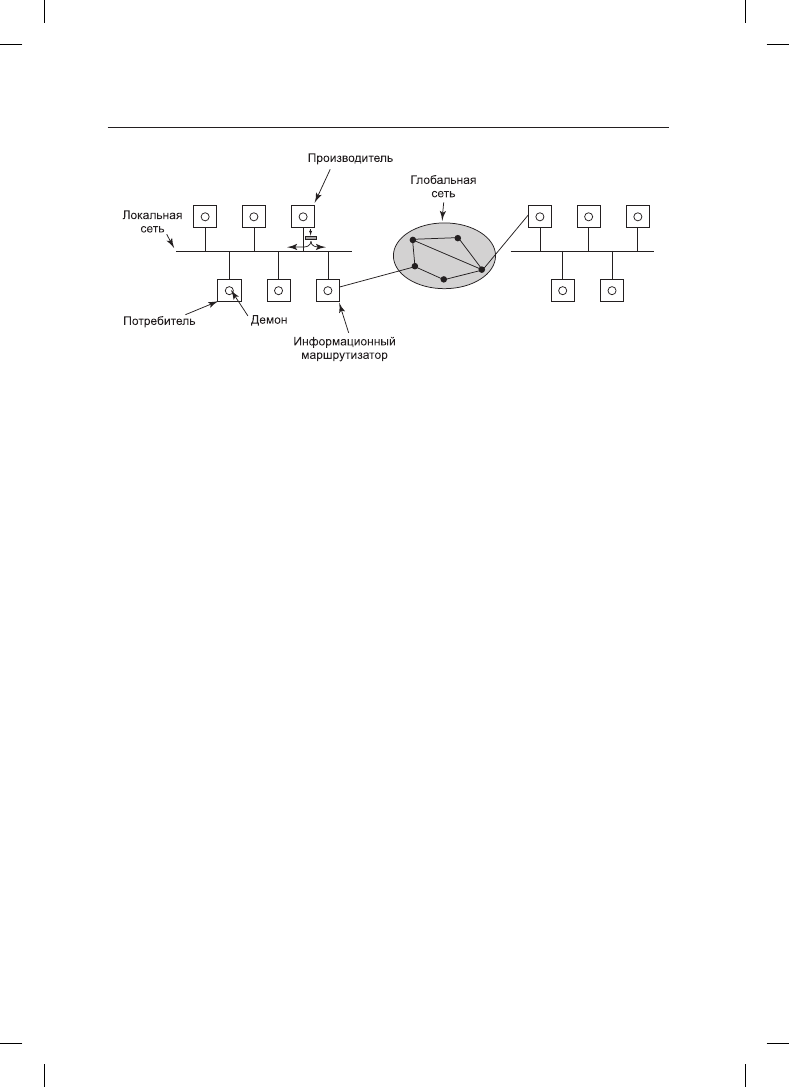
Рис. 8.36. Архитектура публикации-подписки
базы данных к системе и ее подписки на все кортежи. Это может быть выполнено за
счет помещения системы базы данных в оболочку адаптера, чтобы позволить существу-
ющей базе данных работать с моделью публикации-подписки. По мере поступления
кортежей все они перехватываются адаптером, который помещает их в базу данных.
Модель публикации-подписки полностью отделяет производителей от потребителей,
как и система Linda. Но иногда полезно знать, кто еще есть в системе. Для этого можно
опубликовать кортеж, который, по существу, задает вопрос: «Кого здесь интересует
тема x?» Ответы возвращаются в виде кортежей, сообщающих следующее: «Меня
интересует тема x».
8.4. Исследования в области
многопроцессорных систем
По популярности темы исследований многоядерных систем, мультипроцессоров и рас-
пределенных систем превосходят многие другие темы. Кроме непосредственных во-
просов отображения функциональности операционной системы на систему, состоящую
из нескольких вычислительных ядер, есть множество открытых тем исследований,
связанных с синхронизацией и согласованностью, а также способов ускорения и на-
дежности работы таких систем.
Усилия некоторых исследователей направлены на разработку новых операционных си-
стем с нуля, особенно для многоядерного оборудования. Например, в операционной си-
стеме Corey рассматриваются проблемы производительности, вызванные совместным
использованием структуры данных несколькими ядрами (Boyd-Wickizer et al., 2008).
Тщательная организация структур данных ядра, позволяющая исключить необходи-
мость совместного использования структуры данных, приведет к исчезновению многих
узких мест, мешающих достижению высокой производительности. Также новая опера-
ционная система Barrelfish (Baumann et al., 2009) мотивирована на быстрый рост коли-
чества ядер, с одной стороны, и на рост разнообразия оборудования — с другой. В ней
моделируется операционная система после появления в качестве коммуникационной
модели вместо совместно используемой памяти распределенных систем с передачей
сообщений. Другие операционные системы нацелены на достижение высокой степени

652
Глава 8. Многопроцессорные системы
масштабируемости и производительности. Операционная система Fos (Wentzlaff et al.,
2010) была спроектирована для масштабирования от небольших пределов (мультия-
дерные центральные процессоры) до очень больших (облачные вычисления). В то же
время NewtOS (Hruby et al., 2012; Hruby et al., 2013) является новой мультисерверной
операционной системой, нацеленной как на достижение высокой надежности (благо-
даря модульной конструкции и многим изолированным компонентам, изначально
основанным на Minix 3), так и на получение высокой производительности (которая
традиционно была слабым местом подобных модульных мультисерверных систем).
Исследования мультиядер касаются не только новых конструкций. В работе Boyd-
Wickizer et al. (2010) исследователи изучают узкие места, обнаруживаемые при мас-
штабировании Linux на 48-ядерной машине, и способы избавления от недостатков. Они
показывают, что такие системы при тщательном проектировании могут неплохо подда-
ваться масштабированию. В работе Clements et al. (2013) изучаются фундаментальные
принципы, определяющие возможность реализации API в масштабируемом варианте.
Исследования показывают, что при каждом переключении операций интерфейса суще-
ствует его масштабируемая реализация. Зная это, разработчики операционных систем
могут создавать лучшие масштабируемые операционные системы.
В последние годы многие исследования систем проводились также в области создания
больших приложений, масштабируемых на среды мультиядер и мультипроцессоров.
Примером может послужить масштабируемый процессор базы данных, описание
которого дано в работе Salomie et al. (2011). Здесь также решение заключается в дости-
жении масштабируемости путем тиражирования базы данных вместо попыток скрыть
параллельную природу оборудования.
Отладка параллелльных приложений крайне затруднена, а условия состязательности
очень трудно поддаются воспроизведению. В работе Viennot et al. (2013) показано, как
повторение может помочь отладке программ на мультиядерных системах. В работе
Lachaize et al. предоставлен профайлер памяти для мультиядерных систем, а в иссле-
довании Kasikci et al. (2012) представлена работа не только по обнаружению условий
состязательности в программах, но даже по способам выделения хороших состязатель-
ных условий из плохих.
И наконец, существует множество работ по сокращению энергопотребления в муль-
типроцессорах. В работе Chen et al. (2013) для детального управления потребляемой
мощностью и расходом энергии предлагается использовать контейнеры электропита-
ния (power containers).
8.6. Краткие выводы
Использование нескольких процессоров позволяет увеличить быстродействие и на-
дежность компьютерных систем. Многопроцессорные системы имеют четыре формы
организации: мультипроцессоры, мультикомпьютеры, виртуальные машины и распре-
деленные системы. Каждая из них обладает своими особенностями.
Мультипроцессор состоит из двух и более центральных процессоров, которые совмест-
но используют общую память. Зачастую эти центральные процессоры сами состоят из
нескольких ядер. Ядра и центральные процессоры могут быть связаны между собой по
шине, с помощью координатного коммутатора или с помощью многоступенчатых схем
коммутации. Возможны различные конфигурации операционной системы, включая

Вопросы
653
предоставление каждому центральному процессору собственной операционной си-
стемы, наличие одной главной операционной системы и всех остальных подчиненных
или наличие симметричного мультипроцессора с одной копией операционной систе-
мы, которая может быть запущена на любом центральном процессоре. В последнем
случае для обеспечения синхронизации требуется использовать блокировки. Когда
блокировка недоступна, центральный процессор может ждать ее освобождения или
осуществить переключение контекста. Возможно применение различных алгоритмов
планирования, включая разделение времени, совместное использование пространства
и бригадное планирование.
У мультикомпьютеров также имеется два и более центральных процессора, но у этих
процессоров имеется собственная закрытая память. Они не используют совместно
никакой оперативной памяти, поэтому весь обмен данными осуществляется при по-
мощи передачи сообщений. В некоторых случаях сетевые интерфейсные карты имеют
собственный центральный процессор, в таком случае обмен данными между основным
центральным процессором и центральным процессором на интерфейсной карте дол-
жен быть тщательно организован во избежание состязательных ситуаций. Для обмена
данными на пользовательском уровне на мультикомпьютерах часто используются вы-
зовы удаленных процедур, но может использоваться и распределенная общая память.
Также важен вопрос сбалансированности нагрузки процессов, и для его решения ис-
пользуются различные алгоритмы, включая алгоритмы, инициируемые отправителем,
алгоритмы, инициируемые получателем, и алгоритмы торгов между ними.
Распределенные системы относятся к разряду слабосвязанных систем, каждый узел ко-
торых является полноценным компьютером с полным набором периферийных устройств
и собственной операционной системой. Зачастую такие системы простираются на
большие географические области. Связующее программное обеспечение часто является
надстройкой над операционной системой и предназначено для обеспечения одинакового
уровня, с которым могли бы взаимодействовать приложения. Имеются различные виды
связующего программного обеспечения: на основе документа, на основе файловой си-
стемы, на основе объектов и на основе взаимодействия. В качестве некоторых примеров
можно привести Всемирную паутину (World Wide Web), CORBA и Linda.
Вопросы
1. Можно ли систему сетевых новостей USENET или проект SETI@home считать
распределенной системой? (Проект SETI@home использует несколько миллионов
персональных компьютеров для анализа данных, получаемых с радиотелескопа
с целью поиска внеземного разума.) Если да, то к каким категориям, показанным
на рис. 8.1, они относятся?
2. Что произойдет, если три центральных процессора на мультипроцессоре попыта-
ются одновременно получить доступ к одному и тому же слову памяти?
3. Если центральный процессор при каждой команде совершает одно обращение к па-
мяти, сколько понадобится центральных процессоров, работающих со скоростью
200 MIPS, чтобы переполнить данными шину, работающую с тактовой частотой
400 МГц? Предположим, что для обращения к памяти требуется один цикл шины.
Теперь решите эту же задачу для системы, в которой используется кэширование
и вероятность наличия в кэше нужных данных составляет 90 %. Наконец, какая

654
Глава 8. Многопроцессорные системы
потребуется частота наличия в кэше нужных данных, чтобы той же шиной, не
перегружая ее, могли совместно пользоваться 32 центральных процессора?
4. Предположим, что порвется провод между коммутаторами 2A и 3B в схеме ком-
мутации омега (см. рис. 8.5). Кто от кого окажется отрезанным?
5. Как выполняется обработка сигнала в модели, изображенной на рис. 8.7?
6. Когда в модели, показанной на рис. 8.8, осуществляется системный вызов, возни-
кает проблема, требующая немедленного решения после системного прерывания,
которая не возникает в модели, показанной на рис. 8.7. Какова природа этой про-
блемы и как она может быть решена?
7. Перепишите программу enter_region из листинга 2.3, используя чистое чтение,
чтобы уменьшить пробуксовку системы, вызываемую применением команды TSL.
8. Многоядерные центральные процессоры начали появляться на обычных настоль-
ных машинах и ноутбуках. Не за горами появление настольных компьютеров
с десятками или сотнями ядер. Один из возможных путей использования такой
мощности заключается в распараллеливании стандартных приложений, например
текстовых процессоров и веб-браузеров. Другим возможным способом исполь-
зования мощности является распараллеливание служб операционной системы
(например, обработки TCP) и широко применяемых библиотечных служб (на-
пример, безопасных библиотечных функций http). Какой из подходов является
более многообещающим? Почему?
9. Нужны ли на самом деле критические области в программных секциях в операци-
онной системе SMP для предотвращения возникновения состязательных условий
или для этого достаточно мьютексов в структурах данных?
10. При применении команды TSL для синхронизации мультипроцессора блок кэша,
содержащий мьютекс, будет мотаться взад-вперед между центральным процессо-
ром, удерживающим блокировку, и центральным процессором, запрашивающим
ее, если оба процессора изменяют содержимое блока. Для снижения объема обмена
данными по шине запрашивающий центральный процессор выполняет команду
TSL один раз за каждые 50 циклов шины, но центральный процессор, удержива-
ющий блокировку, изменяет блок кэша между командами TSL. Если блок кэша
состоит из шестнадцати 32-разрядных слов, для переноса каждого из которых
требуется один цикл шины, а шина работает с частотой 400 МГц, то какая часть
пропускной способности шины тратится впустую на перемещение блока кэша
взад-вперед?
11. В тексте предлагалось использовать алгоритм двоичной экспоненциальной за-
держки между вызовами команды TSL для опроса блокировки. Также предлага-
лось использовать максимальное значение задержки между опросами. Будет ли
алгоритм правильно работать при отсутствии максимальной задержки?
12. Предположим, что команда TSL была недоступна для синхронизации мульти-
процессора. Вместо нее была предоставлена другая команда, SWP, атомарно ме-
няющая местами содержимое регистра и слова в памяти. Может ли эта команда
использоваться для обеспечения синхронизации мультипроцессора? Если да, то
как? Если нет, то почему?
13. В этом задании вам предлагается вычислить, какую нагрузку на шину оказывает
спин-блокировка. Допустим, что выполнение каждой команды центрального

Вопросы
655
процессора занимает 5 нс. Когда выполнение команды завершено, выполняются
все необходимые циклы шины, например для TSL. Каждый цикл шины занимает
дополнительно 10 нс, которые не входят во время выполнения команды. Какую
часть пропускной способности шины отнимает процесс, выполняющий в цикле
команду TSL, чтобы войти в критическую область? Предположим, что работает
нормальное кэширование, поэтому извлечение команды внутри цикла не отнимает
циклов шины.
14. Родственное планирование снижает частоту отсутствия в кэше нужных данных.
Снижается ли при этом также частота отсутствия нужной информации в TLB?
А как насчет ошибок отсутствия страниц?
15. Чему равен диаметр соединительной сети для каждой из топологий, изображенных
на рис. 8.16? Считайте, что в этой задаче одинаковы все транзитные участки как
между хостом и маршрутизатором, так и между двумя маршрутизаторами.
16. Рассмотрите топологию двойного тора (см. рис. 8.16, г), расширенного до размера
k × k. Чему равен диаметр сети?
Подсказка
: рассматривайте четные и нечетные значения k отдельно.
17. Для измерения пропускной способности соединительной сети часто применяется
метод бисекции. Для этого из сети удаляется минимальное количество связей,
позволяющее разбить сеть на две равные части. Затем суммируется пропускная
способность удаленных линий связи. Если способов разбиения сети несколько, вы-
бирается тот, при котором эта сумма минимальна. Чему равна бисекционная про-
пускная способность соединительной сети, представляющей собой куб 8 × 8 × 8,
если пропускная способность каждой линии равна 1 Гбит/с?
18. Представим себе мультикомпьютер, в котором сетевой интерфейс работает в ре-
жиме пользователя, поэтому для перемещения данных из оперативной памяти
источника в оперативную память приемника требуется всего три операции копи-
рования. Предположим, что перемещение 32-разрядного слова через карту сете-
вого интерфейса в обе стороны занимает 20 нс, а сама сеть работает со скоростью
1 Гбит/с. Чему будет равна задержка при пересылке 64-байтового пакета от ис-
точника к приемнику без учета времени копирования? Чему будет равна задержка
с учетом времени копирования? Теперь рассмотрите случай, в котором требуются
две дополнительные операции копирования: в ядро на передающей стороне и из
ядра на принимающей стороне. Чему будет равна задержка в этом случае?
19. Повторите предыдущее задание для случая с тремя и пятью операциями копиро-
вания, но на этот раз рассчитайте не время задержки, а пропускную способность.
20. При переносе данных из оперативной памяти в сетевую интерфейсную плату мо-
жет использоваться фиксация страницы. Предположим, что выполнение систем-
ных вызовов для фиксации и освобождения страниц занимает 1 мкс. Копирование
данных занимает 5 байт/нс с использованием DMA и 20 нс на байт — при помощи
программного ввода-вывода. Каким должен быть минимальный размер пакета,
чтобы фиксация страницы и использование DMA были оправданны?
21. При извлечении процедуры с одной машины и помещении ее на другую, чтобы
ее можно было вызвать с помощью RPC (вызова удаленной процедуры), могут
возникнуть некоторые проблемы. В тексте указывались четыре из них: указатели,
массивы неизвестных размеров, неизвестные типы параметров и глобальные пере-