Добавлен: 29.10.2018
Просмотров: 48107
Скачиваний: 190

4.3. Реализация файловой системы
321
вся информация о файле. Затем может размещаться корневой каталог, содержащий
вершину дерева файловой системы. И наконец, оставшаяся часть диска содержит все
остальные каталоги и файлы.
4.3.2. Реализация файлов
Возможно, самым важным вопросом при реализации файлового хранилища является
отслеживание соответствия файлам блоков на диске. В различных операционных
системах используются разные методы. Некоторые из них будут рассмотрены в этом
разделе.
Непрерывное размещение
Простейшая схема размещения заключается в хранении каждого файла на диске в виде
непрерывной последовательности блоков. Таким образом, на диске с блоками, имею-
щими размер 1 Кбайт, файл размером 50 Кбайт займет 50 последовательных блоков.
При блоках, имеющих размер 2 Кбайт, под него будет выделено 25 последовательных
блоков.
Пример хранилища с непрерывным размещением приведен на рис. 4.7, а. На нем по-
казаны 40 первых блоков, начинающихся с блока 0 слева. Изначально диск был пустым.
Затем на него начиная с блока 0 был записан файл A длиной четыре блока. Затем правее
окончания файла A записан файл B, занимающий шесть блоков.
Следует заметить, что каждый файл начинается от границы нового блока, поэтому,
если файл A фактически имел длину 3,5 блока, то в конце последнего блока часть про-
странства будет потеряна впустую. Всего на рисунке показаны семь файлов, каждый
Рис. 4.7. Дисковое пространство: а — непрерывное размещение семи файлов;
б — состояние диска после удаления файлов D и F

322
Глава 4. Файловые системы
из которых начинается с блока, который следует за последним блоком предыдущего
файла. Затенение использовано только для того, чтобы упростить показ деления про-
странства на файлы. В отношении самого хранилища оно не имеет никакого практи-
ческого значения.
У непрерывного распределения дискового пространства есть два существенных пре-
имущества. Во-первых, его просто реализовать, поскольку отслеживание местонахож-
дения принадлежащих файлу блоков сводится всего лишь к запоминанию двух чисел:
дискового адреса первого блока и количества блоков в файле. При наличии номера
первого блока номер любого другого блока может быть вычислен путем простого
сложения.
Во-вторых, у него превосходная производительность считывания, поскольку весь файл
может быть считан с диска за одну операцию. Для нее потребуется только одна опе-
рация позиционирования (на первый блок). После этого никаких позиционирований
или ожиданий подхода нужного сектора диска уже не потребуется, поэтому данные
поступают на скорости, равной максимальной пропускной способности диска. Таким
образом, непрерывное размещение характеризуется простотой реализации и высокой
производительностью.
К сожалению, у непрерывного размещения есть также очень серьезный недостаток:
со временем диск становится фрагментированным. Как это происходит, показано на
рис. 4.7, б. Были удалены два файла — D и F. Естественно, при удалении файла его
блоки освобождаются и на диске остается последовательность свободных блоков.
Немедленное уплотнение файлов на диске для устранения такой последовательности
свободных блоков («дыры») не осуществляется, поскольку для этого потребуется
скопировать все блоки, — а их могут быть миллионы, — следующие за ней, что при
использовании больших дисков займет несколько часов или даже дней. В результате,
как показано на рис. 4.7, б, диск содержит вперемешку файлы и последовательности
свободных блоков.
Сначала фрагментация не составляет проблемы, поскольку каждый новый файл мо-
жет быть записан в конец диска, следуя за предыдущим файлом. Но со временем диск
заполнится и понадобится либо его уплотнить, что является слишком затратной опе-
рацией, либо повторно использовать последовательности свободных блоков между
файлами, для чего потребуется вести список таких свободных участков, что вполне
возможно осуществить. Но при создании нового файла необходимо знать его окон-
чательный размер, чтобы выбрать подходящий для размещения участок.
Представьте себе последствия использования такого подхода. Пользователь запускает
текстовый процессор, чтобы создать документ. В первую очередь программа спраши-
вает, сколько байтов в конечном итоге будет занимать документ. Без ответа на этот
вопрос она не сможет продолжить работу. Если в конце выяснится, что указан слишком
маленький размер, программа будет вынуждена преждевременно прекратить свою
работу, поскольку выбранная область на диске будет заполнена и остаток файла туда
просто не поместится. Если пользователь попытается обойти эту проблему, задавая
заведомо большой конечный объем, скажем, 1 Гбайт, редактор может и не найти столь
большой свободной области и объявит, что файл создать нельзя. Разумеется, ничто не
помешает пользователю запустить программу повторно и задать на сей раз 500 Мбайт
и т. д., пока не будет найдена подходящая свободная область. Но такая система вряд ли
осчастливит пользователей.
4.3. Реализация файловой системы
323
Тем не менее есть одна сфера применения, в которой непрерывное размещение впол-
не приемлемо и все еще используется на практике, — это компакт-диски. Здесь все
размеры файлов известны заранее и никогда не изменяются в процессе дальнейшего
использования файловой системы компакт-диска.
С DVD ситуация складывается несколько сложнее. В принципе, 90-минутный фильм
может быть закодирован в виде одного-единственного файла длиной около 4,5 Гбайт,
но в используемой файловой системе UDF (Universal Disk Format — универсальный
формат диска) для представления длины файла применяется 30-разрядное число, кото-
рое ограничивает длину файлов одним гигабайтом. Вследствие этого DVD-фильмы, как
правило, хранятся в виде трех-четырех файлов размером 1 Гбайт, каждый из которых
является непрерывным. Такие физические части одного логического файла (фильма)
называются экстентами.
Как говорилось в главе 1, в вычислительной технике при появлении технологии нового
поколения история часто повторяется. Непрерывное размещение благодаря своей про-
стоте и высокой производительности использовалось в файловых системах магнитных
дисков много лет назад (удобство для пользователей в то время еще не было в цене).
Затем из-за необходимости задания конечного размера файла при его создании эта идея
была отброшена. Но неожиданно с появлением компакт-дисков, DVD, Blu-ray-дисков
и других однократно записываемых оптических носителей непрерывные файлы снова
оказались весьма кстати. Поэтому столь важное значение имеет изучение старых си-
стем и идей, обладающих концептуальной ясностью и простотой, поскольку они могут
пригодиться для будущих систем совершенно неожиданным образом.
Размещение с использованием связанного списка
Второй метод хранения файлов заключается в представлении каждого файла в виде
связанного списка дисковых блоков (рис. 4.8). Первое слово каждого блока исполь-
зуется в качестве указателя на следующий блок, а вся остальная часть блока предна-
значается для хранения данных.
Рис. 4.8. Хранение файла в виде связанного списка дисковых блоков

324
Глава 4. Файловые системы
В отличие от непрерывного размещения, в этом методе может быть использован
каждый дисковый блок. При этом потери дискового пространства на фрагментацию
отсутствуют (за исключением внутренней фрагментации в последнем блоке). Кроме
того, достаточно, чтобы в записи каталога хранился только дисковый адрес первого
блока. Всю остальную информацию можно найти начиная с этого блока.
В то же время по сравнению с простотой последовательного чтения файла произволь-
ный доступ является слишком медленным. Чтобы добраться до блока n, операционной
системе нужно начать со стартовой позиции и прочитать поочередно n − 1 предше-
ствующих блоков. Понятно, что осуществление стольких операций чтения окажется
мучительно медленным.
К тому же объем хранилища данных в блоках уже не кратен степени числа 2, поскольку
несколько байтов отнимает указатель. Хотя это и не смертельно, но необычный размер
менее эффективен, поскольку многие программы ведут чтение и запись блоками, раз-
мер которых кратен степени числа 2. Когда первые несколько байтов каждого блока
заняты указателем на следующий блок, чтение полноценного блока требует получения
и соединения информации из двух дисковых блоков, из-за чего возникают дополни-
тельные издержки при копировании.
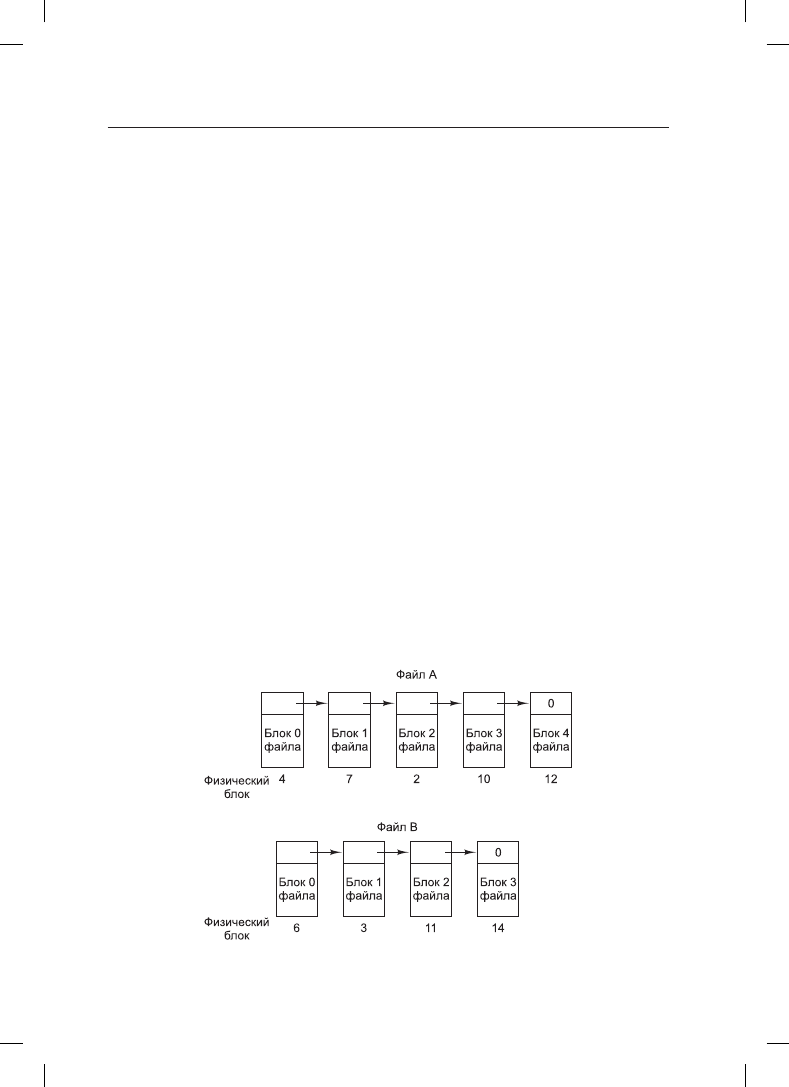
Размещение с помощью связанного списка,
использующего таблицу в памяти
Оба недостатка размещения с помощью связанных списков могут быть устранены за
счет изъятия слова указателя из каждого дискового блока и помещения его в таблицу
в памяти. На рис. 4.9 показано, как выглядит таблица для примера, приведенного на
рис. 4.8. На обоих рисунках показаны два файла. Файл A использует в указанном по-
рядке дисковые блоки 4, 7, 2, 10 и 12, а файл B — блоки 6, 3, 11 и 14. Используя таблицу,
показанную на рис. 4.9, можно пройти всю цепочку от начального блока 4 до самого
конца. То же самое можно проделать начиная с блока 6. Обе цепочки заканчиваются
специальным маркером (например, –1), который не является допустимым номером
блока. Такая таблица, находящаяся в оперативной памяти, называется FAT (File
Allocation Table — таблица размещения файлов).
При использовании такой организации для данных доступен весь блок. Кроме того, на-
много упрощается произвольный доступ. Хотя для поиска заданного смещения в файле
по-прежнему нужно идти по цепочке, эта цепочка целиком находится в памяти, поэто-
му проход по ней может осуществляться без обращений к диску. Как и в предыдущем
методе, в записи каталога достаточно хранить одно целое число (номер начального
блока) и по-прежнему получать возможность определения местоположения всех бло-
ков независимо от того, насколько большим будет размер файла.
Основным недостатком этого метода является то, что для его работы вся таблица
должна постоянно находиться в памяти. Для 1-терабайтного диска, имеющего блоки
размером 1 Кбайт, потребовалась бы таблица из 1 млрд записей, по одной для каждого
из 1 млрд дисковых блоков. Каждая запись должна состоять как минимум из 3 байт.
Для ускорения поиска размер записей должен быть увеличен до 4 байт. Таким об-
разом, таблица будет постоянно занимать 3 Гбайт или 2,4 Гбайт оперативной памяти
в зависимости от того, как оптимизирована система, под экономию пространства или
под экономию времени, что с практической точки зрения выглядит не слишком при-
влекательно. Становится очевидным, что идея FAT плохо масштабируется на диски

4.3. Реализация файловой системы
325
Рис. 4.9. Размещение с помощью связанного списка, использующего таблицу
размещения файлов в оперативной памяти
больших размеров. Изначально это была файловая система MS-DOS, но она до сих пор
полностью поддерживается всеми версиями Windows.
I-узлы
Последним из рассматриваемых методов отслеживания принадлежности конкретного
блока конкретному файлу является связь с каждым файлом структуры данных, назы-
ваемой i-узлом (index-node — индекс-узел), содержащей атрибуты файла и дисковые
адреса его блоков. Простой пример приведен на рис. 4.10. При использовании i-узла
появляется возможность найти все блоки файла. Большим преимуществом этой схе-
мы перед связанными списками, использующими таблицу в памяти, является то, что
i-узел должен быть в памяти только в том случае, когда открыт соответствующий файл.
Если каждый i-узел занимает n байт, а одновременно может быть открыто максимум
k файлов, общий объем памяти, занимаемой массивом, хранящим i-узлы открытых
файлов, составляет всего лишь kn байт. Заранее нужно будет зарезервировать только
этот объем памяти.
Обычно этот массив значительно меньше того пространства, которое занимает таблица
расположения файлов, рассмотренная в предыдущем разделе. Причина проста. Табли-
ца, предназначенная для хранения списка всех дисковых блоков, пропорциональна
размеру самого диска. Если диск имеет n блоков, то таблице нужно n записей. Она
растет пропорционально росту размера диска. В отличие от этого, для схемы, исполь-
зующей i-узлы, нужен массив в памяти, чей размер пропорционален максимальному
количеству одновременно открытых файлов. При этом неважно, будет ли размер диска
100, 1000 или 10 000 Гбайт.