Добавлен: 29.10.2018
Просмотров: 48112
Скачиваний: 190
336
Глава 4. Файловые системы
4.3.7. Виртуальные файловые системы
Люди пользуются множеством файловых систем, зачастую на одном и том же компью-
тере и даже для одной и той же операционной системы. Система Windows может иметь
не только основную файловую систему NTFS, но и устаревшие приводы или разделы
с файловой системой FAT-32 или FAT-16, на которых содержатся старые, но все еще
нужные данные, а время от времени могут понадобиться также флеш-накопитель,
старый компакт-диск или DVD (каждый со своей уникальной файловой системой).
Windows работает с этими совершенно разными файловыми системами, идентифици-
руя каждую из них по разным именам дисководов, таким как
C:
,
D:
и т. д. Когда про-
цесс открывает файл, имя дисковода фигурирует в явном или неявном виде, поэтому
Windows знает, какой именно файловой системе передать запрос. Интегрировать
разнородные файловые системы в одну унифицированную никто даже не пытается.
В отличие от этого для всех современных систем UNIX предпринимаются весьма се-
рьезные попытки интегрировать ряд файловых систем в единую структуру. У систем
Linux в качестве корневой файловой системы может выступать ext2, и она может иметь
ext3-раздел, подключенный к каталогу
/usr
, и второй жесткий диск, имеющий файловую
систему ReiserFS, подключенный к каталогу
/home
, а также компакт-диск, отвечающий
стандарту ISO 9660, временно подключенный к каталогу
/mnt
. С пользовательской точки
зрения это будет единая иерархическая файловая система, поскольку объединение не-
скольких несовместимых файловых систем невидимо для пользователей или процессов.
Существование нескольких файловых систем становится необходимостью, и начиная
с передовой разработки Sun Microsystems (Kleiman, 1986) большинство UNIX-систем,
пытаясь интегрировать несколько файловых систем в упорядоченную структуру, ис-
пользовали концепцию виртуальной файловой системы (virtual file system (VFS)).
Ключевая идея состоит в том, чтобы выделить какую-то часть файловой системы, яв-
ляющуюся общей для всех файловых систем, и поместить ее код на отдельный уровень,
из которого вызываются расположенные ниже конкретные файловые системы с целью
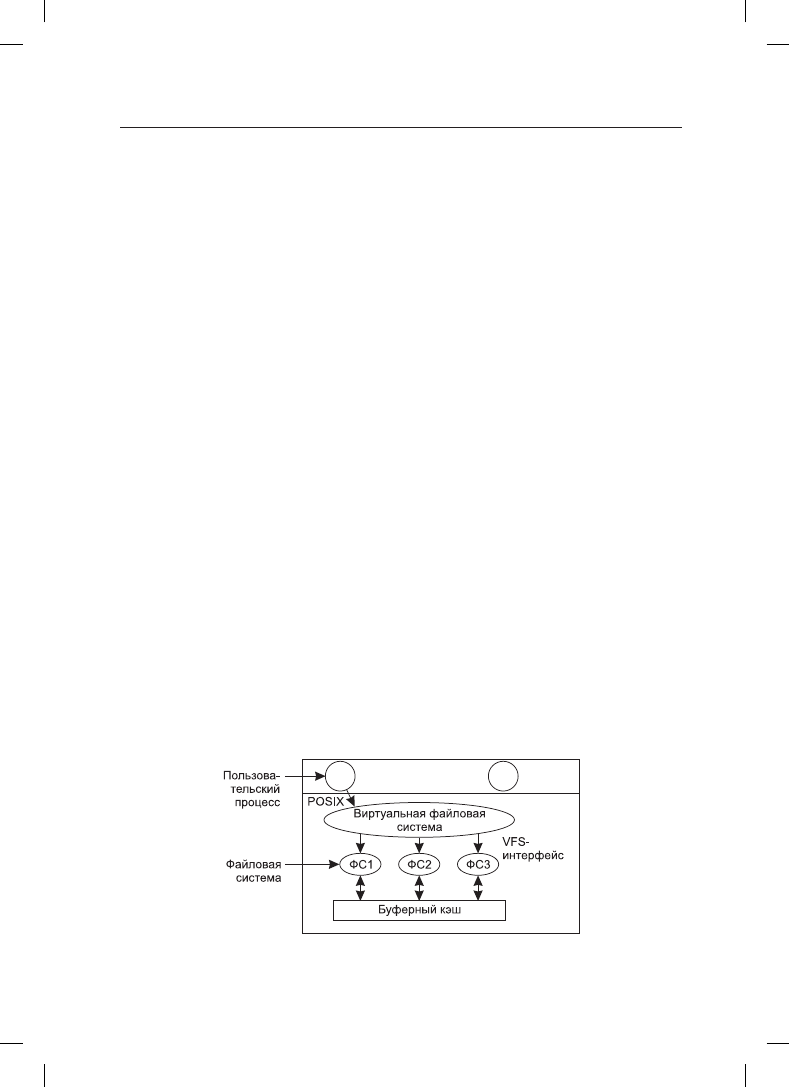
фактического управления данными. Вся структура показана на рис. 4.15. Рассматри-
ваемый далее материал не имеет конкретного отношения к Linux, или FreeBSD, или
любой другой версии UNIX, но дает общее представление о том, как в UNIX-системах
работают виртуальные файловые системы.
Все относящиеся к файлам системные вызовы направляются для первичной обработки
в адрес виртуальной файловой системы. Эти вызовы, поступающие от пользователь-
Рис. 4.15. Расположение виртуальной файловой системы

4.3. Реализация файловой системы
337
ских процессов, являются стандартными POSIX-вызовами, такими как open, read, write,
lseek и т. д. Таким образом, VFS обладает «верхним» интерфейсом к пользовательским
процессам, и это хорошо известный интерфейс POSIX.
У VFS есть также «нижний» интерфейс к конкретной файловой системе, который на
рис. 4.15 обозначен как VFS-интерфейс. Этот интерфейс состоит из нескольких десят-
ков вызовов функций, которые VFS способна направлять к каждой файловой системе
для достижения конечного результата. Таким образом, чтобы создать новую файловую
систему, работающую с VFS, ее разработчики должны предоставить вызовы функций,
необходимых VFS. Вполне очевидным примером такой функции является функция,
считывающая с диска конкретный блок, помещающая его в буферный кэш файловой
системы и возвращающая указатель на него. Таким образом, у VFS имеются два ин-
терфейса: «верхний» — к пользовательским процессам и «нижний» — к конкретным
файловым системам.
Хотя большинство файловых систем, находящихся под VFS, представляют разделы ло-
кального диска, так бывает не всегда. На самом деле исходной мотивацией для компании
Sun при создании VFS служила поддержка удаленных файловых систем, использующих
протокол сетевой файловой системы (Network File System (NFS)). Конструктивная
особенность VFS состоит в том, что пока конкретная файловая система предоставляет
требуемые VFS функции, VFS не знает или не заботится о том, где данные хранятся или
что собой представляет находящаяся под ней файловая система.
По внутреннему устройству большинство реализаций VFS являются объектно-ориен-
тированными, даже если они написаны на C, а не на C++. Как правило, в них поддержи-
вается ряд ключевых типов объектов. Среди них суперблок (superblock), описывающий
файловую систему, v-узел (v-node), описывающий файл, и каталог (directory), описыва-
ющий каталог файловой системы. Каждый из них имеет связанные операции (методы),
которые должны поддерживаться конкретной файловой системой. Вдобавок к этому
в VFS имеется ряд внутренних структур данных для собственного использования, вклю-
чая таблицу монтирования и массив описателей файлов, позволяющий отслеживать все
файлы, открытые в пользовательских процессах.
Чтобы понять, как работает VFS, разберем пример в хронологической последователь-
ности. При загрузке системы VFS регистрирует корневую файловую систему. Вдобавок
к этому при подключении (монтировании) других файловых систем, либо во время
загрузки, либо в процессе работы они также должны быть зарегистрированы в VFS.
При регистрации файловой системы главное, что она делает, — предоставляет список
адресов функций, необходимых VFS, в виде либо длинного вектора вызова (таблицы),
либо нескольких таких векторов, по одному на каждый VFS-объект, как того требует
VFS. Таким образом, как только файловая система зарегистрируется в VFS, вирту-
альная файловая система будет знать, каким образом, скажем, она может считать блок
из зарегистрировавшейся файловой системы, — она просто вызывает четвертую (или
какую-то другую по счету) функцию в векторе, предоставленном файловой системой.
Также после этого VFS знает, как можно выполнить любую другую функцию, которую
должна поддерживать конкретная файловая система: она просто вызывает функцию,
чей адрес был предоставлен при регистрации файловой системы.
После установки файловую систему можно использовать. Например, если файловая
система была подключена к каталогу
/usr
и процесс осуществил вызов
open("/usr/include/unistd.h",ORDONLY)
338
Глава 4. Файловые системы
то при анализе пути VFS увидит, что к
/usr
была подключена новая файловая система,
определит местоположение ее суперблока, просканировав список суперблоков уста-
новленных файловых систем. После этого она может найти корневой каталог установ-
ленной файловой системы, а в нем — путь
include/unistd.h
. Затем VFS создает v-узел
и направляет вызов конкретной файловой системе, чтобы вернулась вся информация,
имеющаяся в i-узле файла. Эта информация копируется в v-узел (в оперативной
памяти) наряду с другой информацией, наиболее важная из которой — указатель на
таблицу функций, вызываемых для операций над v-узлами, таких как чтение — read,
запись — write, закрытие — close и т. д.
После создания v-узла VFS создает запись в таблице описателей файлов вызыва-
ющего процесса и настраивает ее так, чтобы она указывала на новый v-узел. (Для
особо дотошных — описатель файла на самом деле указывает на другую структуру
данных, в которой содержатся текущая позиция в файле и указатель на v-узел, но эти
подробности для наших текущих задач не очень важны.) И наконец, VFS возвращает
описатель файла вызывавшему процессу, чтобы тот мог использовать его при чтении,
записи и закрытии файла.
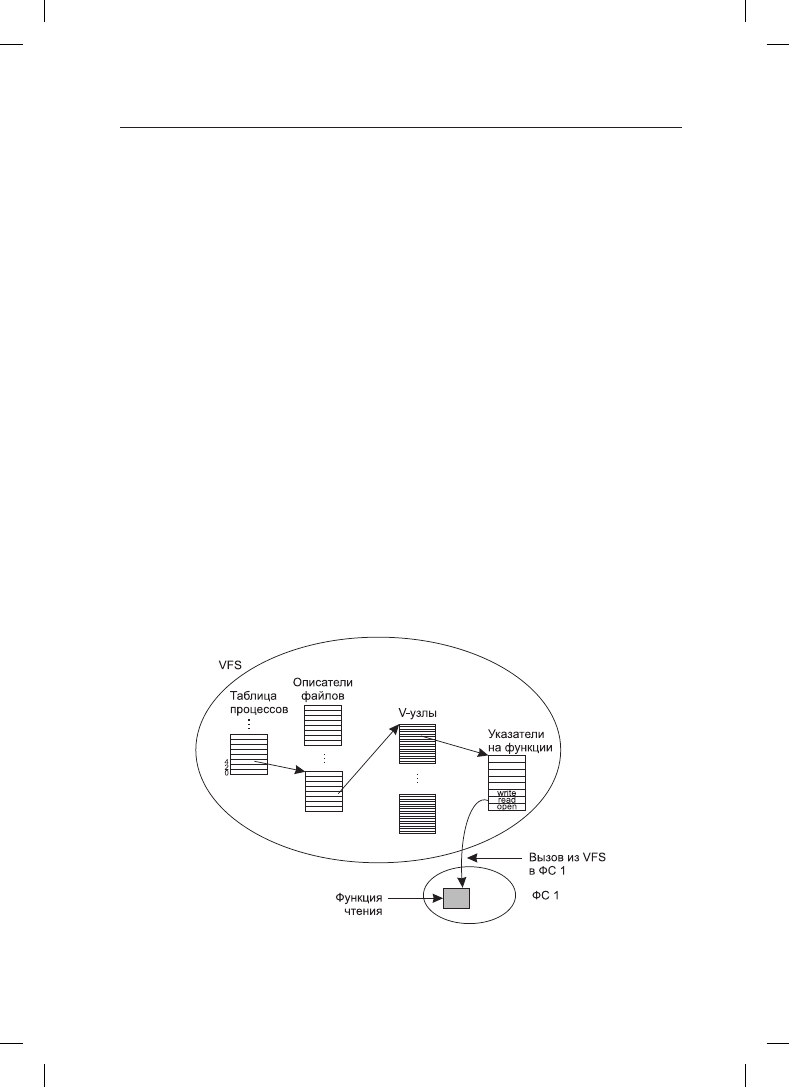
В дальнейшем, когда процесс осуществляет чтение, используя описатель файла, VFS
находит v-узел из таблиц процесса и описателей файлов и следует по указателю
к таблице функций, каждая из которых имеет адрес внутри конкретной файловой
системы, где и расположен нужный файл. Теперь вызывается функция, управляющая
чтением, и внутри конкретной файловой системы запускается код, извлекающий
требуемый блок. VFS не знает, откуда приходят данные, с локального диска или по
сети с удаленной файловой системы, с флеш-накопителя USB или из другого источ-
ника. Задействованные структуры данных показаны на рис. 4.16. Они начинаются
с номера вызывающего процесса и описателя файла, затем задействуется v-узел,
указатель на функцию read и отыскивается доступ к функции внутри конкретной
файловой системы.
Рис. 4.16. Упрощенный взгляд на структуру данных и код, используемые VFS
и конкретной файловой системой для операции чтения

4.4. Управление файловой системой и ее оптимизация
339
Таким образом, добавление файловых систем становится относительно простой зада-
чей. Чтобы добавить какую-нибудь новую систему, разработчики берут перечень вы-
зовов функций, ожидаемых VFS, а затем пишут свою файловую систему таким образом,
чтобы она предоставляла все эти функции. В качестве альтернативы, если файловая
система уже существует, им нужно предоставить функции-оболочки, которые делают
то, что требуется VFS, зачастую за счет осуществления одного или нескольких вызовов,
присущих конкретной файловой системе.
4.4. Управление файловой системой
и ее оптимизация
Заставить файловую систему работать — это одно, а вот добиться от нее эффективной
и надежной работы — совсем другое. В следующих разделах будет рассмотрен ряд во-
просов, относящихся к управлению дисками.
4.4.1. Управление дисковым пространством
Обычно файлы хранятся на диске, поэтому управление дисковым пространством
является основной заботой разработчиков файловой системы. Для хранения файла
размером n байт возможно использование двух стратегий: выделение на диске n по-
следовательных байтов или разбиение файла на несколько непрерывных блоков. Та-
кая же дилемма между чистой сегментацией и страничной организацией присутствует
и в системах управления памятью.
Как уже было показано, при хранении файла в виде непрерывной последовательности
байтов возникает очевидная проблема: вполне вероятно, что по мере увеличения его
размера потребуется его перемещение на новое место на диске. Такая же проблема
существует и для сегментов в памяти, с той лишь разницей, что перемещение сегмента
в памяти является относительно более быстрой операцией по сравнению с перемещени-
ем файла с одной дисковой позиции на другую. По этой причине почти все файловые
системы разбивают файлы на блоки фиксированного размера, которые не нуждаются
в смежном расположении.
Размер блока
Как только принято решение хранить файлы в блоках фиксированного размера, возни-
кает вопрос: каким должен быть размер блока? Кандидатами на единицу размещения,
исходя из способа организации дисков, являются сектор, дорожка и цилиндр (хотя все
эти параметры зависят от конкретного устройства, что является большим минусом).
В системах со страничной организацией памяти проблема размера страницы также
относится к разряду основных.
Если выбрать большой размер блока (один цилиндр), то каждый файл, даже одно-
байтовый, занимает целый цилиндр. Это также означает, что существенный объем
дискового пространства будет потрачен впустую на небольшие файлы. В то же время
при небольшом размере блока (один физический сектор) большинство файлов будет
разбито на множество блоков, для чтения которых потребуется множество операций
позиционирования головки и ожиданий подхода под головку нужного сектора, сни-

340
Глава 4. Файловые системы
жающих производительность системы. Таким образом, если единица размещения
слишком большая, мы тратим впустую пространство, а если она слишком маленькая —
тратим впустую время.
Чтобы сделать правильный выбор, нужно обладать информацией о распределе-
нии размеров файлов. Вопрос распределения размеров файлов был изучен автором
(Tanenbaum et al., 2006) на кафедре информатики крупного исследовательского уни-
верситета (VU) в 1984 году, а затем повторно изучен в 2005 году, исследовался также
коммерческий веб-сервер, предоставляющий хостинг политическому веб-сайту (
www.
electoral-vote.com
). Результаты показаны в табл. 4.3, где для каждого из трех наборов
данных перечислен процент файлов, меньших или равных каждому размеру файла,
кратному степени числа 2. К примеру, в 2005 году 59,13 % файлов в VU имели размер
4 Кбайт или меньше, а 90,84 % — 64 Кбайт или меньше. Средний размер файла со-
ставлял 2475 байт. Кому-то такой небольшой размер может показаться неожиданным.
Какой же вывод можно сделать исходя из этих данных? Прежде всего, при размере
блока 1 Кбайт только около 30–50 % всех файлов помещается в единичный блок, тогда
как при размере блока 4 Кбайт количество файлов, помещающихся в блок, возрастает
до 60–70 %. Судя по остальным данным, при размере блока 4 Кбайт 93 % дисковых
блоков используется 10 % самых больших файлов. Это означает, что потеря некоторого
пространства в конце каждого небольшого файла вряд ли имеет какое-либо значение,
поскольку диск заполняется небольшим количеством больших файлов (видеоматери-
алов), а то, что основной объем дискового пространства занят небольшими файлами,
едва ли вообще имеет какое-то значение. Достойным внимания станет лишь удвоение
пространства 90 % файлов.
Таблица 4.3. Процент файлов меньше заданного размера
Длина
VU 1984
VU 2005
Веб-сайт
Длина
VU 1984
VU 2005
Веб-сайт
1 байт
1,79
1,38
6,67
16 Кбайт
92,53
78,92
86,79
2 байта
1,88
1,53
7,67
32 Кбайт
97,27
85,87
91,65
4 байта
2,01
1,65
8,33
64 Кбайт
99,18
90,84
94,80
8 байтов
2,31
1,80
11,30
128 Кбайт
99,84
93,73
96,93
16 байтов
3,32
2,15
11,46
256 Кбайт
99,96
96,12
98,48
32 байта
5,13
3,15
12,33
512 Кбайт
100,00
97,73
98,99
64 байта
8,71
4,98
26,10
1 Мбайт
100,00
98,87
99,62
128 байтов
14,73
8,03
28,49
2 Мбайт
100,00
99,44
99,80
256 байтов
23,09
13,29
32,10
4 Мбайт
100,00
99,71
99,87
512 байта
34,44
20,62
39,94
8 Мбайт
100,00
99,86
99,94
1 Кбайт
48,05
30,91
47,82
16 Мбайт
100,00
99,94
99,97
2 Кбайта
60,87
46,09
59,44
32 Мбайт
100,00
99,97
99,99
4 Кбайта
75,31
59,13
70,64
64 Мбайт
100,00
99,99
99,99
8 Кбайтов
84,97
69,96
79,69
128 Мбайт
100,00
99,99
100,00
В то же время использование небольших блоков означает, что каждый файл будет со-
стоять из множества блоков. Для чтения каждого блока обычно требуется потратить
время на позиционирование блока головок и ожидание подхода под головку нужного