Добавлен: 06.04.2023
Просмотров: 121
Скачиваний: 2
СОДЕРЖАНИЕ
ГЛАВА 1. СУЩНОСТЬ КОДИРОВАНИЯ ИНФОРМАЦИИ
1.1. Основные определения кодирования. Алфавит кодирования
1.2 Кодирование информации с помощью систем счисления
ГЛАВА 2. КОДИРОВАНИЕ ИНФОРМАЦИИ В СИСИТЕМЕ ОБРАБОТКИ ИНФОРМАЦИИ
2.1. Кодирование текстовой информации
2.2. Кодирование целых и действительных чисел
2.3. Кодирование графических данных
Позиционные системы счисления
Двоичная система счисления. В двоичной системе счисления основание равно 2, а алфавит состоит из двух цифр (0 и 1). Следовательно, числа в двоичной системе в развернутой форме записываются в виде суммы степеней основания 2 с коэффициентами, в качестве которых выступают цифры 0 или 1. [10, с.47]
Любое неотрицательное число в позиционной системе счисления может быть представлено в виде:
 ,
,
где а - основание системы счисления,
хi - разряды (числа от 0 до а-1), их обозначения образуют алфавит системы счисления,
аi - весовые коэффициенты (веса) разрядов,
n - число разрядов целой части числа,
р - число разрядов дробной части числа.
Например, число в десятичной системе счисления 57310=5*102+7*101+3*100
Число в двоичной системе счисления:

Позиционная система счисления - такая, в которой весовые коэффициенты определяются позицией разряда.
В вычислительной технике наиболее распространены: двоичная (binary, BIN), десятичная (decimal, DEC), шестнадцатеричная (hexadecimal, HEX) и непозиционная двоично-десятичная (binary coded decimal, BCD) системы исчисления. В BCD системе вес каждого разряда равен степени 10, как в десятичной системе, а каждая цифра i-го разряда кодируется 4-мя двоичными цифрами. Восьмеричная система счисления (octal, OCT) применяется реже. Следует отметить, что в цифровые устройства используют только двоичную систему счисления, так как построены на основе устройств с двумя состояниями. Другие системы счисления используются человеком только для удобства записи, т.е. для сокращенного (и часто более удобного) представления двоичных чисел.
Формат двоичного числа
|
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
1 |
|||||||
|
|
||||||||||||||||

Микропроцессоры обрабатывают упорядоченные двоичные наборы. Минимальной единицей информации является один бит (BInary digiT).
Далее следуют – тетрада, или ниббл (4 бита), байт (byte, 8 бит), двойное слово (DoubleWord 16 бит) или длинное (LongWord 16 бит) и учетверенное (32 бита) слова. Младший бит обычно занимает крайнюю правую позицию, старший - соответственно крайнюю левую, т.е. “старшинство” разрядов убывает слева направо.
Шестнадцатеричное представление двоичных чисел. Для перевода числа из двоичной системы в шестнадцатеричную, его необходимо разбить, начиная справа на тетрады - группы по 4 двоичных цифры - и каждую группу представить шестнадцатеричной цифрой из таблицы. Для обратного перевода каждая HEX цифра заменяется четверкой двоичных, незначащие нули слева иногда (но не всегда) отбрасываются. Нуль обычно не отбрасывается, если старший значащий знак обозначен буквой (см. таблицу).
Таблица 1.2
Двоичные и шестнадцатеричные (HEX) коды целых чисел от 0 до 15
|
Число10 |
Число2 |
Нех-код |
|
0 |
0000 |
0 |
|
1 |
0001 |
1 |
|
2 |
0010 |
2 |
|
3 |
0011 |
3 |
|
4 |
0100 |
4 |
|
5 |
0101 |
5 |
|
6 |
0110 |
6 |
|
7 |
0111 |
7 |
|
8 |
1000 |
8 |
|
9 |
1001 |
9 |
|
10 |
1010 |
A |
|
11 |
1011 |
B |
|
12 |
1100 |
C |
|
13 |
1101 |
D |
|
14 |
1110 |
E |
|
15 |
1111 |
F |
Пример: число 57310 = 10001111012 = 023D16 = 023Dh
Вывод по 1 главе
Для автоматизации работы с данными, относящимися к различным типам, используется приём кодирования, т.е. выражение данных одного типа через данные другого типа.
Мы в своей работе будем опираться на следующее определение: «Код (code) – это совокупность знаков, символов и правил представления информации».
Сигналы, реализующие коды, обладают одной из следующих характеристик:
-
- униполярный код (значения сигнала равны 0, +1, либо 0, -1 );
- полярный код (значения сигнала равны +1, -1);
- биполярный код (значения сигнала равны 0, +1, -1).
Последовательным является такой код, в котором знаки следуют один за другим во времени. Параллельным – тот, в котором знаки передаются одновременно, образуя символ.
Естественные языки обладают большой избыточностью, поэтому для экономии памяти, объем которой ограничен, имеет смысл ликвидировать избыточность текста или уплотнить текст.
Существуют несколько способов уплотнения текста.
-
- Переход от естественных обозначений к более компактным.
- Подавление повторяющихся символов.
- Кодирование часто используемых элементов данных.
- Посимвольное кодирование.
- Коды переменной длины.
Информация передается в виде сообщений. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые называются буквами. Буква в данном расширенном понимании - любой из знаков, которые некоторым соглашением установлены для общения.
В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразовываться в сообщение из символов (букв) другого алфавита. Саму процедуру преобразования сообщения называют перекодировкой.
Для записи информации о количестве объектов используются числа. Числа записываются с использованием особых знаковых систем, которые называются системами счисления.
Все системы счисления делятся на две большие группы: позиционные и непозиционные системы счисления. Самой распространенной из непозиционных систем счисления является римская. Наиболее распространенными в настоящее время позиционными системами счисления являются десятичная, двоичная, восьмеричная и шестнадцатеричная.
Первая позиционная система счисления была придумана еще в Древнем Вавилоне, в XIX веке довольно широкое распространение получила двенадцатеричная система счисления. В настоящее время человечество приняло в использование десятеричную систему счисления.
В позиционных системах счисления количественное значение цифры зависит от ее позиции в числе. Перевод из одной систему счисления в другую производится с помощью определенных правил, а в частности для двоичных, восьмеричных и шестнадцатеричных с использованием триад и тетрад, обеспечивающих удобство перевода.
ГЛАВА 2. КОДИРОВАНИЕ ИНФОРМАЦИИ В СИСИТЕМЕ ОБРАБОТКИ ИНФОРМАЦИИ
2.1. Кодирование текстовой информации
В процессе обработки информации, т.е. преобразования информации из одной формы представления (знаковой системы) в другую осуществляется кодирование. Средством кодирования служит таблица соответствия, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем. При вводе знака алфавита в компьютер путем нажатия соответствующей клавиши на клавиатуре выполняется его кодирование, т. е. преобразование в компьютерный код. При выводе знака на экран монитора или принтер происходит обратный процесс — декодирование, когда из компьютерного кода знак преобразуется в графическое изображение.
Текст состоит из символов, поэтому символ можно считать минимальным элементом текста. Если собрать все возможные символы, которые могут встретиться в тексте: латинские буквы, буквы кириллицы, знаки препинания и т. д., и каждому из этих символов присвоить свой уникальный номер (код символа), то текст можно записать в виде набора чисел.
Для хранения кода одного символа может быть выделен один байт. С помощью одного байта можно закодировать 256 различных символов, учитывая, что каждый бит принимает значение 0 или 1, и количество их возможных сочетаний в байте равно 28=256. Этого вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавитов, цифры, знаки, псевдографические символы и т. д [19, с.24].
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер — по их коду. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
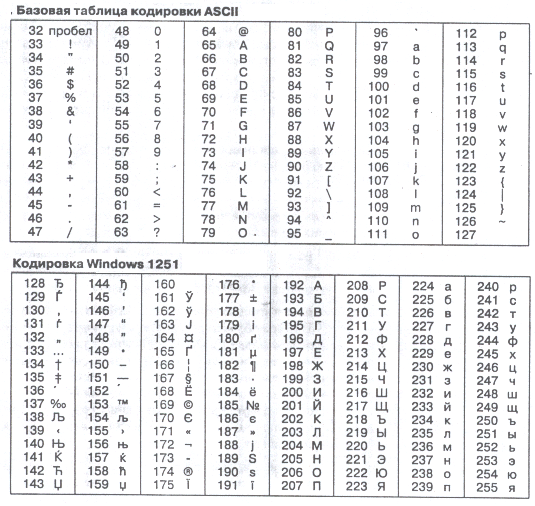
Существует несколько различных стандартов кодирования символов, но первоосновой для всех стал стандарт ASCII (American Standard Code for Information Interchange — американский стандартный код для информационного обмена).
В ASCII закреплены две таблицы кодирования: базовая и расширенная. В базовой таблице определены значения кодов с 0 по 127, а в расширенной — с 128 по 255. В базовой таблице находятся символы латинского алфавита, цифры, знаки арифметических операций и знаки препинания (табл. 1.1). Кроме того, за кодами с 0 по 32 закреплены специальные функции: перевод строки, ввод пробела и т. д. Расширенная таблица содержит символы национальных алфавитов различных стран мира и так называемые символы псевдографики, с помощью которых можно, например, рисовать таблицы [19, с.25].

Рис.2.1 Таблица кодов ASCII (расширенная)
Для языков, использующих кириллицу, в том числе и для русского, пришлось полностью менять вторую половину таблицы ASCII, приспосабливая её под кириллический алфавит. В частности, для представления символов кириллицы используется так называемая «альтернативная кодировка».
Альтернативная кодировка не подошла для ОС Windows. Пришлось передвинуть русские буквы в таблице на место псевдографики, и получили кодировку Windows 1251 (Win-1251). Кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» - компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение.
Сейчас существует несколько различных кодовых таблиц для русских букв (КОИ-8, СР-1251, СР-866, Мае, ISO), причём тексты, созданные в одной кодировке, могут совершенно неправильно отображаться в другой. Решается такая проблема с помощью специальных программ перевода текста из одной кодировки в другую [4. c.67].
Другая распространённая кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) – её происхождение относится к временам действия Совета Экономической Взаимопомощи государств Восточной Европы. Сегодня кодировка КОИ – 8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, в котором предусмотрена кодировка символов русского языка, носит названия ISO (International Standard Organization – Международный институт стандартизации). На практике данная кодировка используется редко.
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). Математикам требуется использовать в формулах специальные математические знаки, переводчикам необходимо создавать тексты, где могут встретиться символы из различных алфавитов, экономистам необходимы символы валют ($, F, А). Для решения этой проблемы была разработана универсальная система кодирования текстовой информации — UNICODE. В этой кодировке для каждого символа отводится не один, а два байта, то есть шестнадцать битов. Очевидно, что если, кодировать символы не восьмиразрядными двоичными числами, а числами с большим разрядом то и диапазон возможных значений кодов станет на много больше. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65536 различных символов – этого поля вполне достаточно для размещения в одной таблице символов большинства языков планеты. Этого хватает на латинский алфавит, кириллицу, иврит, африканские и азиатские языки, различные специализированные символы: математические, экономические, технические и многое другое.