ВУЗ: Томский государственный университет систем управления и радиоэлектроники
Категория: Методичка
Дисциплина: Базы данных
Добавлен: 28.11.2018
Просмотров: 2658
Скачиваний: 8
21
-
низкая надежность;
-
низкая общая производительность;
-
большие затраты на разработку.
Достоинства централизованных БД: они обеспечивают безопасность,
целостность и непротиворечивость информации (при обновлении особенно).
Для решения перечисленных проблем необходимо провести децентра-
лизацию данных.
При этом достигается:
-
более высокая степень одновременности обработки вследствие рас-
пределения нагрузки;
-
улучшенное использование данных на местах при выполнении уда-
ленных (дистанционных) запросов;
-
меньшие затраты;
-
простота управления.
Чем обусловлена децентрализация? Затраты на создание сети, в узлах
которой находятся малые ЭВМ, гораздо ниже, чем затраты на создание ана-
логичной системы с использованием большой ЭВМ.
Допустим, существует система обработки банковских операций на осно-
ве сети.
Клиент А – работает с системой с помощью локальных запросов (гео-
графический принцип).
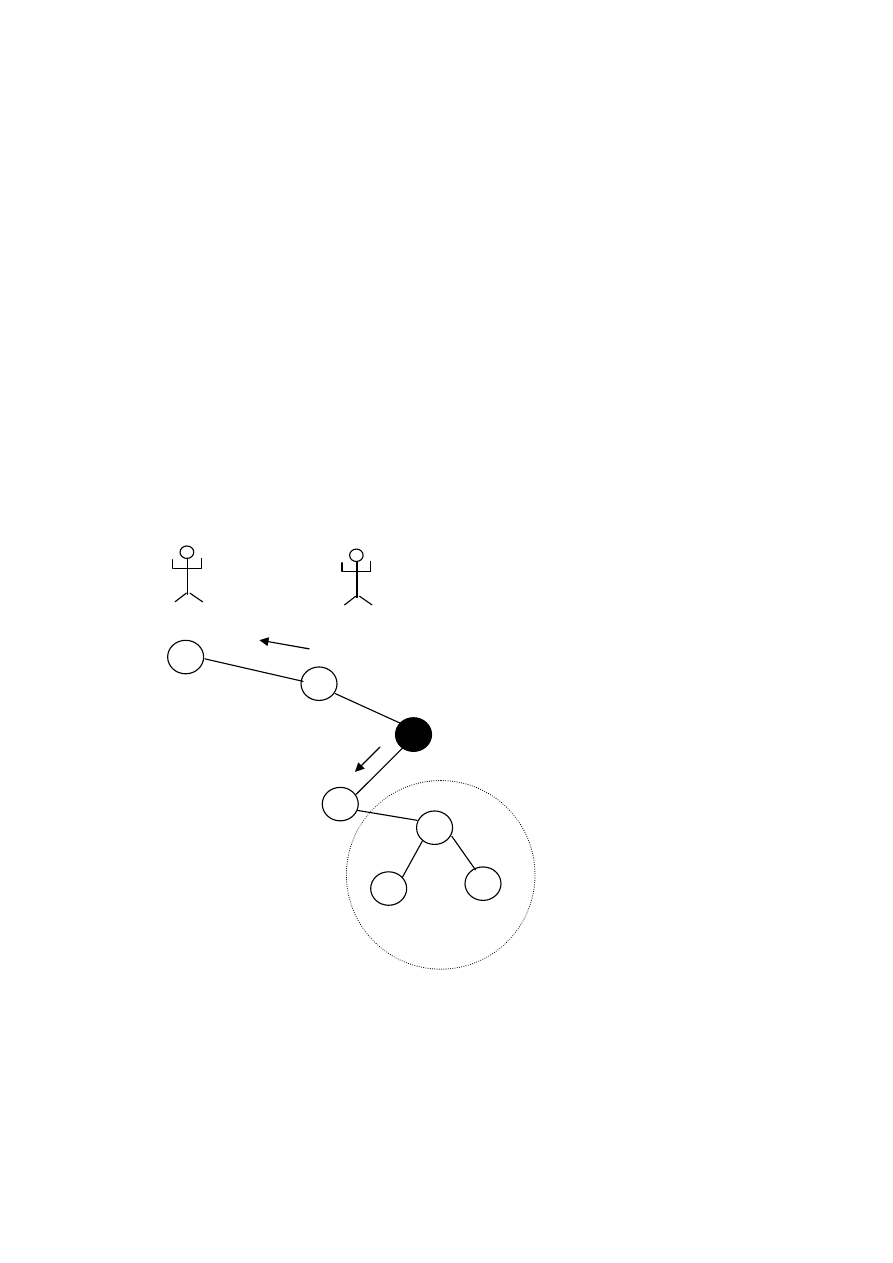
Город А
Удаленный доступ
Город Б
Головное
учреждение
Локальный
доступ
(географи-
ческий
доступ)
Глобальный
удаленный
доступ
Функциональ-
ная локальность
обращений
Модели доступа в распределенных базах данных

22
Если он в городе Б – например, имеет счет в банке этого города и хочет
получить вклад, для проверки его счета в банке будет выдан удаленный за-
прос.
Глобальные удаленные запросы – запросы головного учреждения.
Функциональная локальность обращений – обмены информацией на
основе локальных запросов (например, кредитные операции на уровне одного
района).
Итак, запросы бывают: локальные, удаленные и глобальные удаленные.
5.1.
Проблемы
распределенных
баз
данных
Основная задача распределенной БД – распределение данных по сети.
Существуют следующие способы решения этой задачи:
а) Разделенное распределение, т.е. такое при котором в каждом узле
хранится и используется собственный набор данных, доступный для удален-
ных запросов.
б) Частично-дублированное распределение, т.е. некоторые данные,
часто используемые на удаленных узлах, могут дублироваться.
в) Полностью дублированное распределение – когда все данные дуб-
лируются в каждом узле.
г) Расщепленное (фрагментированное) распределение, когда некото-
рые файлы могут быть расщеплены горизонтально (выделено подмножество
записей) или вертикально (выделено подмножество полей (атрибутов)), при
этом, выделенные подмножества хранятся в различных файлах вместе с не-
расщепленными данными.
д) Выделенные подмножества могут дублироваться, как в п)п) п.п. б) и
в).
Проблемы и принципы создания распределенных баз данных. Какова об-
щая модель данных распределенной системы?
1.
Распределенная база данных должна иметь единую концептуальную
схему всей сети. Это обеспечивает логическую прозрачность данных для
пользователя, в результате чего он сможет формировать запрос ко всей базе,
находясь за отдельным терминалом. То есть, пользователь работает как бы с
централизованной Базой Данных.
2.
Необходима схема, определяющая местонахождения данных в сети,
что обеспечивает прозрачность размещения данных, благодаря которой
пользователь может не указывать, куда переслать запрос, чтобы получить
требуемые данные.
3.
Распределенные базы данных могут быть однородными или неодно-
родными в смысле аппаратных и программных средств (СУБД).
Проблему неоднородности легко решить, если распределенная база дан-
ных является неоднородной в смысле аппаратных средств, но однородной в
смысле программных средств (одинаковые СУБД в узлах).

23
Если же в узлах распределенной базы данных используются разные
СУБД, необходимы средства преобразования структур данных и языков, то
есть, необходима прозрачность преобразования в узлах распределенной
базы данных.
4.
Управление словарями. Кроме того, для обеспечения всех видов про-
зрачности в распределенной базе данных нужны программы, управляющие
многочисленными справочниками или словарями.
5.
Методы выполнения запросов в распределенной базе данных должны
быть скоординированы: так как отдельные части запроса нужно выполнять
на месте расположения соответствующих данных и передавать частичные
результаты на другие узлы.
6.
В распределенной базе данных нужен сложный механизм управления
одновременной обработкой, который должен обеспечивать синхронизацию
при обновлениях информации, что гарантирует непротиворечивость дан-
ных.
7.
Развитая методология распределения и размещения данных, включая
расщепление, является одним из основных требований к распределенной базе
данных.
5.2.
Выполнение
запросов
в
распределенной
базе
данных
При выполнении запроса в распределенной базе данных выполняется две
задачи:
-
декомпозиция запроса;
-
оптимизация запроса.
Декомпозиция запроса. Так как данные распределены, а также могут
быть расщеплены, запросы, составленные пользователем, который рассмат-
ривает данные целиком (как если бы база данных была централизованной),
должны быть приведены к виду, учитывающему распределение и расщепле-
ние данных.
Декомпозиция обусловлена тем, что программа запроса не может быть
выполнена полностью в одном узле, если там не хранится вся требуемая ин-
формация.
Оптимизация вызвана тем, что для завершения выполнения программы
необходимо перемещать целые отношения (файлы) или результаты промежу-
точных вычислений.
Пример: рассмотрим базу данных распределенную по трем узлам, схема
которой состоит из трех отношений:
(С) СЛУЖАЩИЕ (СЛ#, ОТД#, ИМЯ#, ЗАРПЛАТА, РУКОВОДИТЕЛЬ)
(О) ОТД (ПОДРАЗДЕЛЕНИЕ#, ОТД#, ПРОЕКТ#)
(Р) РАЗМЕЩЕНИЕ (ПОДРАЗДЕЛЕНИЕ#, ГОРОД).
Рассмотрим запрос: как зовут служащих, работающих в отделах подраз-
деления, расположенного в Нью-Йорке.

24
1)
Пусть все отношения распределены по разным узлам.
2)
Прием решения задачи «в лоб»: переместим все отношения в узел за-
проса и обработаем запрос, как для централизованной базы данных (это до-
рогой способ).
Представим этот запрос в терминах реляционного исчисления:
RANGE OF (C,O,P) IS (СЛУЖАЩИЕ, ОТД, РАЗМЕЩЕНИЕ)
RETRIEVE W (C.ИМЯ) WHERE(P.ГОРОД=’НЬЮ-ЙОРК’)
AND(P.ПОДРАЗД#=О.ПОДРАЗДЕЛЕНИЕ#)
AND(O.ОТД#=C.ОТД#).
1)
в этом запросе 3 картежные переменные (СЛУЖАЩИЕ, ОТДЕЛ,
РАЗМЕЩЕНИЕ).
Для упрощения запроса отделим в нем часть, содержащую одну пере-
менную: (операция селекция):
Q – исходный запрос
RANGE OF P IS РАЗМЕЩЕНИЕ
RETRIEVE ВРЕМЕН. (Р.ПОДРАЗДЕЛЕН#)
Создаем временный кортеж
WHERE P.ГОРОД=’НЬЮ-ЙОРК’
RANGE OF (C,О,Р) IS (СЛ., ВРЕМ.)
RETRIEVE W (C.ИМЯ) WHERE
(P.ПОДРАЗДЕЛЕНИЕ#=O.ПОДРАЗДЕЛЕНИЕ#)
AND (O.ОТД#=С.OTД#)
Аналогично можно отделить еще один запрос с одной переменной от за-
проса Q
2
и повторять этот запрос, пока не останется запрос с одной перемен-
ной.
Такое отделение возможно, так как значения соединяемых атрибутов из
кортежей, выбранных во время начальной редукции, становятся предикатами
соединения. Этот процесс называется подстановкой кортежей.
Процесс рекурсивно повторяется для всех кортежей исходных отноше-
ний, а результат получается путем объединения отдельных редукций (соеди-
нений), полученных в процессе подстановки кортежей.
Для распределенной базы данных это означает: над каждым отношением
(селекция либо проекция) редукция может быть произведена на месте его
хранения, а выбранные атрибуты (или кортежи, если требуется соединение)
пересылаются в узел, где производится очередное соединение.
Из области
Область узла запроса
отыскать
Q
1
Q
2
Q
3
Q
1
Q
2
Q
3
25
При подходе «снизу вверх» нужно передавать атрибут СЛУЖАЩИЕ.
ИМЯ при выполнении всех соединений (т.е. методика обработки запросов).
Оптимизация
запроса
Оптимизация запроса основана:
-
на перестановке операций в пределах запроса;
-
на идентификации общих подвыражений и однократном их выполне-
нии;
-
на трансляции и оптимизации запроса относительно фрагментов.
Существуют различные способы выполнения запросов: «сверху вниз»
(Q
1
→Q
2
→Q
3
), «снизу вверх» (Q
3
→Q
2
→Q
1
). Способ “сверху вниз” более эко-
номичен как с точки зрения времени выполнения, так и объема перемещае-
мых данных. Это объясняется тем, что мы начинаем с редукции (т.е. селек-
ции), а затем может использоваться полусоединение, для которого нужно пе-
редавать только значения соединяемых атрибутов.
Методика
оптимизации
запроса
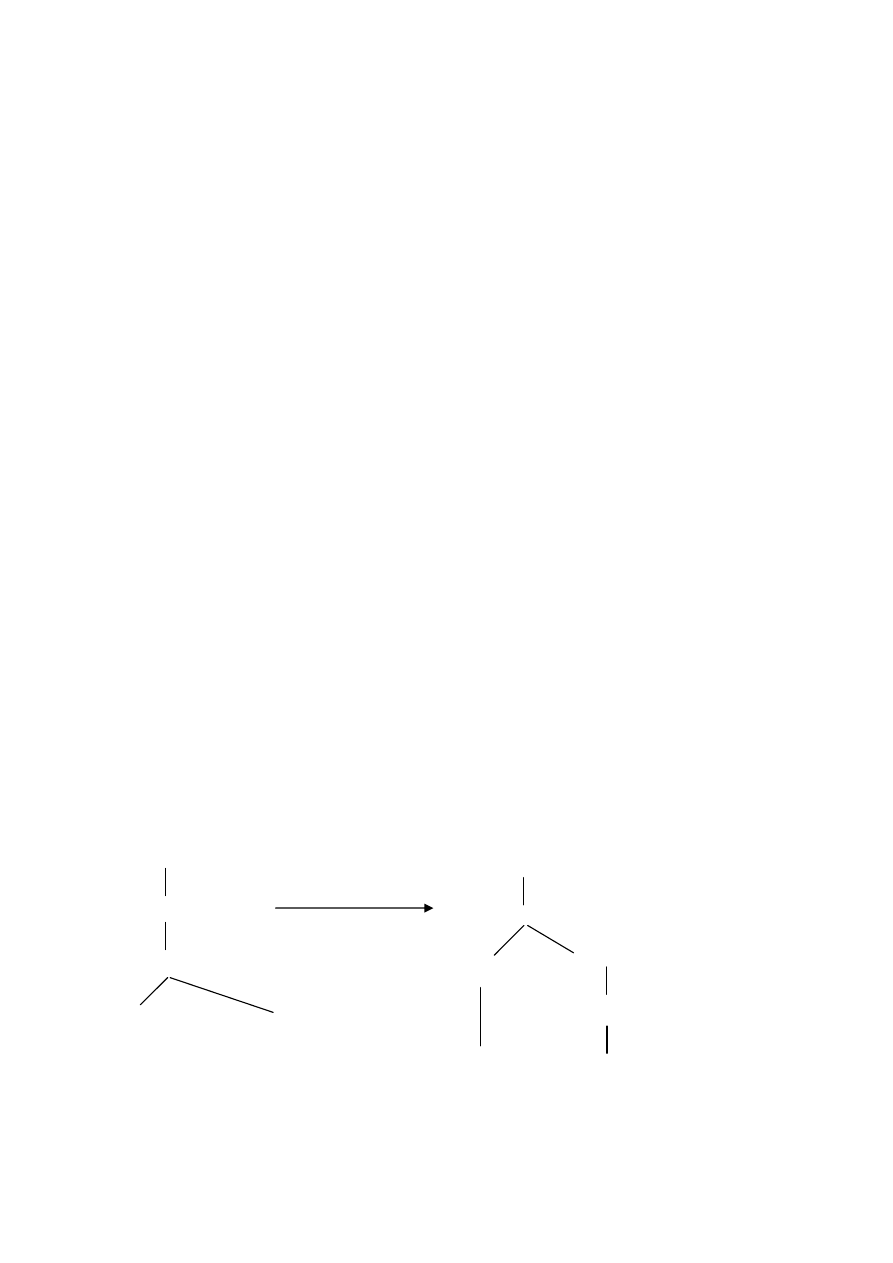
Оптимизация запроса начинается с построения дерева разбора для выра-
жения запроса.
В этом дереве:
листья – соответствуют отношениям
внутренние узлы (включая корень) – операциям реляционной алгебры.
Например,
«Как зовут служащих, работающих над проектом 5#».
Соответствующее выражение реляционной алгебры
((служащие * отдел)[ПРОЕКТ#=5])[ИМЯ].
Итак, используем отношения: СЛУЖАЩИЕ, ОТДЕЛ в [ ] – имена рас-
смотренных полей. Порядок операций – слева направо;
[ИМЯ]
[ПРОЕКТ#=5]
* (т.е. ОТД#=ОТД#)
СЛУЖАЩИЕ ОТД
в результате
оптимизации
[ИМЯ]
* (т.е. ОТД#=ОТД#)
[ОТД#]
[ИМЯ,ОТД# ]
[ПРОЕКТ#=5 ]
ОТД
СЛУЖАЩИЕ
а)
б)