Добавлен: 29.10.2018
Просмотров: 48011
Скачиваний: 190

2.1. Процессы
121
Таблица 2.1. Некоторые из полей типичной записи таблицы процессов
Управление процессом
Управление памятью
Управление файлами
Регистры
Указатель на информацию
о текстовом сегменте
Корневой каталог
Счетчик команд
Указатель на информацию
о сегменте данных
Рабочий каталог
Слово состояния программы
Указатель на информацию
о сегменте стека
Дескрипторы файлов
Указатель стека
Идентификатор пользователя
Состояние процесса
Идентификатор группы
Приоритет
Параметры планирования
Идентификатор процесса
Родительский процесс
Группа процесса
Сигналы
Время запуска процесса
Использованное время процессора
Время процессора, использованное дочерними процессами
Время следующего аварийного сигнала
этого процесса, слово состояния программы, а иногда и один или несколько регистров
помещаются в текущий стек аппаратными средствами прерывания. Затем компьютер
переходит на адрес, указанный в векторе прерывания. На этом работа аппаратных
средств заканчивается и вступает в действие программное обеспечение, а именно про-
цедура обслуживания прерывания.
Все прерывания сначала сохраняют состояния регистров, зачастую используя для
этого запись текущего процесса в таблице процессов. Затем информация, помещенная
в стек прерыванием, удаляется и указатель стека переустанавливается на временный
стек, используемый обработчиком прерывания. Такие действия, как сохранение реги-
стров и переустановка указателя стека, не могут быть выражены на языках высокого
уровня (например, C), поэтому они выполняются небольшой подпрограммой на языке
ассемблера, обычно одной и той же для всех прерываний, поскольку характер работы
по сохранению регистров не изменяется, какой бы ни была причина прерывания.
Когда эта подпрограмма завершает свою работу, она вызывает C-процедуру, которая
делает всю остальную работу для данного конкретного типа прерывания. (Мы предпо-
лагаем, что операционная система написана на языке C, который обычно и выбирается
для всех настоящих операционных систем.) Возможно, когда работа этой процедуры
будет завершена, какой-нибудь процесс переходит в состояние готовности к работе
и вызывается планировщик, чтобы определить, какой процесс будет выполняться
следующим. После этого управление передается обратно коду, написанному на языке
ассемблера, чтобы он загрузил для нового текущего процесса регистры и карту памяти
и запустил выполнение этого процесса. Краткое изложение процесса обработки преры-
вания и планирования приведено в табл. 2.2. Следует заметить, что детали от системы
к системе могут несколько различаться.

122
Глава 2. Процессы и потоки
Таблица 2.2. Схема работы низшего уровня операционной системы
при возникновении прерывания
1
Оборудование помещает в стек счетчик команд и т. п.
2
Оборудование загружает новый счетчик команд из вектора прерывания
3
Процедура на ассемблере сохраняет регистры
4
Процедура на ассемблере устанавливает указатель на новый стек
5
Запускается процедура на языке C, обслуживающая прерывание (как правило, она
считывает входные данные и помещает их в буфер)
6
Планировщик принимает решение, какой процесс запускать следующим
7
Процедура на языке C возвращает управление ассемблерному коду
8
Процедура на ассемблере запускает новый текущий процесс
Процесс во время своего выполнения может быть прерван тысячи раз, но ключевая
идея состоит в том, что после каждого прерывания прерванный процесс возвращается
в точности к такому же состоянию, в котором он был до того, как случилось прерывание.
2.1.7. Моделирование режима многозадачности
Режим многозадачности позволяет использовать центральный процессор более ра-
ционально. При грубой прикидке, если для среднестатистического процесса вычисле-
ния занимают лишь 20 % времени его пребывания в памяти, то при пяти одновременно
находящихся в памяти процессах центральный процессор будет загружен постоянно.
Но в эту модель заложен абсолютно нереальный оптимизм, поскольку в ней заведомо
предполагается, что все пять процессов никогда не будут одновременно находиться
в ожидании окончания какого-нибудь процесса ввода-вывода.
Лучше выстраивать модель на основе вероятностного взгляда на использование цен-
трального процессора. Предположим, что процесс проводит часть своего времени p
в ожидании завершения операций ввода-вывода. При одновременном присутствии
в памяти n процессов вероятность того, что все n процессов ожидают завершения ввода-
вывода (в случае чего процессор простаивает), равна p
n
. Тогда время задействования
процессора вычисляется по формуле
Время задействования ценрального процессора = 1 − p
n
.
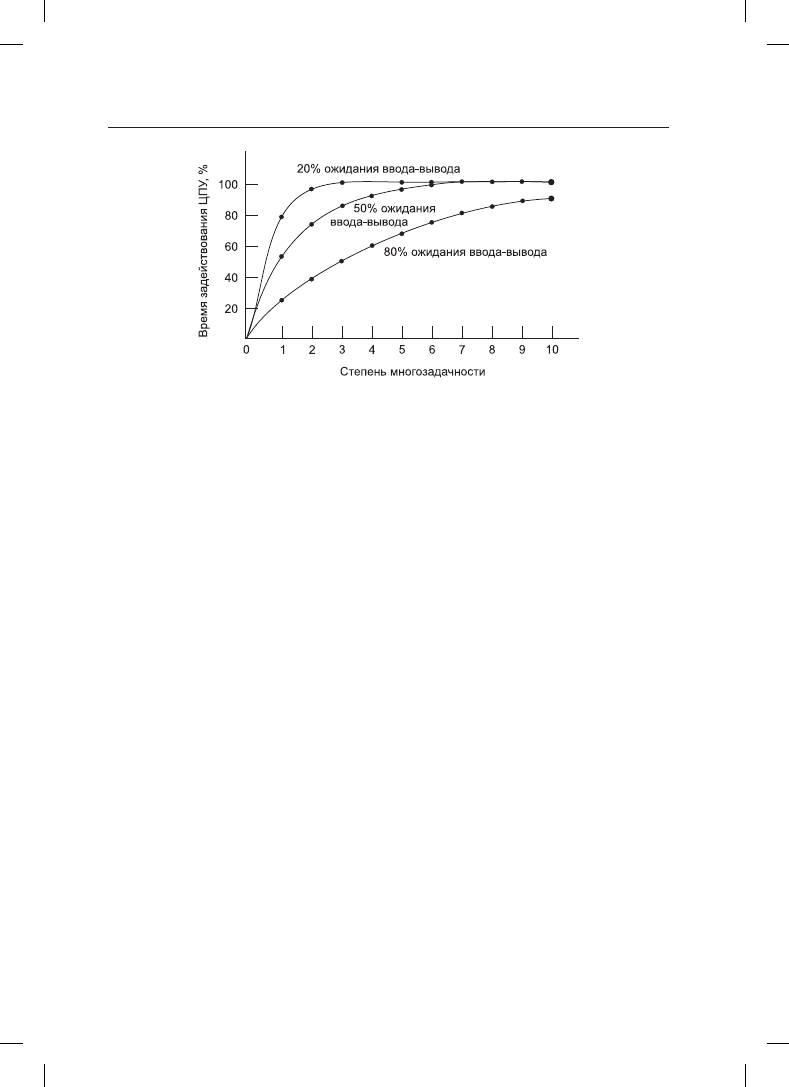
На рис. 2.4 показано время задействования центрального процессора в виде функции
от аргумента n, который называется степенью многозадачности.
Судя по рисунку, если процесс тратит 80 % своего времени на ожидание завершения
ввода-вывода, то для снижения простоя процессора до уровня не более 10 % в памяти
могут одновременно находиться по крайней мере 10 процессов. Когда вы поймете, что
к ожиданию ввода-вывода относится и ожидание интерактивного процесса пользова-
тельского ввода с терминала (или щелчка кнопкой мыши на значке), станет понятно,
что время ожидания завершения ввода-вывода, составляющее 80 % и более, не такая
уж редкость. Но даже на серверах процессы, осуществляющие множество операций
ввода-вывода, зачастую имеют такой же или даже больший процент простоя.
Справедливости ради следует заметить, что рассмотренная нами вероятностная мо-
дель носит весьма приблизительный характер. В ней безусловно предполагается, что
2.2. Потоки
123
Рис. 2.4. Время задействования центрального процессора в виде функции
от количества процессов, присутствующих в памяти
все n процессов являются независимыми друг от друга, а значит, в системе с пятью
процессами в памяти вполне допустимо иметь три выполняемых и два ожидающих
процесса. Но имея один центральный процессор, мы не может иметь сразу три выпол-
няемых процесса, поэтому процесс, который становится готовым к работе при занятом
центральном процессоре, вынужден ожидать своей очереди. Из-за этого процессы не
обладают независимостью. Более точная модель может быть выстроена с использова-
нием теории очередей, но сделанный нами акцент на многозадачность, позволяющую
загружать процессор во избежание его простоя, по-прежнему сохраняется, даже если
реальные кривые немного отличаются от тех, что показаны на рис. 2.4.
Несмотря на упрощенность модели, представленной на рис. 2.4, тем не менее она
может быть использована для специфических, хотя и весьма приблизительных пред-
сказаний, касающихся производительности центрального процессора. Предположим,
к примеру, что память компьютера составляет 8 Гбайт, операционная система и ее
таблицы занимают до 2 Гбайт, а каждая пользовательская программа также занимает
до 2 Гбайт. Этот объем позволяет одновременно разместить в памяти три пользователь-
ские программы. При среднем ожидании ввода-вывода, составляющем 80 % времени,
мы имеем загруженность центрального процессора (если игнорировать издержки на
работу операционной системы), равную 1 – 0,8
3
, или около 49 %. Увеличение объема
памяти еще на 8 Гбайт позволит системе перейти от трехкратной многозадачности
к семикратной, что повысит загруженность центрального процессора до 79 %. Иными
словами, дополнительные 8 Гбайт памяти увеличат его производительность на 30 %.
Увеличение памяти еще на 8 Гбайт поднимет уровень производительности всего лишь
с 79 до 91 %, то есть дополнительный прирост производительности составит толь-
ко 12 %. Используя эту модель, владельцы компьютеров могут прийти к выводу, что
первое наращивание объема памяти, в отличие от второго, станет неплохим вкладом
в повышение производительности процессора.
2.2. Потоки
В традиционных операционных системах у каждого процесса есть адресное про-
странство и единственный поток управления. Фактически это почти что определение

124
Глава 2. Процессы и потоки
процесса. Тем не менее нередко возникают ситуации, когда неплохо было бы иметь
в одном и том же адресном пространстве несколько потоков управления, выполняемых
квазипараллельно, как будто они являются чуть ли не обособленными процессами
(за исключением общего адресного пространства). В следующих разделах будут рас-
смотрены именно такие ситуации и их применение.
2.2.1. Применение потоков
Зачем нам нужна какая-то разновидность процесса внутри самого процесса? Необхо-
димость в подобных мини-процессах, называемых потоками, обусловливается целым
рядом причин. Рассмотрим некоторые из них. Основная причина использования по-
токов заключается в том, что во многих приложениях одновременно происходит не-
сколько действий, часть которых может периодически быть заблокированной. Модель
программирования упрощается за счет разделения такого приложения на несколько
последовательных потоков, выполняемых в квазипараллельном режиме.
Мы уже сталкивались с подобными аргументами. Именно они использовались в под-
держку создания процессов. Вместо того чтобы думать о прерываниях, таймерах и кон-
текстных переключателях, мы можем думать о параллельных процессах. Но только
теперь, рассматривая потоки, мы добавляем новый элемент: возможность использования
параллельными процессами единого адресного пространства и всех имеющихся данных.
Эта возможность играет весьма важную роль для тех приложений, которым не подходит
использование нескольких процессов (с их раздельными адресными пространствами).
Вторым аргументом в пользу потоков является легкость (то есть быстрота) их создания
и ликвидации по сравнению с более «тяжеловесными» процессами. Во многих систе-
мах создание потоков осуществляется в 10–100 раз быстрее, чем создание процессов.
Это свойство особенно пригодится, когда потребуется быстро и динамично изменять
количество потоков.
Третий аргумент в пользу потоков также касается производительности. Когда потоки
работают в рамках одного центрального процессора, они не приносят никакого прироста
производительности, но когда выполняются значительные вычисления, а также значи-
тельная часть времени тратится на ожидание ввода-вывода, наличие потоков позволяет
этим действиям перекрываться по времени, ускоряя работу приложения.
И наконец, потоки весьма полезны для систем, имеющих несколько центральных про-
цессоров, где есть реальная возможность параллельных вычислений. К этому вопросу
мы вернемся в главе 8.
Понять, в чем состоит польза от применения потоков, проще всего на конкретных
примерах. Рассмотрим в качестве первого примера текстовый процессор. Обычно
эти программы отображают создаваемый документ на экране в том виде, в каком он
будет выводиться на печать. В частности, все концы строк и концы страниц находятся
именно там, где они в результате и появятся на бумаге, чтобы пользователь мог при
необходимости их проверить и подправить (например, убрать на странице начальные
и конечные висячие строки, имеющие неэстетичный вид).
Предположим, что пользователь пишет какую-то книгу. С авторской точки зрения про-
ще всего всю книгу иметь в одном файле, облегчая поиск тем, выполнение глобальных
замен и т. д. С другой точки зрения каждая глава могла бы быть отдельным файлом. Но
если каждый раздел и подраздел будут размещаться в отдельных файлах, это принесет
2.2. Потоки
125
массу неудобств, когда понадобится вносить во всю книгу глобальные изменения, по-
скольку тогда придется отдельно и поочередно редактировать сотни файлов. Например,
если предложенный стандарт xxxx одобрен непосредственно перед выходом книги в пе-
чать, то в последнюю минуту все вхождения «Проект стандарта xxxx» нужно заменить
на «Стандарт xxxx». Если вся книга представлена одним файлом, то, как правило, все
замены могут быть произведены с помощью одной команды. А если книга разбита на
более чем 300 файлов, редактированию должен быть подвергнут каждый из них.
Теперь представим себе, что происходит, когда пользователь вдруг удаляет одно пред-
ложение на первой странице 800-страничного документа. Теперь, проверив внесенные
изменения, он хочет внести еще одну поправку на 600-й странице и набирает команду,
предписывающую текстовому процессору перейти на эту страницу (возможно, посред-
ством поиска фразы, которая только там и встречается). Теперь текстовый процессор
вынужден немедленно переформатировать всю книгу вплоть до 600-й страницы, по-
скольку он не знает, какой будет первая строка на 600-й странице, пока не обработает
всех предыдущие страницы. Перед отображением 600-й страницы может произойти
существенная задержка, вызывающая недовольство пользователя.
И здесь на помощь могут прийти потоки. Предположим, что текстовый процессор
написан как двухпоточная программа. Один из потоков взаимодействует с пользо-
вателем, а другой занимается переформатированием в фоновом режиме. Как только
предложение с первой страницы будет удалено, поток, отвечающий за взаимодействие
с пользователем, приказывает потоку, отвечающему за формат, переформатировать всю
книгу. Пока взаимодействующий поток продолжает отслеживать события клавиатуры
и мыши, реагируя на простые команды вроде прокрутки первой страницы, второй
поток с большой скоростью выполняет вычисления. Если немного повезет, то пере-
форматирование закончится как раз перед тем, как пользователь запросит просмотр
600-й страницы, которая тут же сможет быть отображена.
Ну раз уж начали, то почему бы не добавить и третий поток? Многие текстовые про-
цессоры обладают свойством автоматического сохранения всего файла на диск каждые
несколько минут, чтобы уберечь пользователя от утраты его дневной работы в случае
программных или системных сбоев или отключения электропитания. Третий поток
может заниматься созданием резервных копий на диске, не мешая первым двум. Си-
туация, связанная с применением трех потоков, показана на рис. 2.5.
Рис. 2.5. Текстовый процессор, использующий три потока
Если бы программа была рассчитана на работу только одного потока, то с начала
создания резервной копии на диске и до его завершения игнорировались бы команды