Добавлен: 29.10.2018
Просмотров: 48150
Скачиваний: 190
426
Глава 5. Ввод и вывод информации
Для большинства дисков время позиционирования блока головок существенно до-
минирует над всеми остальными факторами, поэтому сокращение среднего времени
позиционирования может значительно повысить производительность системы.
Если драйвер диска принимает запросы по одному и выполняет их в порядке посту-
пления по принципу «первым пришел — первым обслужен» (First-Come, First-Served
(FCFS)), то для оптимизации времени позиционирования практически ничего нельзя
сделать. Но при большой загруженности диска может применяться и другая стратегия.
Часто бывает так, что пока блок головок позиционируется для выполнения одного
запроса, другими процессами могут быть сформированы другие запросы к диску.
Многие драйверы дисков ведут таблицу, индексированную по номерам цилиндров,
в которой все ожидающие выполнения запросы для каждого цилиндра объединяются
в связанный список.
Располагая подобной структурой данных, можно улучшить алгоритм «первым при-
шел — первым обслужен». Чтобы понять, как это можно сделать, рассмотрим вообража-
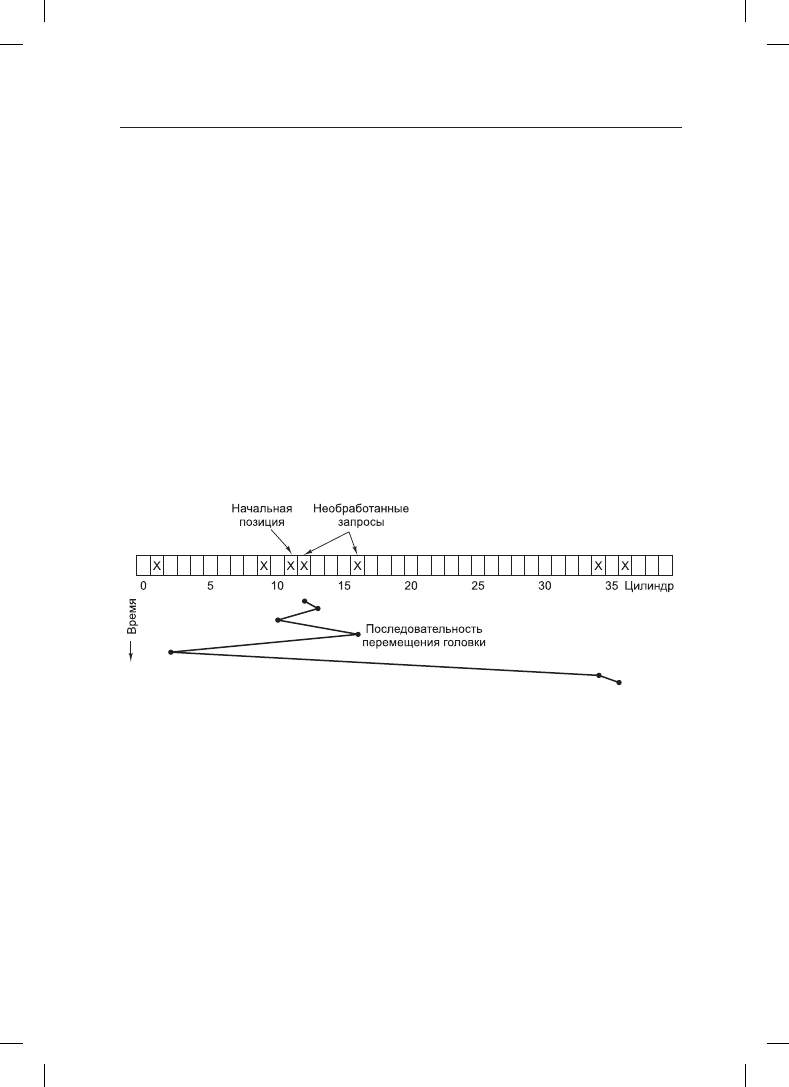
емый диск, имеющий 40 цилиндров. Поступает запрос на чтение блока на цилиндре 11.
Пока блок головок позиционируется на цилиндр 11, последовательно поступают новые
запросы, относящиеся к цилиндрам 1, 36, 16, 34, 9 и 12. Они заносятся в таблицу ожи-
дающих выполнения запросов, имеющую отдельный связанный список для каждого
цилиндра. Эти запросы показаны на рис. 5.20.
Рис. 5.20. Алгоритм планирования «позиционирование на ближайший цилиндр» (SSF)
Когда завершится выполнение текущего запроса (для цилиндра 11), драйвер диска
должен выбрать, какой из запросов обрабатывать следующим. При использовании
алгоритма FCFS он перейдет к цилиндру 1, затем к цилиндру 36 и т. д. Выполнение
этого алгоритма потребует перемещения блока головок на 10, 35, 20, 18, 25 и 3 цилиндра
соответственно, что в сумме составит 111 цилиндров.
При альтернативном варианте он может всегда обрабатывать следующим запрос на
ближайший цилиндр, сводя тем самым время позиционирования к минимуму. Если
рассмотреть запросы, показанные на рис. 5.20, последовательность, изображенная
в нижней части рисунка в виде зигзагообразной линии, будет состоять из цилиндров
12, 9, 16, 1, 34 и 36. При такой последовательности блок головок будет перемещаться
на 1, 3, 7, 15, 33 и 2 цилиндра, что в сумме составит 61 цилиндр. Этот алгоритм под
названием «позиционирование на ближайший цилиндр» (Shortest Seek First (SSF))
сокращает общее количество перемещений блока головок по сравнению с алгоритмом
FCFS примерно в два раза.

5.4. Диски
427
К сожалению, алгоритм SSF не обходится без недостатков. Предположим, что за время
обработки запросов, показанных на рис. 5.20, продолжают поступать все новые и новые
запросы. К примеру, если после перемещения к цилиндру 16 есть запрос к цилиндру 8,
этот запрос будет иметь приоритет над запросом к цилиндру 1. Если затем поступит
запрос к цилиндру 13, то в следующую очередь блок перейдет к нему, а не к цилиндру 1.
При высокой загруженности диска блок головок будет большую часть времени оста-
ваться в его средней части, поэтому запросам к крайним цилиндрам придется ждать,
пока статистические отклонения в загруженности диска не приведут к отсутствию
запросов к средним цилиндрам. Запросы, удаленные от средней части, могут плохо
обслуживаться. Здесь цели достижения равнодоступности и минимизации времени
отклика вступают в конфликт.
С такими же компромиссами сталкиваются и при обслуживании высотных зданий. Про-
блемы планирования перемещений блока головок перекликаются с проблемами плани-
рования работы лифта в высотном здании. Постоянно поступающие запросы вызывают
лифт на разные этажи (цилиндры) в произвольной последовательности. Компьютер,
управляющий лифтом, в состоянии отслеживать последовательность, в которой клиенты
нажимают кнопку вызова, и обслуживает их, используя алгоритмы FCFS или SSF.
Но в большинстве лифтов используется другой алгоритм, призванный согласовать
конфликтующие друг с другом цели достижения эффективности и равнодоступности.
Они продолжают двигаться в одном направлении до тех пор, пока в этом направлении
не останется невыполненных запросов, а затем меняют направление. Этот алгоритм,
известный как в мире дисковых устройств, так и в мире лифтов как алгоритм лифта
(элеваторный алгоритм, elevator algorithm), требует от программы отслеживать состо-
яние всего одного бита — текущего направления: Вверх или Вниз. После обслуживания
запроса драйвер диска или лифта проверяет состояние бита. Если он имеет значение
Вверх, то блок головок или кабина перемещаются к следующему необслуженному
запросу, касающемуся более высокой позиции. Если необслуженных запросов, касаю-
щихся более высокой позиции, не имеется, бит направления меняет свое значение на
противоположное. Когда этот бит имеет значение Вниз, то перемещение осуществля-
ется к следующей более низкой позиции, если таковая запрошена. Если ожидающих
обслуживание запросов нет, блок останавливается и переходит в режим ожидания.
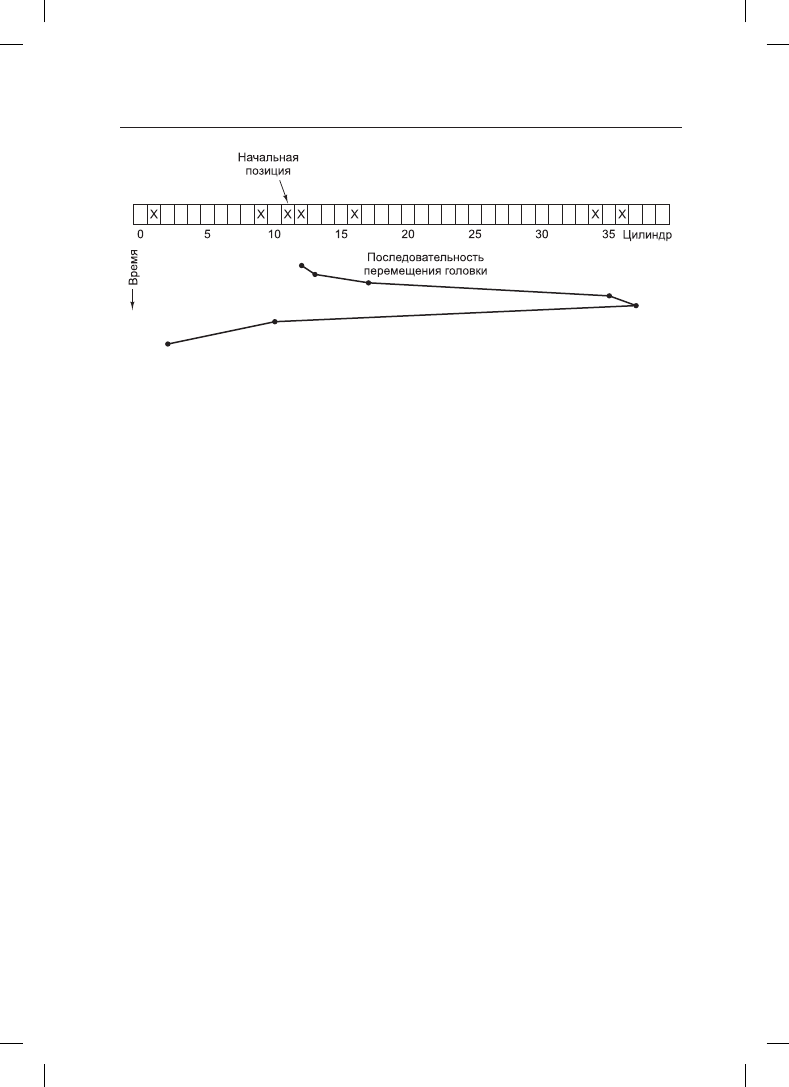
На рис. 5.21 показан алгоритм лифта, используемый при обслуживании тех же семи
запросов, которые были показаны на рис. 5.20, при условии что бит направления из-
начально был установлен в положение Вверх. Цилиндры обслуживаются в следующем
порядке: 12, 16, 34, 36, 9 и 1, согласно которому блок головок перемещается на 1, 4, 18,
2, 27 и 8 цилиндров, что в сумме составляет 60 цилиндров. В данном случае алгоритм
лифта оказался немного лучше, чем SSF, но обычно он работает намного хуже. Одним
из достоинств алгоритма лифта является то, что при любом наборе запросов верхняя
граница общего количества перемещений является числом постоянным — равным
удвоенному количеству цилиндров.
Небольшая модификация этого алгоритма, имеющая незначительное отклонение
в быстроте отклика (Teory, 1972), предусматривает постоянное сканирование в одном
направлении. После обслуживания запроса, касающегося цилиндра с самым большим
номером, блок головок перемещается к цилиндру с самым маленьким номером, на
который поступил запрос, а затем продолжает перемещение вверх. По сути, считается,
что цилиндр с самым маленьким номером расположен как бы выше цилиндра с самым
большим номером.
428
Глава 5. Ввод и вывод информации
Рис. 5.21. Алгоритм лифта для планирования обслуживания дисковых запросов
Некоторые контроллеры дисков предоставляют программам способ определения
номера сектора, находящегося под головкой. При использовании такого контроллера
можно применить другой способ оптимизации. Когда поступают два и более запроса,
касающихся одного и того же цилиндра, драйвер может выдать запрос на тот сектор,
который будет проходить под головкой следующим. Следует заметить, что при наличии
в цилиндре нескольких дорожек последовательные запросы могут беспрепятственно
выдаваться в отношении разных дорожек. Контроллер может практически мгновенно
выбирать любую из управляемых им головок (для выбора головки не требуется ни
перемещения блока головок, ни ожидания подхода нужного сектора под головку).
Если у диска время позиционирования головок намного меньше, чем время ожида-
ния подхода нужного сектора под головку, то может быть использован другой способ
оптимизации. Невыполненные запросы должны быть отсортированы по номерам
секторов, и как только следующий сектор будет близок к прохождению под головкой,
блок головок должен «сбегать» к нужной дорожке, чтобы провести чтение или запись.
В современных жестких дисках задержки позиционирования и подхода сектора на-
столько влияют на производительность, что чтение по одному или по два сектора счи-
тается крайне неэффективной операцией. Поэтому многие контроллеры дисков всегда
читают и помещают в кэш сразу несколько секторов, даже если запрос пришел только
на один из них. Обычно при любом запросе на чтение одного сектора считывается не
только этот, но и все или большая часть остальных секторов на данной дорожке в за-
висимости от объема доступного пространства в кэш-памяти контроллера. К примеру,
у жесткого диска, рассмотренного в табл. 5.3, объем кэш-памяти составлял 4 Мбайт. Во-
просы использования кэша решаются контроллером в динамическом режиме. В самом
простом варианте кэш делится на два раздела, один для чтения, а другой для записи.
Если очередной запрос на чтение может быть удовлетворен данными из кэша кон-
троллера, то запрошенные данные могут быть возвращены контроллером немедленно.
Следует заметить, что кэш контроллера диска абсолютно не зависит от кэша операци-
онных систем. Кэш контроллера содержит, как правило, те блоки, на которые запрос
не поступал, но которые было удобно считать с диска, поскольку они проходили под
головками при обслуживании запроса на чтение какого-нибудь другого блока. В отличие
от этого любой кэш, обслуживаемый операционной системой, будет состоять из блоков,
которые были считаны по запросу и, по разумению операционной системы, в ближайшем
будущем могут понадобиться еще раз (например, дисковый блок, содержащий каталог).

5.4. Диски
429
Если к одному контроллеру подключено несколько дисковых накопителей, операци-
онная система должна обслуживать таблицу необработанных запросов отдельно для
каждого накопителя. На любом незадействованном диске должно быть запрошено по-
зиционирование блока головок на тот цилиндр, который потребуется следующим (если
предположить, что контроллер поддерживает совмещенное позиционирование). Когда
завершится текущая операция передачи данных, должно быть проверено наличие на-
копителей, позиционированных на нужный цилиндр. Если имеется один или несколько
таких накопителей, то на накопителе, уже позиционированном на нужный цилиндр,
можно приступить к следующей операции передачи данных. Если ни один из блоков
головок не находится в нужном месте, драйвер должен выдать команду позициониро-
вания на требуемый цилиндр на том накопителе, который только что завершил пере-
дачу данных, и перейти в режим ожидания, пока не поступит следующее прерывание,
чтобы определить, какой из блоков головок первым позиционируется на нужное место.
Важно понять, что во всех описанных алгоритмах планирования позиционирования
подразумевалось, что реальная геометрия диска совпадала с его виртуальной геометри-
ей. Если они не совпадают, то планирование обслуживания дисковых запросов не имеет
смысла, поскольку операционная система не в состоянии указать, какой из цилиндров,
40-й или 200-й, находится ближе к 39-му цилиндру. В то же время, если контроллер
диска в состоянии воспринимать несколько ожидающих обслуживания запросов, то он
может использовать эти алгоритмы планирования в собственной работе. В таком случае
алгоритмы будут работать правильно, но на один уровень ниже, внутри контроллера.
5.4.4. Обработка ошибок
Производители дисков часто преодолевают технологические ограничения за счет увели-
чения линейной плотности битов. Дорожка посредине 5,25-дюймового диска имеет длину
окружности около 300 мм. Если в дорожке 300 секторов по 512 байт, то линейная плот-
ность записи может составлять около 5000 бит/мм, если принять во внимание тот факт,
что часть пространства теряется на заголовки, коды ECC и промежутки между сектора-
ми. Запись плотностью 5000 бит/мм требует исключительной однородности материала
подложки и высококачественного оксидного покрытия. К сожалению, производство дис-
ка с такими параметрами не может обойтись без дефектов. По мере совершенствования
технологии производства и доведения ее до бездефектного выхода готовой продукции
при такой плотности записи разработчики дисков с целью увеличения емкости носителя
переходят к более высокой плотности. В результате чего снова появляются дефекты.
Производственные дефекты проявляются в сбойных секторах, из которых неверно
считывается только что записанная информация. Если дефект весьма незначителен
и составляет, скажем, всего несколько бит, то сбойный сектор может использоваться
при условии постоянной корректировки ошибок с помощью ECC-кода. При более
существенных размерах скрыть дефект уже невозможно.
Существуют два основных подхода к решению проблемы сбойных блоков: обработка
таких блоков в контроллере или их обработка средствами операционной системы.
При первом подходе еще до выпуска диска с предприятия он проходит тестирование,
и на него записывается список сбойных секторов. Каждый сбойный сектор заменяется
одним из запасных секторов.
Существует два способа подобной замены. На рис. 5.22, а показана отдельная дорожка
диска, имеющая 30 рабочих и два запасных сектора. Определено, что сектор 7 является
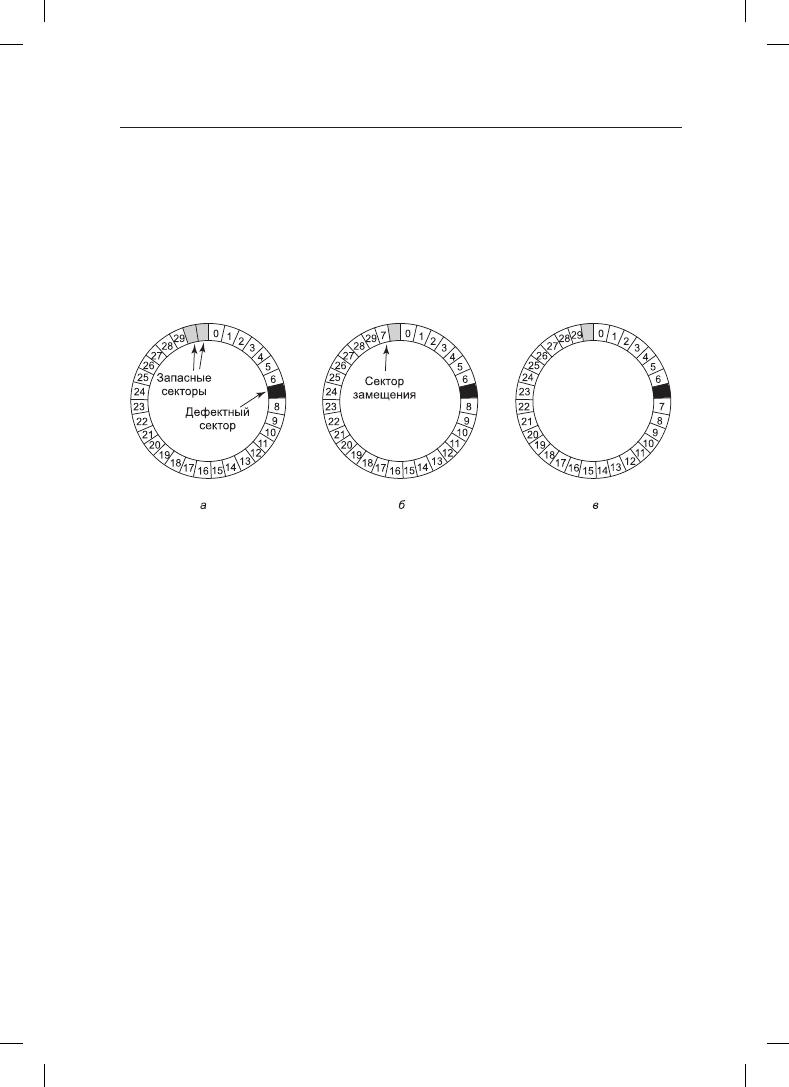
430
Глава 5. Ввод и вывод информации
сбойным. Контроллер может переопределить один из запасных секторов и сделать его
сектором 7 (рис. 5.22, б). Другой способ заключается в сдвиге всех секторов на одну
позицию (рис. 5.22, в). В обоих случаях контроллер должен знать, где какой сектор
находится. Он должен учитывать эту информацию во внутренних таблицах (по одной
на каждую дорожку) или переписывать заголовки, присваивая переопределенным
секторам другие номера. Способ перезаписи номеров в заголовках, показанный на
рис. 5.22, в, будет более затратным (поскольку должны быть переписаны 23 заголовка),
но в конечном счете он обеспечит более высокую производительность, так как за один
оборот диска можно будет прочитать всю дорожку.
Рис. 5.22. Диск: а — дорожка со сбойным сектором; б — замена сбойного сектора запасным;
в — сдвиг всех секторов с пропуском сбойного сектора
Ошибки могут проявляться и в процессе использования уже после установки накопите-
ля. Первой оборонительной линией против ошибок, нескорректированных с помощью
кода ECC, выступает попытка повторного чтения. Некоторые ошибки считывания
носят случайный характер, то есть вызваны пылинками, попавшими под головку,
и исчезают при повторной попытке. Если контроллер замечает повторное проявление
ошибки при чтении конкретного сектора, он может переключиться на использование
запасного сектора еще до того, как считываемый сектор окончательно выйдет из строя.
При этом данные не будут потеряны, а операционная система и пользователь не заметят
никакой проблемы. Обычно способ, показанный на рис. 5.22, б, должен использоваться
в том случае, когда все остальные секторы могут уже содержать данные. Применение
способа, показанного на рис. 5.22, в, потребует не только перезаписи всех заголовков,
но и копирования всех данных.
Ранее уже отмечалось, что есть два основных подхода к обработке ошибок: вести их
обработку в контроллере или в операционной системе. Если контроллер не способен
четко перенумеровать секторы ранее рассмотренными способами, то операционная
система должна сделать это на программном уровне. Это означает, что сначала она
должна получить список сбойных секторов либо путем чтения его с диска, либо за счет
самостоятельного тестирования всего диска. После того как она узнает все о сбойных
секторах, она сможет создать таблицы перенумерации. Если операционная система
захочет воспользоваться способом, показанным на рис. 5.22, в, она должна сдвинуть
все данные в секторах с 7-го по 29-й на один сектор.
Если перенумерацией секторов занимается операционная система, то она должна огра-
дить файлы и списки свободных блоков или двоичные матрицы от появления в них