Файл: Технологии Больших данных (BigData) (Самое простое определение).pdf
Добавлен: 05.07.2023
Просмотров: 131
Скачиваний: 6
- 1010data;
- Apache Chukwa;
- Apache Hadoop;
- Apache Hive;
- Apache Pig!;
- Jaspersoft;
- LexisNexis Risk Solutions HPCC Systems;
- MapReduce;
- Revolution Analytics (на базе языка R для мат.статистики).
Особый интерес в этом списке представляет Apache Hadoop – ПО с открытым кодом, которое за последние пять лет испытано в качестве анализатора данных большинством трекеров акций. Как только Yahoo открыла код Hadoop сообществу с открытым кодом, в ИТ-индустрии незамедлительно появилось целое направление по созданию продуктов на базе Hadoop. В настоящее время практически все современные средства анализа больших данных предоставляют средства интеграции с Hadoop. Их разработчиками выступают как стартапы, так и общеизвестные мировые компании.
Визуализация
Наглядное представление результатов анализа больших данных имеет принципиальное значение для их интерпретации. Не секрет, что восприятие человека ограничено, и ученые продолжают вести исследования в области совершенствования современных методов представления данных в виде изображений, диаграмм или анимаций. Казалось бы, ничего нового здесь придумать уже невозможно, но на самом деле это не так. В качестве иллюстрации приводим несколько прогрессивных методов визуализации, относительно недавно получивших распространение.
- Облако тегов
Каждому элементу в облаке тега присваивается определенный весовой коэффициент, который коррелирует с размером шрифта. В случае анализа текста величина весового коэффициента напрямую зависит от частоты употребления (цитирования) определенного слова или словосочетания. Позволяет читателю в сжатые сроки получить представление о ключевых моментах сколько угодно большого текста или набора текстов.

- Кластерграмма
Метод визуализации, использующийся при кластерном анализе. Показывает как отдельные элементы множества данных соотносятся с кластерами по мере изменения их количества. Выбор оптимального количества кластеров – важная составляющая кластерного анализа.
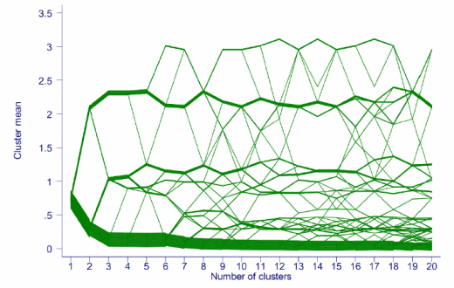
-
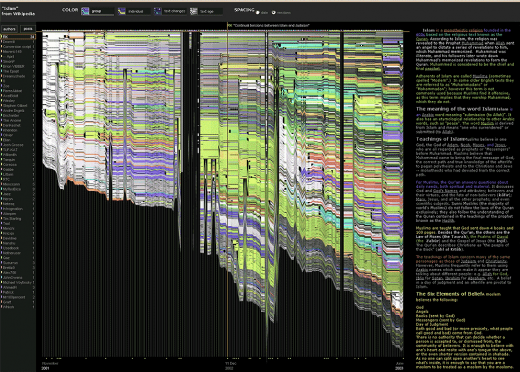
Исторический поток
Помогает следить за эволюцией документа, над созданием которого работает одновременно большое количество авторов. В частности, это типичная ситуация для сервисов wiki и сайта tadviser в том числе. По горизонтальной оси откладывается время, по вертикальной – вклад каждого из соавторов, т.е. объем введенного текста. Каждому уникальному автору присваивается определенный цвет на диаграмме. Приведенная диаграмма – результат анализа для слова «ислам» в Википедии. Хорошо видно, как возрастала активность авторов с течением времени.
- Пространственный поток
Эта диаграмма позволяет отслеживать пространственное распределение информации. Приведенная в качестве примера диаграмма построена с помощью сервиса New York Talk Exchange. Она визуализирует интенсивность обмена IP-трафиком между Нью-Йорком и другими городами мира. Чем ярче линия – тем больше данных передается за единицу времени. Таким легко, не составляет труда выделить регионы, наиболее близкие к Нью-Йорку в контексте информационного обмена.

Проблема больших данных в различных отраслях
big data информация данные
Технологии Big Data успешно реализуются в различных индустриях, на инфографике отражены главенствующие потребители: банки, телеком, ритейл, энергетика, медицина и управление городской инфраструктурой. Интересно, что при всем разнообразии задач вендорские решения в сфере Big Data пока не приобрели ярко выраженной отраслевой направленности. Рынок находится не просто на стадии активного формирования, а в самом начале этой стадии.
Несмотря на малый срок существования сектора Big Data, уже есть оценки эффективного использования этих технологий, основанные на реальных примерах. Один из самых высоких показателей относится к энергетике – по оценкам аналитиков, аналитические технологии Big Data способны на 99% повысить точность распределения мощностей генераторов. А здравоохранение США, благодаря Big Data, может сэкономить до $300 млрд.

Рассмотрим использование Big Data в электронной коммерции.
В любой отрасли — туризм, финансы, спорт или розничная торговля — сегодня трудно представить бизнес без присутствия в Интернете в том или ином виде. Всемирная паутина дала возможность достучаться до каждого, а значит, расширить свою клиентскую базу стало просто как никогда. Но как собирать и где хранить информацию о клиентах? Как быстро и эффективно использовать большие объемы данных для принятия решений?
Что может дать Big Data
Информация о клиенте — вот за что не жалко отдать обе половины царства. И Big Data дает ответы на многие животрепещущие вопросы о заказчике: что он купил и что хотел бы купить, что ему понравилось, а что нет, когда он совершал покупки, как расплатился. И даже больше: персональные данные (адрес, пол, возраст), интересы (какие сайты посетил, кто в друзьях), активность (когда выходит в Интернет, что там ищет, какие отзывы оставляет) и многое другое.
Анализ такой информации — это шанс понять, нравится ли бренд покупателям. Готовы они покупать еще и еще или их следует немного «подтолкнуть» скидками и другими бонусами? Ответы на эти вопросы помогут создать идеального клиента. Того, который всегда готов купить товар по любой цене, активен в сообществах в социальных сетях, заинтересован в развитии бренда и рассказывает всем о понравившейся продукции.
К 2014 году каналов воздействия на клиента стало так много, что приходится использовать инструменты для их объединения. В туризме, например, давно существуют платформы, которые охватывают все аспекты организации путешествий: от планирования до заказа поездок. Туристы могут выбрать места в самолете, отель, достопримечательности, которые стоит посетить, и многое другое — все это в одном месте. Удобно, правда? Самое интересное, что и не только для пользователей. Такой подход делает весь процесс простым и эффективным также для всех остальных участников турбизнеса: авиакомпаний, отелей, туроператоров и т. д.
Однако с технической точки зрения это все — огромный объем информации. Обработка такого количества данных одновременно была невозможной еще несколько лет назад. Но на 2014 год нет никакой проблемы в том, чтобы предоставить клиенту персонализированный сервис на основе данных о его предпочтениях. И подать все в виде понятного и простого интерфейса, с которым даже ребенок справится.
Что в этом полезного?
Вот несколько примеров того, как можно получить конкурентные преимущества, используя Big Data:
- Персонализация — анализируя информацию о клиенте можно предложить решения, разработанные для конкретного пользователя. Получая конкурентное преимущество в глазах клиента и не тратясь при этом на улучшение качества продукта.
- Динамическое ценообразование — анализ данных о рынке позволит установить самую привлекательную цену для конкретного клиента. Иногда получить доверие в будущем гораздо важнее и выгодней, чем максимальная прибыль прямо сейчас.
- Обслуживание клиентов — Big Data поможет создать у заказчика чувство собственной значимости. Он сможет убедиться, что продавцу не все равно. Ведь покупатель получит именно то, что хочет.
- Трекинг — возможность уведомлять клиентов о том, где их заказ, в каком состоянии и когда он дойдет до них.
- Прогнозный анализ — с Big Data становится возможным предугадывать события до того, как они произойдут, и делать необходимые приготовления или изменения.
Помимо всего прочего Big Data сейчас используют еще и для воздействия на клиентов на эмоциональном уровне. Клиенту дают понять, что он особенный, создавая тем самым между ним и брендом определенную связь. Это в прямом смысле слова культивирует лояльность.
Хорошим примером такого подхода может служить приложение, разработанное для бренда одежды Free People, которое обеспечило компании рост продаж на 38%. Приложение позволяет пользователям обсудить последние коллекции, поделиться своими фото в новых нарядах в Pinterest и Instagram, голосовать за самые лучшие снимки. Такое естественное взаимодействие очень эффективно. Без сомнения, это отличный вариант монетизации накопленных данных, и мы еще не раз сможем увидеть как ритейлеры и социальные платформы помогают друг другу достучаться до клиента.
Информационная перегрузка — это выгодно?
Все уже привыкли к тому, что найти хоть какую-нибудь действительно полезную информацию очень сложно. В блогах, социальных сетях люди всегда рады прочитать что-нибудь интересное. И именно благодаря инструментам Big Data теперь есть возможность предложить пользователю именно те факты, которые были отобранные специально для него на основе данных о предыдущих заказах, поисковых запросах, «лайках» в соцсетях и т. д.
Возьмем, к примеру, бизнес, связанный со спортом и фитнесом. Эта отрасль очень быстро развивается. Во многом благодаря успеху приложений, объединивших теорию и практику здорового образа жизни.
Будущее e-commerce — это объединение персональных целей (скинуть пару кило) с теорией (изучить новый курс тренировок) и коммерцией (купить новые кроссовки и тренажеры). Идеальное приложение не только даст общие рекомендации по тренировочным программам. Оно позволит пользователю заказать нужные спорттовары или другие продукты прямо здесь и сейчас. А продавец, основываясь на данных из таких приложений, сможет предложить клиенту персональные скидки, членство в клубе, программы лояльности и многое другое.
Хорошо это или плохо, но обслуживать клиентов, основываясь на их личных предпочтениях, сегодня можно только с помощью Big Data. Большие корпорации нанимают целые команды разработчиков, которые изучают их бизнес и создают уникальные приложения. Представители малого и среднего бизнеса используют более общие готовые решения. Но у всех цель одна — дать клиенту то, что он хочет, помогая тем самым e-commerce расти, развиваться и процветать.