Добавлен: 29.10.2018
Просмотров: 48154
Скачиваний: 190

5.4. Диски
431
сбойных секторов. Это можно сделать путем создания секретного файла, состоящего
из всех сбойных секторов. Если этот файл не будет входить в состав файловой систе-
мы, то пользователи не смогут случайно его прочитать (или, что еще хуже, удалить).
Но остается еще одна проблема: создание резервных копий. Если резервное копиро-
вание диска осуществляется в пофайловом режиме, то очень важно, чтобы служебная
программа резервного копирования не пыталась скопировать файл, составленный из
сбойных блоков. Чтобы предотвратить такую возможность, операционная система
должна настолько скрыть файл сбойных блоков, чтобы его не смогла найти даже
служебная программа резервного копирования. Если резервное копирование диска
проходит в посекторном, а не пофайловом режиме, то будет очень трудно, если вообще
возможно, предотвратить чтение сбойных секторов в процессе создания резервной
копии. Остается лишь надеяться, что программа резервного копирования догадается
отказаться от копирования сектора после десяти неудачных попыток и продолжит
копирование других секторов.
Но источниками ошибок могут быть не только сбойные секторы. Случаются также
ошибки позиционирования блока головок, вызванные проблемами механического ха-
рактера. Контроллер отслеживает позицию блока головок самостоятельно. Для измене-
ния позиции он выдает команду двигателю блока головок на перемещение этого блока
к новому цилиндру. Когда блок головок переместится в нужную позицию, контроллер
фактически считывает номер текущего цилиндра из заголовка первого подошедшего
под головку сектора. Если блок головок находится в неверной позиции, то возникает
ошибка позиционирования.
Большинство контроллеров жестких дисков исправляют ошибки позиционирования
автоматически, но большинство устаревших контроллеров гибких дисков, которые ис-
пользовались в 1980–1990-х годах, просто устанавливали бит ошибки, а все остальное
возлагали на драйвер устройства, который справлялся с этой ошибкой путем выдачи
команды на перекалибровку — recalibrate, перемещающую блок головок как можно
дальше к внешней границе диска и устанавливающую текущую дорожку в контроллере
в качестве нулевой. Обычно это приводило к решению проблемы, а если нет, то привод
подлежал ремонту
1
.
Очевидно, что контроллер представляет собой небольшой специализированный ком-
пьютер, у которого есть программное обеспечение, переменные, буферы и, время от
времени, ошибки. Иногда редко встречающаяся последовательность событий, к при-
меру прерывание на одном приводе в сочетании с командой recalibrate на другом, вы-
зывает сбой и заставляет контроллер войти в цикл или утратить контроль за своими
действиями. Разработчики контроллеров обычно рассчитывают на худшее и оставляют
на чипе один контакт, подача сигнала на который заставляет контроллер забыть обо
всем, что он делал, и перезапуститься. Если все средства исчерпаны, драйвер может
установить бит, выдающий этот сигнал и перезапускающий контроллер. Если и это
не поможет, то драйвер может лишь выдать сообщение и отказаться от дальнейших
попыток исправить ситуацию.
При перекалибровке диска возникает непривычный шум, не вызывающий особого
беспокойства. Но есть такая ситуация, при которой перекалибровка вызывает про-
блему: речь идет о системах, работающих в режиме реального времени. Когда видео
1
Или необходимо было заменить дискету, если она не читалась в нескольких дисководах,
которые вполне могли быть полностью исправными. — Примеч. ред.

432
Глава 5. Ввод и вывод информации
воспроизводится (или обслуживается) с жесткого диска или файлы с жесткого диска
записываются на Blu-ray-диск, очень важно, чтобы биты поступали с жесткого диска
с постоянной скоростью. В таких обстоятельствах перекалибровка приведет к разрыву
потока данных, поэтому ее выполнение неприемлемо. Для этих целей можно восполь-
зоваться специальными приводами, которые называются аудиовидеодисками, или
AV-дисками
(Audio Visual disks), на которых никогда не производится перекалибровка.
Интересно, что весьма убедительно продемонстрировал совершенство контроллера
дисков голландский хакер Йерун Домбург (Jeroen Domburg), взломавший современ-
ный контроллер диска с целью запуска на нем специального кода. Оказалось, что кон-
троллер диска оборудован достаточно мощным многоядерным (!) ARM-процессором
и его ресурсов вполне хватает для запуска Linux. Если злоумышленники так же взло-
мают ваш жесткий диск, они смогут увидеть и изменить все данные, переносимые на
диск или с диска. От инфекции невозможно избавиться даже путем переустановки
операционной системы, поскольку инструментом злоумышленника будет сам кон-
троллер диска, который будет служить ему лазейкой. Можно также собрать стойку из
сломанных жестких дисков, взятых в местном центре утилизации, и бесплатно создать
собственный вычислительный кластер.
5.4.5. Стабильное хранилище данных
Как видим, дисковые устройства иногда допускают ошибки. Рабочие секторы могут
внезапно превратиться в сбойные. Могут неожиданно выйти из строя и целые диски.
Защитой от внезапного сбоя на нескольких секторах или от выхода из строя всего дис-
ка выступают RAID-массивы. Но и они не защищают от ошибок записи, основанных
прежде всего на неверных данных. Они также не защищают от сбоев при записи, по-
вреждающих исходные данные без замены их новыми данными.
Для некоторых приложений очень важно, чтобы данные никогда не терялись или не
повреждались, даже при ошибках диска или центрального процессора. В идеале диск
должен просто работать без ошибок весь срок своей эксплуатации. К сожалению, это
невозможно. Но вполне возможно создание дисковой подсистемы, обладающей следу-
ющим свойством: при записи на эту подсистему либо производится верная запись на
диск, либо не производится вообще никакой записи и данные остаются неприкосно-
венными. Такая система называется стабильным хранилищем данных (stable storage)
и реализуется программным способом (Lampson and Sturgis, 1979). Задача заключается
в том, чтобы любой ценой сохранить целостность диска. Далее будет рассмотрен упро-
щенный вариант исходного замысла.
Перед описанием алгоритма важно располагать четкой моделью возможных ошибок.
Эта модель предполагает, что при записи блока на диск (в один или несколько секто-
ров) запись может быть либо верной, либо неверной и возникшая ошибка может быть
выявлена при последующем чтении путем проверки значения полей ECC. В принципе,
гарантированно выявить ошибку не представляется возможным, поскольку при ис-
пользовании, скажем, 16-байтного поля ECC, защищающего 512-байтный сектор, мы
имеем дело с 2
4096
возможными значениями данных и только с 2
144
значениями поля
ECC
1
. Таким образом, если данные блока искажаются в процессе записи, а данные ECC
1
Следует заметить, что либо у автора здесь (и далее) опечатка — поле из 16 байт может хра-
нить только 2
128
различных значений, либо предполагается, что в поле ECC используется
«байт», содержащий 9 бит, а не 8, как в области данных. — Примеч. ред.

5.4. Диски
433
не искажаются, существуют миллиарды и миллиарды неверных комбинаций, которые
дают один и тот же код ECC. Если возникнет одна из них, ошибка не будет обнаружена.
В общем, вероятность того, что случайные данные будут иметь верный 16-байтный код
ECC, равна примерно 2
–144
, то есть достаточно мала для того, чтобы назвать ее нулевой,
хотя на самом деле это и не так.
В модели также предполагается, что верно записанный сектор может спонтанно стать
сбойным и перестать читаться. Но предположение состоит еще и в том, что подобные
события случаются настолько редко, что выход из строя точно такого же сектора на
втором (независимом) накопителе в течение соответствующего периода времени (на-
пример, одного дня) настолько маловероятен, что его можно не брать в расчет.
Модель допускает и сбои в работе центрального процессора, при которых он просто
останавливает свою работу. Останавливаются также все проводимые в момент сбоя опе-
рации записи на диск, что приводит к определяемым впоследствии неверным данным
в одном из секторов и неверному значению поля ECC. При всех этих условиях можно
создать стопроцентно надежное стабильное хранилище данных в том смысле, что либо
запись будет вестись корректно, либо старые данные будут оставаться на своем месте.
Разумеется, речь не идет о защищенности от природных катаклизмов вроде внезапного
землетрясения, после которого компьютер свалится в стометровую трещину и упадет
в кипящую магму. Восстановить данные программным способом после такого проис-
шествия будет затруднительно.
Стабильное хранилище использует два работающих вместе одинаковых диска с со-
впадающими блоками, формирующими один не подверженный ошибкам блок. В от-
сутствие ошибок совпадающие блоки на обоих накопителях будут одинаковыми. Чтобы
получить один и тот же результат, можно прочитать любой из них. Чтобы достичь
поставленной цели, определяются три операции:
1. Стабильная операция записи. Стабильная запись состоит из первоначальной запи-
си блока на диск 1, затем его чтения, чтобы проверить, что он записан правильно.
Если он записался неправильно, то проводится повторная запись и чтение до n раз,
пока все не получится. После n последовательных отказов блоку переназначается
запасной сектор и операция повторяется до достижения успеха независимо от
того, сколько запасных секторов придется перепробовать. Когда запись на диск 1
увенчается успехом, соответствующий блок будет записан и считан на диск 2, если
нужно будет, то и несколько раз, пока все также не завершится успешно. Если не
произойдет сбоев в работе центрального процессора, то по завершении стабильной
записи блок будет правильно записан на оба накопителя и проверен на обоих.
2. Стабильная операция чтения. При этой операции первоначально производится
чтение блока с диска 1. Если операция выдаст неверный код ECC, чтение будет
повторяться до n раз. Если все попытки выдадут неверные коды ECC, соответству-
ющий блок будет считан с диска 2. Учитывая то, что после успешной стабильной
записи остаются две хорошие копии блока, и предполагая, что вероятность одно-
временного спонтанного выхода из строя одного и того же блока на обоих нако-
пителях в определенный период времени пренебрежимо мала, стабильное чтение
всегда проходит успешно.
3. Операция восстановления после аварии. После аварии программа восстановления
сканирует оба диска, сравнивая соответствующие блоки. Если пара блоков исправ-
на и содержит одинаковые данные, то с ними ничего не делается. Если у одного из
434
Глава 5. Ввод и вывод информации
них имеется ошибка кода ECC, то плохой блок переписывается с использованием
соответствующего исправного блока. Если в паре исправны оба блока, но их дан-
ные различаются, то блок с диска 1 записывается на диск 2.
В отсутствие отказов центрального процессора такая схема демонстрирует неизменную
работоспособность, поскольку в результате операции стабильной записи всегда полу-
чаются две исправные копии каждого блока и предполагается, что спонтанные ошибки
никогда не возникают сразу на двух блоках. А что будет при отказе центрального про-
цессора в ходе стабильной записи? Все зависит от того, когда именно произошел отказ.
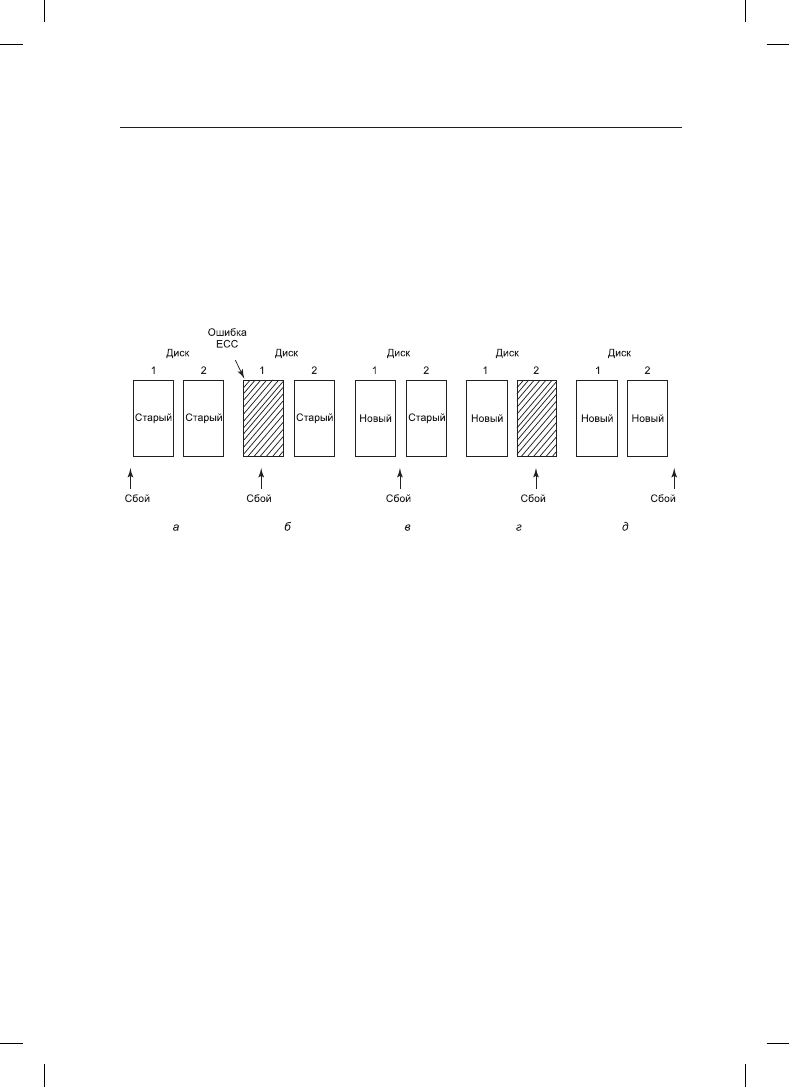
На рис. 5.23 показаны пять возможных вариантов.
Рис. 5.23. Анализ влияния сбоев на стабильную запись
На рис. 5.23, а сбой центрального процессора происходит перед записью обеих копий
блока. При восстановлении ни одна из копий не будет изменена, и будут продолжать
существовать старые данные, что вполне допустимо.
На рис. 5.23, б сбой центрального процессора происходит во время записи на диск 1,
приводя к разрушению содержимого блока. Но программа восстановления обнару-
живает эту ошибку и восстанавливает блок на диске 1 с диска 2. Последствия сбоя
ликвидируются, и полностью восстанавливается старое состояние.
На рис. 5.23, в сбой центрального процессора происходит после записи на диск 1, но
перед записью на диск 2. Здесь система проходит точку невозврата: программа восста-
новления копирует блок с диска 1 на диск 2. Запись завершается успешно.
Ситуация на рис. 5.23, г похожа на ситуацию на рис. 5.23, б: в процессе восстановления
неповрежденный блок записывается на место поврежденного. И в конечном счете
в обоих блоках содержатся новые данные.
И наконец, на рис. 5.23, д программа восстановления видит, что оба блока имеют оди-
наковые значения, поэтому ей не нужно вносить изменения, и здесь, как и в других
случаях, запись завершается успешно.
Эту схему можно оптимизировать и улучшать различными способами. Начнем с того,
что попарное сравнение всех блоков после сбоя вполне осуществимая, но весьма за-
тратная операция. Гораздо лучше будет отслеживать, какой именно блок подвергался
операции стабильной записи, тогда при восстановлении нужно будет проверить только
один этот блок. У некоторых компьютеров есть небольшой объем энергонезависимой

5.5. Часы
435
памяти в виде специальной КМОП-микросхемы, запитанной от литиевой батарейки.
Такие батарейки работают в течение нескольких лет, возможно, в течение всего срока
эксплуатации компьютера. В отличие от оперативной памяти, данные которой теря-
ются после сбоя, энергонезависимая память своих данных не теряет
1
. В ней обычно
хранятся время и дата (изменяемые специальной микросхемой), благодаря чему ком-
пьютеры всегда знают, который час, даже после отключения питания.
Предположим, что для нужд операционной системы доступны несколько байтов
энергонезависимой памяти. Тогда операция стабильного чтения может еще до начала
записи поместить в энергонезависимую память номер блока, который предназначен для
обновления. После успешного завершения стабильной записи номер блока в энергоне-
зависимой памяти переписывается недопустимым номером блока со значением, к при-
меру, 1. При этих условиях после сбоя программа восстановления может проверить
энергонезависимую память и узнать, проводилась ли операция стабильной записи во
время сбоя, и если проводилась, какой блок записывался, когда произошел сбой. По-
сле этого две копии блоков могут быть проверены на правильность и согласованность.
Если энергонезависимая память недоступна, она может быть сымитирована следую-
щим образом: в начале стабильной записи значение какого-нибудь фиксированного
блока на диске 1 перезаписывается номером блока, подлежащего обновлению с помо-
щью операции стабильной записи. Затем данные фиксированного блока считываются
для проверки правильности. После получения правильного значения этого блока за-
писывается и проверяется соответствующий блок на диске 2. Когда стабильная запись
благополучно завершается, в оба фиксированных блока записывается недопустимый
номер блока и правильность записи опять проверяется. В этом случае после сбоя не-
трудно определить, проводилась во время сбоя стабильная запись или нет. Разумеется,
эта технология требует для записи стабильного блока проведения восьми дополни-
тельных дисковых операций, поэтому она должна использоваться с большой оглядкой.
Следует сделать еще одно, последнее замечание. Мы исходили из предположения, что
за день в паре блоков может произойти только одно спонтанное превращение рабочего
блока в сбойный. Но при довольно большом количестве дней может стать сбойным
еще один блок. Следовательно, с целью устранения любых повреждений полное ска-
нирование обоих дисков должно проводиться не реже одного раза в день. Таким об-
разом, каждое утро оба диска неизменно имеют идентичное состояние. Даже если оба
составляющих пару блока в течение нескольких дней станут сбойными, все ошибки
будут благополучно устранены.
5.5. Часы
Часы
(называемые также таймерами) играют важную и разноплановую роль в работе
любой многозадачной системы. Не считая множества других задач, они отслеживают
время суток и предотвращают монополизацию центрального процессора одним из
процессов. Программное обеспечение часов может быть представлено в виде драйвера
устройства, хотя часы не относятся ни к блочным, таким как диск, ни к символьным,
таким как мышь, устройствам. Изучение часов будет проходить по схеме, использо-
1
К сожалению, она тоже подвержена сбоям, пусть и существенно более редким, — и батарейки
бывают некачественные, и контакты для них на системной плате. — Примеч. ред.