Добавлен: 29.10.2018
Просмотров: 48109
Скачиваний: 190

326
Глава 4. Файловые системы
Рис. 4.10. Пример i-узла
С i-узлами связана одна проблема: если каждый узел имеет пространство для фикси-
рованного количества дисковых адресов, то что произойдет, когда файл перерастет
этот лимит? Одно из решений заключается в резервировании последнего дискового
адреса не для блока данных, а для блока, содержащего дополнительные адреса блоков
(см. рис. 4.10). Более того, можно создавать целые цепочки или даже деревья адрес-
ных блоков, поскольку их может понадобиться два или более. Может потребоваться
даже дисковый блок, указывающий на другие, полные адресов дисковые блоки. Мы
еще вернемся к i-узлам при изучении системы UNIX в главе 10. По аналогии с этим
в файловой системе Windows NTFS используется такая же идея, но только с более
крупными i-узлами, в которых также могут содержаться небольшие файлы.
4.3.3. Реализация каталогов
Перед тем как прочитать файл, его нужно открыть. При открытии файла операционная
система использует предоставленное пользователем имя файла для определения место-
положения соответствующей ему записи каталога на диске. Эта запись предоставляет
информацию, необходимую для поиска на диске блоков, занятых данным файлом. В за-
висимости от применяемой системы эта информация может быть дисковым адресом
всего файла (с непрерывным размещением), номером первого блока (для обеих схем,
использующих связанные списки) или номером i-узла. Во всех случаях основной функ-
цией системы каталогов является преобразование ASCII-имени файла в информацию,
необходимую для определения местоположения данных.
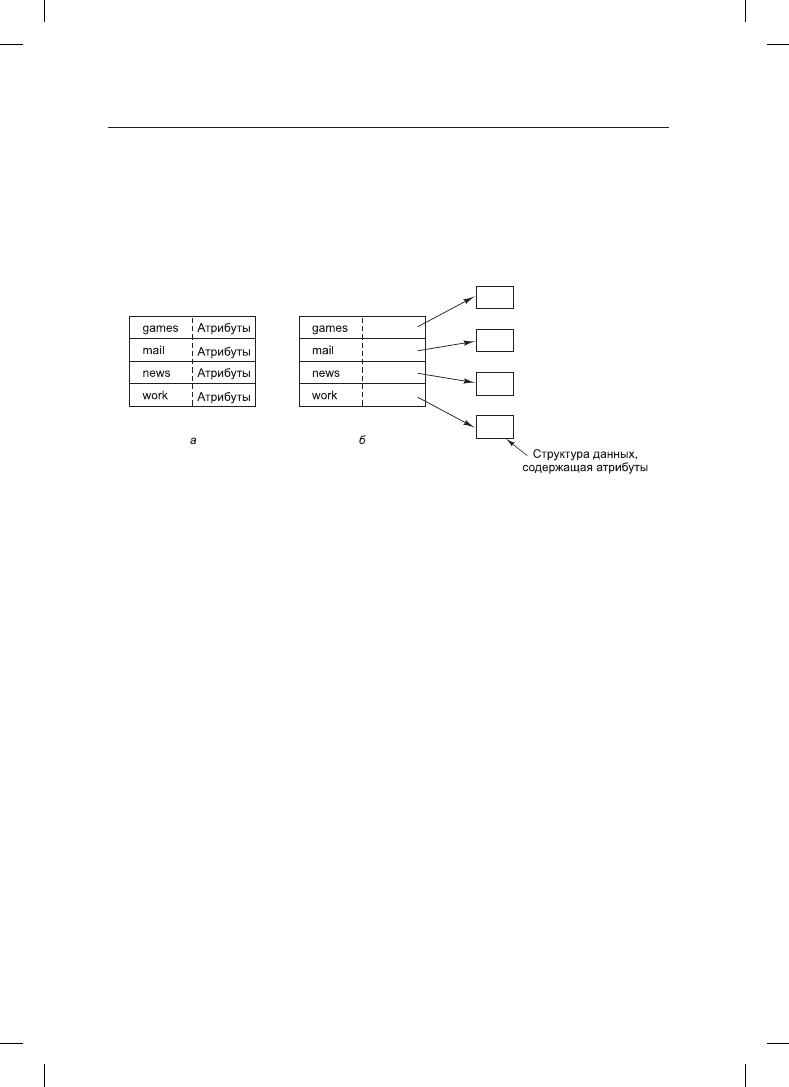
Со всем этим тесно связан вопрос: где следует хранить атрибуты? Каждая файловая
система работает с различными атрибутами файлов, такими как имя владельца файла
4.3. Реализация файловой системы
327
и время создания, и их нужно где-то хранить. Одна из очевидных возможностей заклю-
чается в хранении их непосредственно в записи каталога. Именно так некоторые систе-
мы и делают. Этот вариант показан на рис. 4.11, а. В этой простой конструкции каталог
состоит из списка записей фиксированного размера, по одной записи на каждый файл,
в которой содержатся имя файла (фиксированной длины), структура атрибутов файла,
а также один или несколько дисковых адресов (вплоть до некоторого максимума), со-
общающих, где находятся соответствующие файлу блоки на диске.
Рис. 4.11. Каталог: а — содержит записи фиксированного размера с дисковыми адресами
и атрибутами; б — каждая запись всего лишь ссылается на i-узел
Для систем, использующих i-узлы, имеется возможность хранить атрибуты в самих
i-узлах. При этом запись каталога может быть укорочена до имени файла и номера
i-узла. Этот вариант изображен на рис. 4.11, б. Позже мы увидим, что этот метод имеет
некоторые преимущества перед методом размещения атрибутов в записи каталога.
До сих пор мы предполагали, что файлы имеют короткие имена фиксированной
длины. В MS-DOS у файлов имелось основное имя, состоящее из 1–8 символов, и не-
обязательное расширение имени, состоящее из 1–3 символов. В UNIX версии 7 имена
файлов состояли из 1–14 символов, включая любые расширения. Но практически
все современные операционные системы поддерживают длинные имена переменной
длины. Как это может быть реализовано?
Проще всего установить предел длины имени файла — как правило, он составляет
255 символов, — а затем воспользоваться одной из конструкций, показанных на
рис. 4.11, отводя по 255 символов под каждое имя. Этот подход при всей своей простоте
ведет к пустой трате пространства, занимаемого каталогом, поскольку такие длинные
имена бывают далеко не у всех файлов. Из соображений эффективности нужно ис-
пользовать какую-то другую структуру.
Один из альтернативных подходов состоит в отказе от предположения о том, что все
записи в каталоге должны иметь один и тот же размер. При таком подходе каждая
запись в каталоге начинается с порции фиксированного размера, обычно начинаю-
щейся с длины записи, за которой следуют данные в фиксированном формате, чаще
всего включающие идентификатор владельца, дату создания, информацию о защите
и прочие атрибуты. Следом за заголовком фиксированной длины идет часть запи-
си переменной длины, содержащая имя файла, каким бы длинным оно ни было
(рис. 4.12, а), с определенным для данной системы порядком следования байтов
в словах (например, для SPARC — начиная со старшего). В приведенном примере

328
Глава 4. Файловые системы
показаны три файла:
project-budget
,
personnel
и
foo
. Имя каждого файла завершается
специальным символом (обычно 0), обозначенным на рисунке перечеркнутыми ква-
дратиками. Чтобы каждая запись в каталоге могла начинаться с границы слова, имя
каждого файла дополняется до целого числа слов байтами, показанными на рисунке
закрашенными прямоугольниками.
Рис. 4.12. Два способа реализации длинных имен в каталоге: a — непосредственно в записи;
б — в общем хранилище имен (куче)
Недостаток этого метода состоит в том, что при удалении файла в каталоге остается
промежуток произвольной длины, в который описатель следующего файла может и не
поместиться. Эта проблема по сути аналогична проблеме хранения на диске непре-
рывных файлов, только здесь уплотнение каталога вполне осуществимо, поскольку
он полностью находится в памяти. Другая проблема состоит в том, что какая-нибудь
запись каталога может разместиться на нескольких страницах памяти и при чтении
имени файла может произойти ошибка отсутствия страницы.
Другой метод реализации имен файлов переменной длины заключается в том, чтобы
сделать сами записи каталога фиксированной длины, а имена файлов хранить отдель-
но в общем хранилище (куче) в конце каталога (рис. 4.12, б). Преимущество этого
метода состоит в том, что при удалении записи в каталоге (при удалении файла) на ее
место всегда сможет поместиться запись другого файла. Но общим хранилищем имен
по-прежнему нужно будет управлять, и при обработке имен файлов все так же могут
происходить ошибки отсутствия страниц. Небольшой выигрыш заключается в том,
что уже не нужно, чтобы имена файлов начинались на границе слов, поэтому отпадает
надобность в символах-заполнителях после имен файлов, показанных на рис. 4.12, б,
в отличие от тех имен, которые показаны на рис. 4.12, а.

4.3. Реализация файловой системы
329
При всех рассмотренных до сих пор подходах к организации каталогов, когда нужно
найти имя файла, поиск в каталогах ведется линейно, от начала до конца. Линейный
поиск в очень длинных каталогах может выполняться довольно медленно. Ускорить по-
иск поможет присутствие в каждом каталоге хэш-таблицы. Пусть размер такой таблицы
будет равен n. При добавлении в каталог нового имени файла оно должно хэшироваться
в число от 0 до n – 1, к примеру, путем деления его на n и взятия остатка. В качестве
альтернативы можно сложить слова, составляющие имя файла, и получившуюся сумму
разделить на n или сделать еще что-либо подобное
1
.
В любом случае просматривается элемент таблицы, соответствующий полученному
хэш-коду. Если элемент не используется, туда помещается указатель на запись о файле.
Эти записи следуют сразу за хэш-таблицей. Если же элемент таблицы уже занят, то
создается связанный список, объединяющий все записи о файлах, имеющих одинако-
вые хэш-коды, и заголовок этого списка помещается в элемент таблицы.
При поиске файла производится такая же процедура. Для выбора записи в хэш-таблице
имя файла хэшируется. Затем на присутствие имени файла проверяются все записи
в цепочке, чей заголовок помещен в элементе таблицы. Если искомое имя файла в этой
цепочке отсутствует, значит, в каталоге файла с таким именем нет.
Преимущество использования хэш-таблицы состоит в существенном увеличении ско-
рости поиска, а недостаток заключается в усложнении процесса администрирования.
Рассматривать применение хэш-таблицы стоит только в тех системах, где ожидается
применение каталогов, содержащих сотни или тысячи файлов.
Другим способом ускорения поиска в больших каталогах является кэширование ре-
зультатов поиска. Перед началом поиска проверяется присутствие имени файла в кэше.
Если оно там есть, то местонахождение файла может быть определено немедленно.
Разумеется, кэширование поможет, только если результаты поиска затрагивают от-
носительно небольшое количество файлов.
4.3.4. Совместно используемые файлы
Когда над проектом вместе работают несколько пользователей, зачастую возникает
потребность в совместном использовании файлов. Поэтому нередко представляется
удобным, чтобы совместно используемые файлы одновременно появлялись в различ-
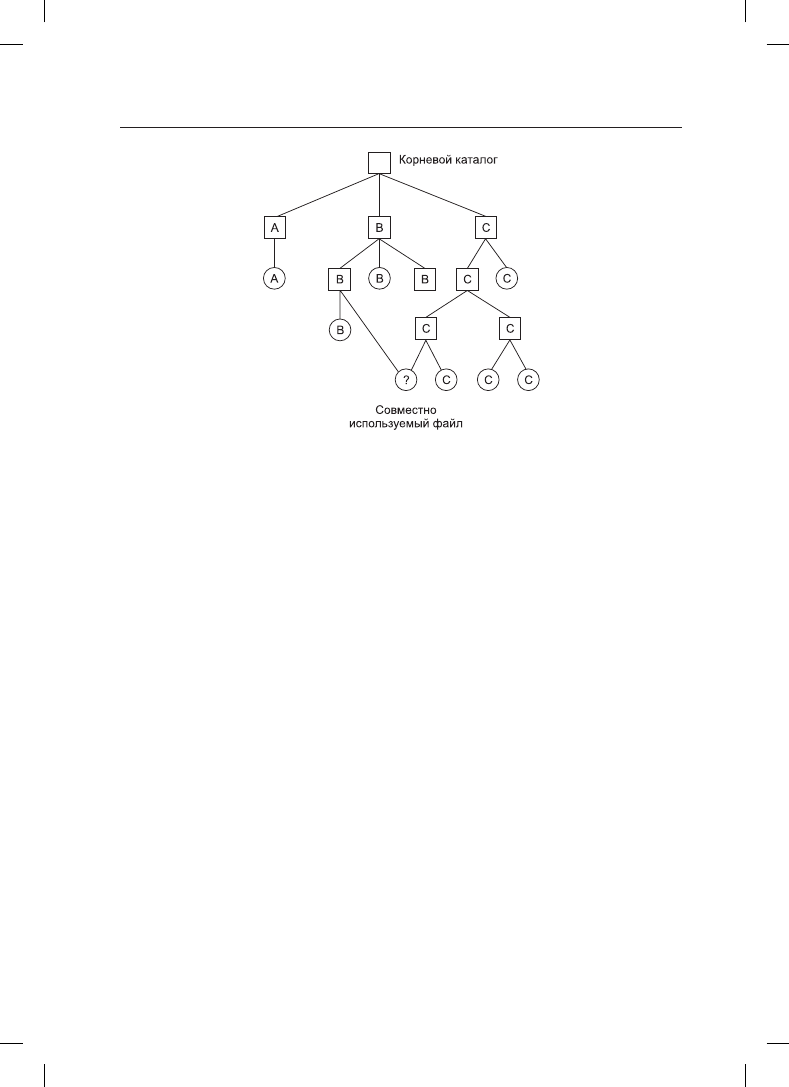
ных каталогах, принадлежащих разным пользователям. На рис. 4.13 еще раз показана
файловая система, изображенная на рис. 4.4, только теперь один из файлов, принад-
лежащих пользователю C, представлен также в одном из каталогов, принадлежащих
пользователю B. Установленное при этом отношение между каталогом, принадлежа-
щим B, и совместно используемыми файлами называется связью. Теперь сама фай-
ловая система представляет собой не дерево, а ориентированный ациклический граф
(Directed Acyclic Graph (DAG)). Потребность в том, чтобы файловая система была
представлена как DAG, усложняет ее обслуживание, но такова жизнь.
1
Иными словами, производится отображение символьного имени файла в целое число из
требуемого диапазона по некоторому алгоритму, рассматривающему имя как некоторое
число (битовую строку) или последовательность чисел (например, кодов символов и т. п.).
При этом такое преобразование не является взаимно-однозначным. — Примеч. ред.
330
Глава 4. Файловые системы
Рис. 4.13. Файловая система, содержащая совместно используемый файл
При всем удобстве совместное использование файлов вызывает ряд проблем. Для
начала следует заметить: если собственно каталоги содержат адреса всех дисковых
блоков файла, то при установке связи с файлом они должны быть скопированы в ка-
талог, принадлежащий пользователю B. Если кто-либо из пользователей, B или C,
чуть позже добавит к файлу какие-то новые данные, то новые блоки попадут в список
каталога, принадлежащего только тому пользователю, который производил дополне-
ние. Другому пользователю изменения будут не видны, и совместное использование
потеряет всякий смысл.
Эта проблема может быть решена двумя способами. Первое решение заключается
в том, что дисковые блоки не указываются в каталогах. Вместо этого с самим файлом
связывается некоторая небольшая структура данных. В этом случае каталоги должны
лишь указывать на эту структуру данных. Такой подход используется в UNIX (где
в качестве такой структуры данных выступает i-узел).
Второе решение заключается в том, что каталог пользователя B привязывается к од-
ному из файлов пользователя C, заставляя систему создать новый файл типа LINK
и включить этот файл в каталог пользователя B. Новый файл содержит только имя того
файла, с которым он связан. Когда пользователь B читает данные из связанного файла,
операционная система видит, что файл, из которого они считываются, относится к типу
LINK, находит в нем имя файла и читает данные из этого файла. Этот подход в отличие
от традиционной (жесткой) связи называется символической ссылкой.
У каждого из этих методов имеются недостатки. В первом методе, когда пользова-
тель B устанавливает связь с совместно используемым файлом, в i-узле владельцем
файла числится пользователь C. Создание связи не приводит к изменению владельца
(рис. 4.14), а увеличивает показания счетчика связей в i-узле, благодаря чему система
знает, сколько записей в каталогах указывает на файл в данный момент.
Если впоследствии пользователь C попытается удалить файл, система сталкивается
с проблемой. Если она удаляет файл и очищает i-узел, то в каталоге у пользователя B
будет запись, указывающая на неверный i-узел. Если i-узел чуть позже будет назначен