ВУЗ: Томский государственный университет систем управления и радиоэлектроники
Категория: Методичка
Дисциплина: Базы данных
Добавлен: 28.11.2018
Просмотров: 2653
Скачиваний: 8
11
Приложения к конкретным примерам:
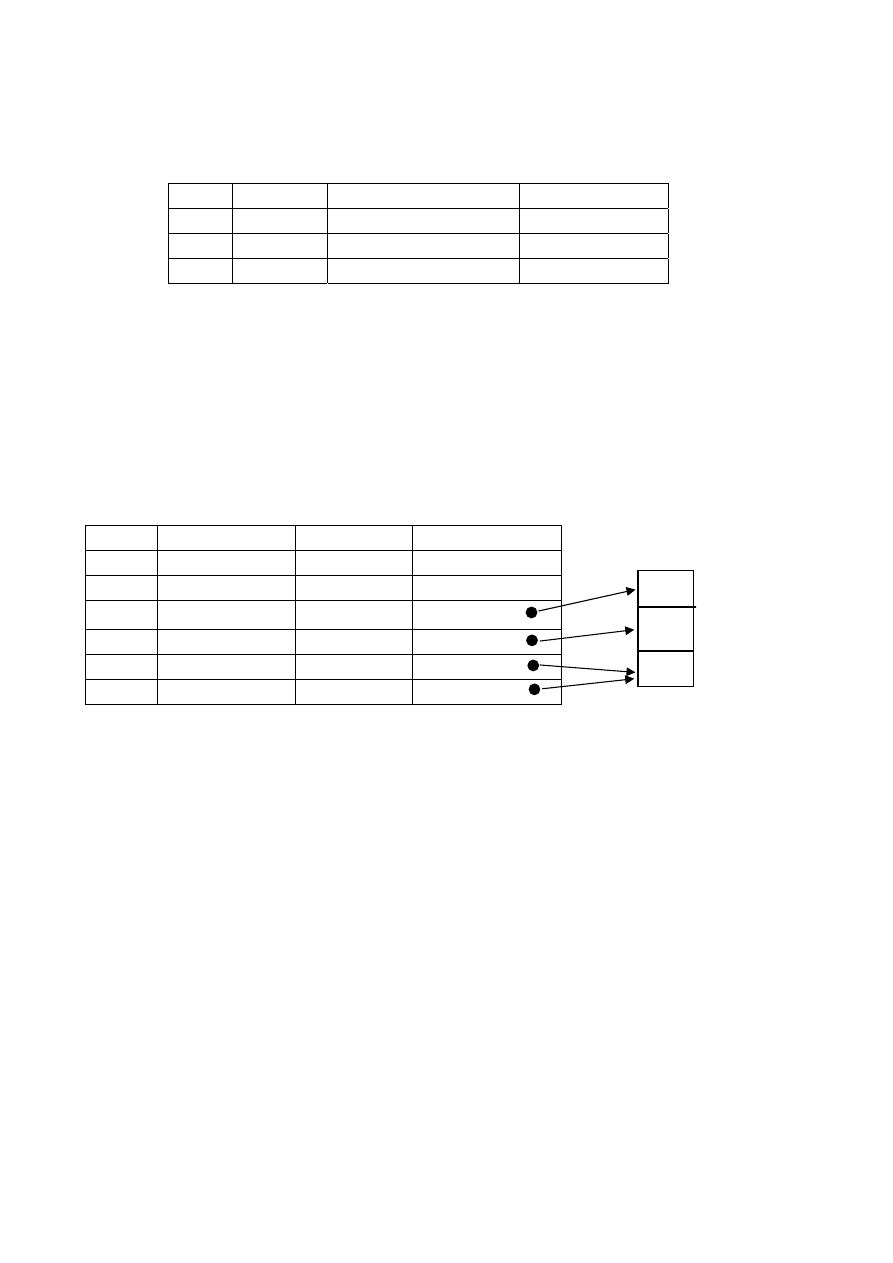
А) последовательный список – в приложении …. Поставщики
S# SNAME
Область
ГОРОД
S1
:
S5
единственным хранимым файлом, содержащим пять экземпляров хранимых
записей. Преимуществом данного варианта является простота. Однако,
если, предположим, что мы имеем 10000 поставщиков вместо 5 и все они
размещены только в 10 городах, то в данном случае предпочтительно исполь-
зовать связанное представление, т.е. УКАЗАТЕЛЬ на атрибут (в нашем
случае он занимает меньше памяти, чем название города).
В этом случае имеем два хранимых файла: файл поставщиков и файл го-
родов с указателями из первого файла во второй.
Файл Поставщики Файл
Город
S# SИМЯ
SОбласть
УКАЗАТЕЛЬ
S1
S2
М
S3
Л
S4
Т
S5
Т
Преимуществом данного способа является экономия памяти.
Примером многосписочной организации (или цепной структуры) мо-
жет служить вариант представления данных, когда бы соединили вместе
всех поставщиков одного и того же города. Другими словами мы имеем для
каждого города список соответствующих поставщиков.
4.
МЕТОДЫ
ДОСТУПА
К
ДАННЫМ
Проектирование физической БД включает также решение вопроса мето-
дов доступа к данным.
Под методом доступа понимается совокупность технических и про-
граммных средств, обеспечивающих возможность хранения и выборки дан-
ных, расположенных на физических устройствах ЭВМ.
В методе доступа выделяют два компонента:
-
структура памяти;
-
механизм поиска.
Наиболее широко используемыми методами доступа являются:
М
Л
Т

12
1)
последовательный;
2)
прямой и произвольный;
3)
индексно-последовательный;
4)
индексно-прямой;
5)
использование явных древовидных структур.
4.1.
Последовательный
доступ
Последовательный метод реализует доступ к данным базы данных путем
последовательного просмотра записей. (Обычно каждая запись располагается
в отдельном блоке). Причем записи могут быть упорядочены или неупорядо-
чены по значениям первичного ключа. Примером может служить создание
индексного файла в системе, например, FoxPro:
Создание индексного файла.
USE [имя файла.расширение]
INDEX ON [имя поля] TO USE MS1.DBF [имя файла]
Например, INDEX NAME TO NAMIDX.
Среднее количество физических блоков Nср., к которым осуществляется
доступ при поиске произвольной записи
Nср=(1+N)/2.
Данное выражение справедливо как для упорядоченных, так и неупоря-
доченных записей, при условии, что искомая запись существует.
Если искомая запись отсутствует, то для неупорядоченного файла
Ncp=N, т.е. будут проверены все записи.
Таким образом, неупорядоченный файл является неэффективным, если
приходится часто обращаться к поиску отсутствующей записи.
Кроме того, поскольку внесение изменений в произвольном порядке в
последовательную структуру требует большого количества операций по пе-
ремещению записей, режим внесения изменений строго ограничен.
4.2.
Прямой
доступ
В случае, когда имеется возможность выделить в памяти для каждой за-
писи место, определяемое уникальным значением ее первичного ключа, мож-
но построить простую функцию преобразования ключа в адрес, обеспечи-
вающую запоминание и выборку каждой записи в точности за один произ-
вольный доступ к блоку.
Прямой доступ является эффективным с точки зрения временных затрат
способом поиска данных в базе.
Методы прямого доступа подразделяют на две группы:
1)
доступ с помощью ключа, эквивалентного адресу;
2)
хэширование (метод произвольного доступа или рассеянной памяти).
13
Использование первой группы методов доступа возможно в тех случаях,
когда в качестве атрибута в запись включается адрес памяти, в котором будет
размещена запись. При работе с БД этот атрибут будет использоваться в ка-
честве ключа.
Методы второй группы используются для обеспечения быстрой выборки
и обновления записей по заданному значению первичного ключа.
Основная идея хэширования заключается в том, что каждый экземпляр
записи размещается в памяти по адресу, вычисляемому с помощью хэш-
функции (это специальная функция, вычисляемая от значения некоторого по-
ля в экземпляре записи – обычно значения первичного ключа).
В этом случае экземпляры записей хранятся не в последовательных
ячейках, выделенного блока памяти, а случайным образом рассеиваются по
всему блоку.
Причем, каждая новая запись помещается в блок памяти таким образом,
что ее присутствие или отсутствие может быть установлено без поиска по
всему блоку.
Другими словами, в методе хэширования строится отображение мно-
жества ключевых значений экземпляров записей во множество физических
адресов.
В качестве хэш-функции выбирается ПРАВИЛО, преобразующее значе-
ние типа записи в адрес.
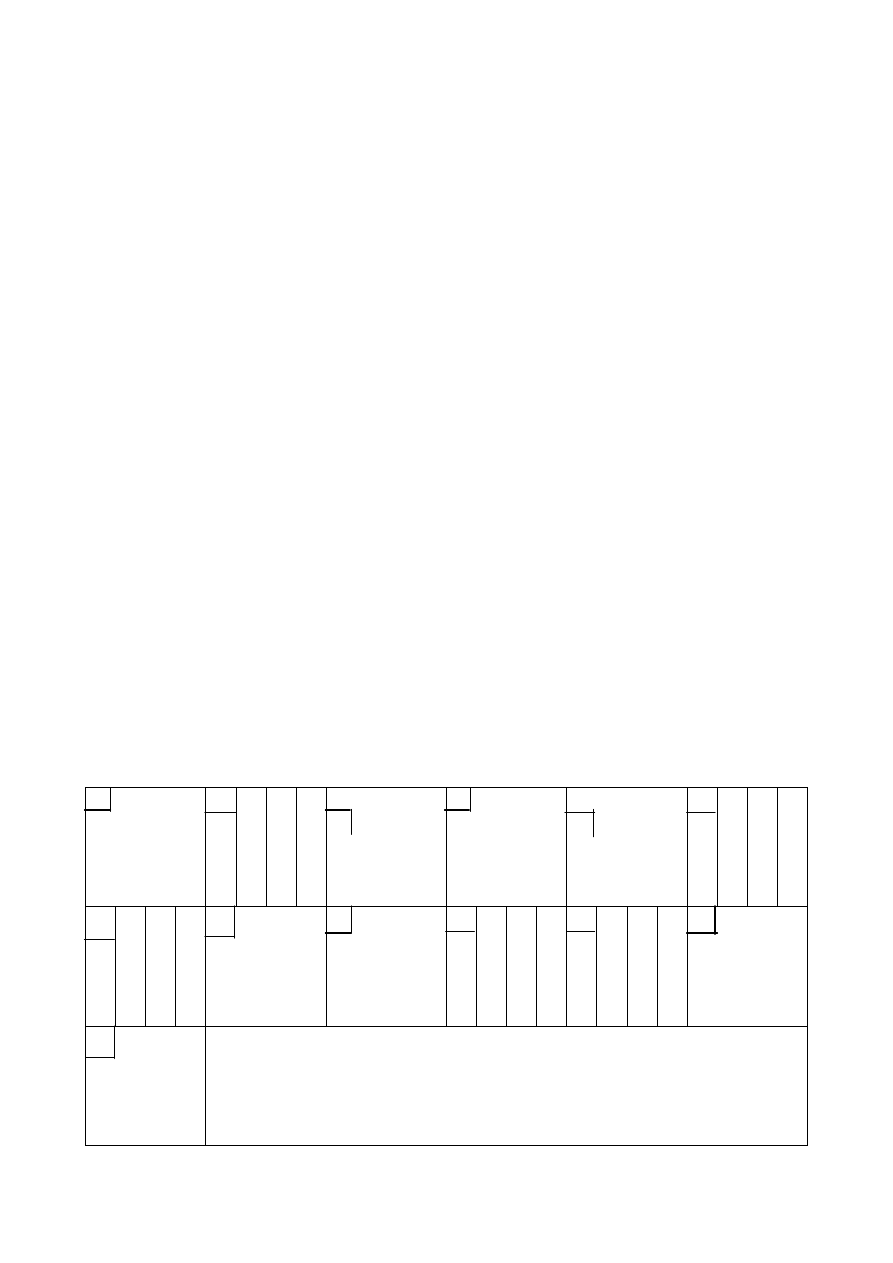
Простой пример общего класса хэш-функций: адрес хранимой записи =
остаток от деления на простое число «деление/остаток».
Рассмотрим пример хэш-адресации.
Предположим, что значениями S# является S100, S200, S300, S400, S500
(вместо S1,… S5). Адрес хранимых записей, например, равен остатку от деле-
ния S# на 13. Адресами хранимых записей в данном случае будут: 9,5,1,10,6,
соответственно.
0
S300
Пет
ров
Моск
ов
.
М
2 3 4
S200
S500
S1
000
S400
1
5
6
7
8
9
10
11
12

14
Для чего необходима хеш-функция? Теоретически возможно использо-
вать (числовое) значение первичного ключа в качестве адреса хранимой запи-
си.
Однако, этот вариант неприемлем из-за того, что диапазон значений пер-
вичного ключа обычно много шире диапазона доступных адресов хранимой
записи. Например, предположим, что максимальный номер поставщика мо-
жет быть 1000 (теоретически). На практике же их может, например, сущест-
вовать 10.
Чтобы избежать колоссальных издержек памяти, в идеальном случае не-
обходимо, чтобы хэш-функция переводила значение в диапазоне от 0-999 в
диапазон от 0-9.
Чтобы учесть возможное расширение в будущем, последний диапазон
обычно увеличен на 20% (в нашем примере 12).
Иногда, может возникнуть ситуация, когда, например, для различных за-
писей хэш-функция определит одинаковый адрес, т.е. имеется возможность
возникновения подобных коллизий. Для решения коллизий имеется много
способов:
-
метод последовательного сканирования;
-
метод цепочки.
Метод последовательного сканирования состоит в том, что при воз-
никновении коллизии просматриваются последовательно (сканируются) уча-
стки памяти, отведенные для хранения записей, до тех пор, пока не будет
найдена свободная позиция, куда и помещается запись.
Метод
цепочки
Вместо хранения самих элементов блока можно хранить в нем указатели
на связанные списки экземпляров записей, имеющих одинаковый хэш-адрес.
После хэширования экземпляра записи, если участок памяти по вычис-
ленному адресу занят, то происходит обращение по указанию к следующему
участку памяти (элементу списка), на который и помещается запись.
При поиске записей действия выполняются в той же последовательно-
сти. В начале проверяется участок памяти по вычисленному адресу. Если там
находится запись с другим значением ключа, то по указателю обращаются к
следующей записи и так до тех пор, пока не будет найдена необходимая за-
пись.
Память, выделяемую для организации списков, называют областью
переполнения.
15
4.3.
Индексно
-
последовательный
метод
доступа
Он строится на основе упорядоченного физически последовательного
файла и иерархической структуры индексов блоков, каждый из которых упо-
рядочен по значениям первичных ключей (подобно записям в файле данных).
Данный метод позволяет обеспечивать как последовательный, так и про-
извольный доступ к данным.
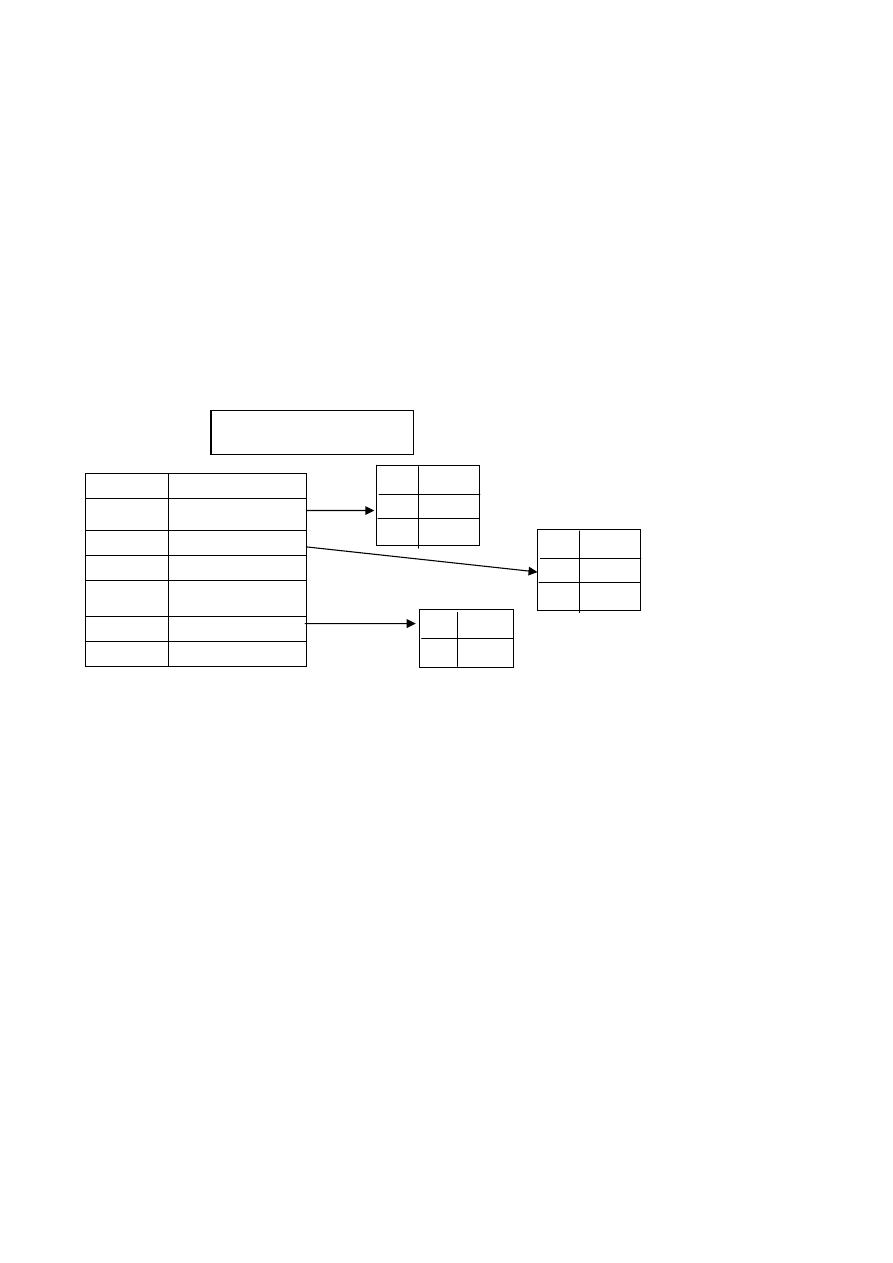
С этой целью в рассмотрение вводится новый параметр. Индекс блока –
это упорядоченная таблица значений первичных ключей, в которой каждый
элемент блока содержит наибольшее значение ключа среди всех записей в
указанном блоке. С каждым значением ключа в индексе связан указатель со-
ответствующего блока.
КЛЮЧ УКАЗАТЕЛЬ
12 1
25 2
41 3
57 4
73 5
Рис. 4.1. Организация индекса блока
Смысловые организации
Записи организованы последовательно, но имеется дополнительный ин-
декс (указатель), позволяющий обращаться к записям в произвольном поряд-
ке.
Механизм поиска
Поиск экземпляра записи осуществляется посредством первоначального
установления номера блока, в котором может находится запись, а затем по-
следовательного поиска в этом блоке, пока не будет установлено местонахо-
ждение искомой записи или ее отсутствие.
Данный метод позволяет обеспечивать быстрый доступ к записям баз
данных и файлов большой размерности, в которых поиск по одному только
индексу (ключу) приводит к значительным затратам времени.
Недостатки:
Индекс БЛОКА
3
6
12
14
17
29
68
73