Добавлен: 29.10.2018
Просмотров: 48010
Скачиваний: 190

126
Глава 2. Процессы и потоки
с клавиатуры или мыши. Пользователь ощущал бы это как слабую производительность.
Можно было бы сделать так, чтобы события клавиатуры или мыши прерывали созда-
ние резервной копии на диске, позволяя достичь более высокой производительности,
но это привело бы к сложной модели программирования, основанной на применении
прерываний. Программная модель, использующая три потока, гораздо проще. Первый
поток занят только взаимодействием с пользователем. Второй поток по необходимости
занимается переформатированием документа. А третий поток периодически сбрасы-
вает содержимое ОЗУ на диск.
Вполне очевидно, что три отдельных процесса так работать не будут, поскольку с до-
кументом необходимо работать всем трем потокам. Три потока вместо трех процессов
используют общую память, таким образом, все они имеют доступ к редактируемому
документу. При использовании трех процессов такое было бы невозможно.
Аналогичная ситуация складывается во многих других интерактивных программах.
Например, электронная таблица является программой, позволяющей поддерживать
матрицу, данные элементов которой предоставляются пользователем. Остальные
элементы вычисляют исходя из введенных данных с использованием потенциально
сложных формул. Когда пользователь изменяет значение одного элемента, нужно пере-
считывать значения многих других элементов. При использовании потоков пересчета,
работающих в фоновом режиме, поток, взаимодействующий с пользователем, может
позволить последнему, пока идут вычисления, вносить дополнительные изменения.
Подобным образом третий поток может сам по себе периодически сбрасывать на диск
резервные копии.
Рассмотрим еще один пример, где могут пригодиться потоки: сервер для веб-сайта.
Поступают запросы на веб-страницы, и запрошенные страницы отправляются обрат-
но клиентам. На большинстве веб-сайтов некоторые страницы запрашиваются чаще
других. Например, главная страница веб-сайта Sony запрашивается намного чаще,
чем страница, находящаяся глубже, в ответвлении дерева, содержащем техническое
описание какой-нибудь конкретной видеокамеры. Веб-службы используют это об-
стоятельство для повышения производительности за счет размещения содержания
часто используемых страниц в основной памяти, чтобы исключить необходимость
обращаться за ними к диску. Такие подборки называются кэшем и используются
также во многих других случаях. Кэши центрального процессора уже рассматрива-
лись в главе 1.
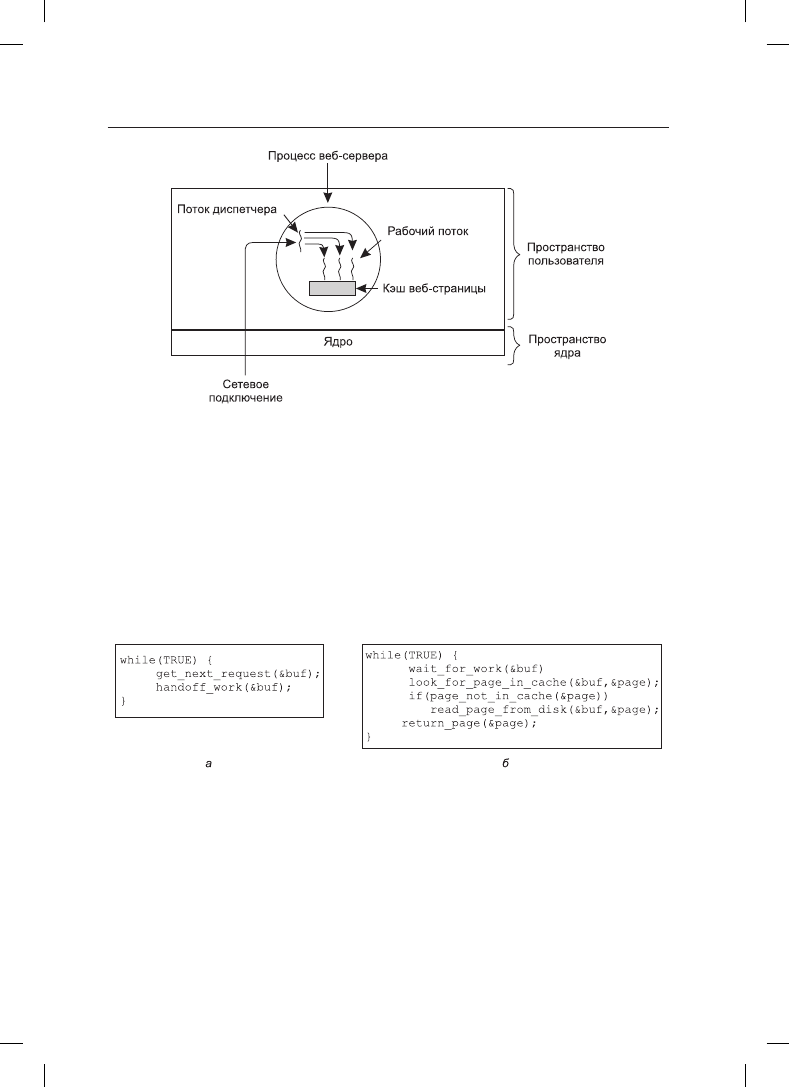
Один из способов организации веб-сервера показан на рис. 2.6. Один из потоков —
диспетчер — читает входящие рабочие запросы из сети. После анализа запроса он
выбирает простаивающий (то есть заблокированный) рабочий поток и передает ему
запрос, возможно, путем записи указателя на сообщение в специальное слово, связан-
ное с каждым потоком. Затем диспетчер пробуждает спящий рабочий поток, переводя
его из заблокированного состояния в состояние готовности.
При пробуждении рабочий поток проверяет, может ли запрос быть удовлетворен из
кэша веб-страниц, к которому имеют доступ все потоки. Если нет, то он, чтобы полу-
чить веб-страницу, приступает к операции чтения с диска и блокируется до тех пор,
пока не завершится дисковая операция. Когда поток блокируется на дисковой опера-
ции, выбирается выполнение другого потока, возможно, диспетчера, с целью полу-
чения следующей задачи или, возможно, другого рабочего потока, который находится
в готовности к выполнению.
2.2. Потоки
127
Рис. 2.6. Многопоточный веб-сервер
Эта модель позволяет запрограммировать сервер в виде коллекции последовательных
потоков. Программа диспетчера состоит из бесконечного цикла для получения рабочего
запроса и перепоручения его рабочему потоку. Код каждого рабочего потока состоит
из бесконечного цикла, в котором принимается запрос от диспетчера и веб-кэш про-
веряется на присутствие в нем страницы. Если страница в кэше, она возвращается кли-
енту. Если нет, поток получает страницу с диска, возвращает ее клиенту и блокируется
в ожидании нового запроса.
Приблизительный набросок кода показан на рис. 2.7. Здесь, как и во всей книге, кон-
станта TRUE предполагается равной 1. Также buf и page являются структурами, пред-
назначенными для хранения рабочего запроса и веб-страницы соответственно.
Рис. 2.7. Приблизительный набросок кода для модели, изображенной на рис. 2.6:
а — для потока-диспетчера; б — для рабочего потока
Рассмотрим, как можно было бы написать код веб-сервера в отсутствие потоков. Мож-
но заставить его работать в виде единого потока. Основной цикл веб-сервера получает
запрос, анализирует его и завершает обработку до получения следующего запроса.
Ожидая завершения дисковой операции, сервер простаивает и не обрабатывает ника-
ких других входящих запросов. Если веб-сервер запущен на специально выделенной
машине, что чаще всего и бывает, то центральный процессор, ожидая завершения
дисковой операции, остается без дела. В итоге происходит значительное сокращение
количества запросов, обрабатываемых в секунду. Таким образом, потоки существенно

128
Глава 2. Процессы и потоки
повышают производительность, но каждый из них программируется последовательно,
то есть обычным способом.
До сих пор мы видели две возможные конструкции: многопоточный и однопоточный
веб-серверы. Представьте, что потоки недоступны, а системные программисты счита-
ют, что потери производительности при использовании одного потока недопустимы.
Если доступна неблокирующая версия системного вызова read, то возможен и третий
подход. При поступлении запроса его анализирует один-единственный поток. Если
запрос может быть удовлетворен из кэша, то все в порядке, но если нет, то стартует
неблокирующая дисковая операция.
Сервер записывает состояние текущего запроса в таблицу, а затем приступает к получе-
нию следующего события. Этим событием может быть либо запрос на новую задачу, либо
ответ от диска, связанный с предыдущей операцией. Если это новая задача, то процесс
приступает к ее выполнению. Если это ответ от диска, то из таблицы выбирается соот-
ветствующая информация и происходит обработка ответа. При использовании неблоки-
рующего ввода-вывода ответ, наверное, должен принять форму сигнала или прерывания.
При такой конструкции модель «последовательного процесса», присутствующая
в первых двух случаях, уже не работает. Состояние вычисления должно быть явным
образом сохранено и восстановлено из таблицы при каждом переключении сервера
с обработки одного запроса на обработку другого. В результате потоки и их стеки
имитируются более сложным образом. Подобная конструкция, в которой у каждого
вычисления есть сохраняемое состояние и имеется некоторый набор событий, которые
могут происходить с целью изменения состояния, называются машиной с конечным
числом состояний
(finite-state machine), или конечным автоматом. Это понятие полу-
чило в вычислительной технике весьма широкое распространение.
Теперь, наверное, уже понятно, чем должны быть полезны потоки. Они дают возмож-
ность сохранить идею последовательных процессов, которые осуществляют блокиру-
ющие системные вызовы (например, для операций дискового ввода-вывода), но при
этом позволяют все же добиться распараллеливания работы. Блокирующие системные
вызовы упрощают программирование, а параллельная работа повышает производитель-
ность. Однопоточные серверы сохраняют простоту блокирующих системных вызовов,
но уступают им в производительности. Третий подход позволяет добиться высокой
производительности за счет параллельной работы, но использует неблокирующие
вызовы и прерывания, усложняя процесс программирования. Сводка моделей при-
ведена в табл. 2.3.
Таблица 2.3. Три способа создания сервера
Модель
Характеристики
Потоки
Параллельная работа, блокирующие системные вызовы
Однопоточный процесс
Отсутствие параллельной работы, блокирующие системные
вызовы
Машина с конечным чис-
лом состояний
Параллельная работа, неблокирующие системные вызовы,
прерывания
Третьим примером, подтверждающим пользу потоков, являются приложения, предна-
значенные для обработки очень большого объема данных. При обычном подходе блок

2.2. Потоки
129
данных считывается, после чего обрабатывается, а затем снова записывается. Проблема
в том, что при доступности лишь блокирующих вызовов процесс блокируется и при по-
ступлении данных, и при их возвращении. Совершенно ясно, что простой центрального
процесса при необходимости в большом объеме вычислений слишком расточителен
и его по возможности следует избегать.
Проблема решается с помощью потоков. Структура процесса может включать входной
поток, обрабатывающий поток и выходной поток. Входной поток считывает данные
во входной буфер. Обрабатывающий поток извлекает данные из входного буфера, об-
рабатывает их и помещает результат в выходной буфер. Выходной буфер записывает
эти результаты обратно на диск. Таким образом, ввод, вывод и обработка данных могут
осуществляться одновременно. Разумеется, эта модель работает лишь при том условии,
что системный вызов блокирует только вызывающий поток, а не весь процесс.
2.2.2. Классическая модель потоков
Разобравшись в пользе потоков и в порядке их использования, давайте рассмотрим их
применение более пристально. Модель процесса основана на двух независимых поня-
тиях: группировке ресурсов и выполнении. Иногда их полезно отделить друг от друга,
и тут на первый план выходят потоки. Сначала будет рассмотрена классическая модель
потоков, затем изучена модель потоков, используемая в Linux, которая размывает грань
между процессами и потоками.
Согласно одному из взглядов на процесс, он является способом группировки в единое
целое взаимосвязанных ресурсов. У процесса есть адресное пространство, содержащее
текст программы и данные, а также другие ресурсы. Эти ресурсы могут включать от-
крытые файлы, необработанные аварийные сигналы, обработчики сигналов, учетную
информацию и т. д. Управление этими ресурсами можно значительно облегчить, если
собрать их воедино в виде процесса.
Другое присущее процессу понятие — поток выполнения — обычно сокращается до слова
поток
. У потока есть счетчик команд, отслеживающий, какую очередную инструкцию
нужно выполнять. У него есть регистры, в которых содержатся текущие рабочие пере-
менные. У него есть стек с протоколом выполнения, содержащим по одному фрейму для
каждой вызванной, но еще не возвратившей управление процедуры. Хотя поток может
быть выполнен в рамках какого-нибудь процесса, сам поток и его процесс являются раз-
ными понятиями и должны рассматриваться по отдельности. Процессы используются
для группировки ресурсов в единое образование, а потоки являются «сущностью», рас-
пределяемой для выполнения на центральном процессоре.
Потоки добавляют к модели процесса возможность реализации нескольких в зна-
чительной степени независимых друг от друга выполняемых задач в единой среде
процесса. Наличие нескольких потоков, выполняемых параллельно в рамках одного
процесса, является аналогией наличия нескольких процессов, выполняемых парал-
лельно на одном компьютере. В первом случае потоки используют единое адресное
пространство и другие ресурсы. А в последнем случае процессы используют общую
физическую память, диски, принтеры и другие ресурсы. Поскольку потоки обладают
некоторыми свойствами процессов, их иногда называют облегченными процессами.
Термин «многопоточный режим» также используется для описания ситуации, при
которой допускается работа нескольких потоков в одном и том же процессе. В главе 1
было показано, что некоторые центральные процессоры обладают непосредственной
130
Глава 2. Процессы и потоки
аппаратной поддержкой многопоточного режима и проводят переключение потоков
за наносекунды.
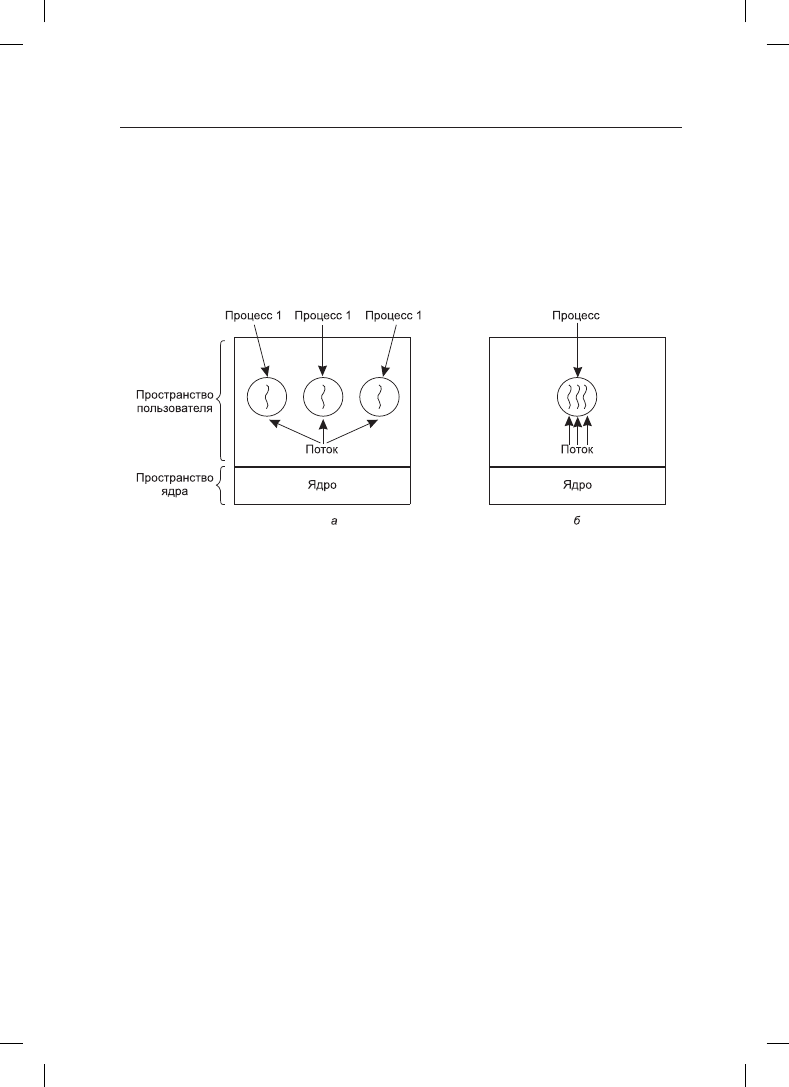
На рис. 2.8, а показаны три традиционных процесса. У каждого из них имеется соб-
ственное адресное пространство и единственный поток управления. В отличие от этого,
на рис. 2.8, б показан один процесс, имеющий три потока управления. Хотя в обоих
случаях у нас имеется три потока, на рис. 2.8, а каждый из них работает в собственном
адресном пространстве, а на рис. 2.8, б все три потока используют общее адресное про-
странство.
Рис. 2.8. а — три процесса, у каждого из которых по одному потоку;
б — один процесс с тремя потоками
Когда многопоточный процесс выполняется на однопроцессорной системе, потоки
выполняются, сменяя друг друга. На рис. 2.1 мы видели работу процессов в многозадач-
ном режиме. За счет переключения между несколькими процессами система создавала
иллюзию параллельно работающих отдельных последовательных процессов. Много-
поточный режим осуществляется аналогичным способом. Центральный процессор
быстро переключается между потоками, создавая иллюзию, что потоки выполняются
параллельно, пусть даже на более медленном центральном процессоре, чем реально ис-
пользуемый. При наличии в одном процессе трех потоков, ограниченных по скорости
вычисления, будет казаться, что потоки выполняются параллельно и каждый из них
выполняется на центральном процессоре, имеющем скорость, которая составляет одну
треть от скорости реального процессора.
Различные потоки в процессе не обладают той независимостью, которая есть у различ-
ных процессов. У всех потоков абсолютно одно и то же адресное пространство, а значит,
они так же совместно используют одни и те же глобальные переменные. Поскольку
каждый поток может иметь доступ к любому адресу памяти в пределах адресного
пространства процесса, один поток может считывать данные из стека другого потока,
записывать туда свои данные и даже стирать оттуда данные. Защита между потоками
отсутствует, потому что ее невозможно осуществить и в ней нет необходимости. В от-
личие от различных процессов, которые могут принадлежать различным пользователям
и которые могут враждовать друг с другом, один процесс всегда принадлежит одному
и тому же пользователю, который, по-видимому, и создал несколько потоков для их
совместной работы, а не для вражды. В дополнение к использованию общего адресного