Добавлен: 31.01.2019
Просмотров: 370
Скачиваний: 11
-
Теорема о вероятности суммы событий
Теорема сложения вероятностей
Суммой двух случайных событий А и В называется события А + В состоящие в наступление хотя бы одного из событий А или В.
А
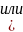 В: 1) только А или 2) только В или 3) А и В
В: 1) только А или 2) только В или 3) А и В
А + В: 1) только А или 2) только В
Теорема сложения для 2-х несовместных событий
Если А и В – несовместны, то вероятность наступления только одного из двух несовместных событий равна сумме вероятностей этих событий Р(А+В) = Р(А)+Р(В)
Следствие: эта теорема применима для любого конечного числа несовместных событий Р(А+В+С) = Р(А)+Р(В)+Р(С)
Теорема сложения для полно группы событий
Пусть
события В₁,
В₂,…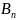 образуют полную группу. Сумма вероятностей
событий, образующих полную группу равна
1. Р(В₁)+Р(В₂)+…+Р(
)=1
образуют полную группу. Сумма вероятностей
событий, образующих полную группу равна
1. Р(В₁)+Р(В₂)+…+Р(
)=1
Теорема сложения для противоположных событий
Р(Ā)+Р(А)=1. Сумма вероятностей противоположных событий равна 1.
-
Условные вероятности. Теорема о вероятности произведения событий
Теорема умножения вероятностей
Пусть любое случайное событие называется событие А и В, состоящие в совместном наступление событий А и В
Случайное событие (с.с.) – то, что может произойти или не произойти при осуществление определенной совокупности условий S
Если никаких других ограничений кроме условия S на случайное событие не накладывается, то вероятность этого события называется безусловной и обозначается Р(А)
Условной
вероятностью события В называется
вероятность этого события, вычисленную
в предположении, что событие А уже
произошло и обозначается
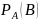
Событие
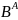 называется зависимым
о события А, если вероятность события
В изменяется в зависимости от того,
происходит ли событие А или нет. Если
не изменяется, то событие А и В –
независимы
называется зависимым
о события А, если вероятность события
В изменяется в зависимости от того,
происходит ли событие А или нет. Если
не изменяется, то событие А и В –
независимы
Теорема
Пусть А и В – зависимое с.с.
Р(А*В)
= Р(А)*
Вероятность совместного наступления двух зависимых событий равна произведению вероятности одного, на условную вероятность другого, вычисленную предположением, что первое событие уже произошло
Теорема
Пусть А и В – независимое с.с.
= Р(В)
Так как вероятность события В не изменяется в зависимости от того, происходит событие А или нет
Теорема
Пусть А и В – независимое с.с.
Р(А*В) = Р(А)*Р(В)
Вероятность совместного наступления всех независимых событий равна произведению вероятностей этих событий
Теорема
Пусть А,В,С…К, L – зависимое с.с
Р(А,В,С…К,
L)
= Р(А)*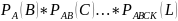
Вероятность совместного наступления конечного числа зависимых событий равна произведению условных вероятностей этих событий относительных произведению предшествующих каждому из них
Теорема
Пусть А,В,С…К, L – независимое с.с.
Р(А,В,С…К, L ) = Р(А)*Р(В)*Р(С)…*Р(L)
Вероятность наступления конечного числа независимых событий равна произведению вероятностей этих событий
-
Формула полной вероятности
Пусть
событие А может произойти лишь при
условии наступления одного из независимых
событий В₁,
В₂,..
, которые образуют полную группу. В этом
случае вероятность события А можно
найти из теоремы
Теорема
Р(А)
= Р(В₁)*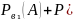 )*
)*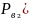 А)+…+Р(
А)+…+Р(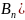 *
*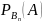 – формула полной вероятности
– формула полной вероятности
Вероятность
события А, которое может произойти лишь
при условии наступления одного из
независимых событий В₁, В₂,..
,
которые образуют полную группу, равна
сумме произведений вероятности этих
событий на соответствующую условию
вероятность события А
-
Формула Байеса
Р(А)
– вероятность события А, которое может
наступить лишь при условии появления
одного из несовместных событий В₁,
В₂,..
,
которые образуют полную группу.
В
связи с тем, что не известно, которое
из событий В₁,
В₂,..
произойдет, эти события называются
предположениями или гипотезами. Выясним,
как изменится вероятность каждой из
гипотез в связи с наступающим событием
А, т.е. вычислим условие вероятности
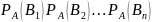
Найдем вероятность совместного наступления событий А и В₁. Используем теорему умножения для 2-х зависимых событий
Р(А*В₁)
= Р(А)*
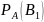
Р(В₁*А)
= Р(В₁)*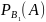
Т.к. в левой части обоих формул находятся вероятность одного и того же события, левые части равны, равны и правые
Р(А)*
=
Р(В₁)*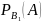
Аналогично можно получить формулы для условных вероятностей остальных гипотез
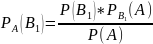
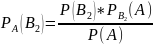
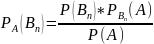
Эти
формулы называются формулой Байеса в
которых вероятность А в значении
находится по формуле полной вероятности:
Р(А) = Р(В₁)*
+ Р(В₂)*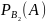 +…+
Р(
)*
+…+
Р(
)*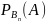
-
Последовательность независимых испытаний
Испытание называется независимым относительно события А, если вероятность появления этого события в каждом испытании не зависит от резервов в других испытаниях, где А – событие, появление которого интересует нас в каждом испытании.
Рассмотрим случай независимых испытаний, вероятность появления события А в каждом из которых есть величина постоянная
Р(А) = р Р(А) = q
Из теоремы сложения вероятности противоположных событий Р(А)+Р(Ā) = 1 следует, что Р(Ā) = q = 1 – p
Вероятность отклонения относительной частоты от постоянной вероятности в независимых испытаниях
-
Если испытание независимо
-
Вероятность наступления события А – постоянна (в каждом испытании), то вероятность отклонения относительной частоты
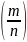 от
постоянной вероятности (р) вычисляется
по формуле
от
постоянной вероятности (р) вычисляется
по формуле
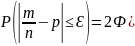
-
Формула Бернулли
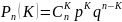
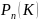 – вероятность
того, что в n
независимых испытаниях событие А
произойдет равно К раз
– вероятность
того, что в n
независимых испытаниях событие А
произойдет равно К раз
В общем случае можно утверждать, что вероятность наступления события А в n независимых испытаниях:
-
не менее К раз:
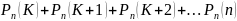
-
не более К раз
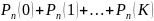
-
более К раз
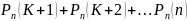
-
менее К раз
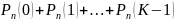
-
Предельные теоремы Муавра – Лапласа
Локальная теорема Лапласа
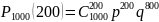
Если
число испытаний n
велико, то вычисляется вероятность
по формуле Бернулли довольно трудоемко.
В этом случае можно использовать
локальную теорему Лапласа: если
вероятность р появления события А в
каждом независимом постоянна и не равна
0 и 1, то вероятность
того, что события А произойдет в n
независимых испытаниях равно К раз
приближенным (тем точнее, чем больше
n)
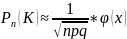
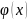 -
функция вероятности
-
функция вероятности
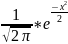 эта функция находится по таб.
эта функция находится по таб.
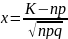
Чтобы
правильно пользоваться таблицей
рассмотрим некоторые свойства
:
-
-
четная функция
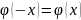
-
– монотонно
убывающая функция
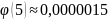 для х>5
можно считать, что
для х>5
можно считать, что
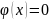
Интегральная теорема Лапласа
В
предыдущих темах была решена задача о
нахождение вероятности того, что в n
независимых испытаниях событие А
произойдет ровно К раз. Но часто
необходимо знать вероятность наступления
событий неопределённое число раз , а
число раз заключается в некотором
интервале
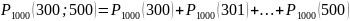 это решение довольно трудоемко и ответ
на поставленный вопрос можно получить
сразу с помощью интегральной теоремы
Лапласа: вероятность того, что в n
независимых испытаниях в каждом из
которых вероятность появления события
наступит не менее К₁
и не более К₂
раз, при р равном (0<р<1)
это решение довольно трудоемко и ответ
на поставленный вопрос можно получить
сразу с помощью интегральной теоремы
Лапласа: вероятность того, что в n
независимых испытаниях в каждом из
которых вероятность появления события
наступит не менее К₁
и не более К₂
раз, при р равном (0<р<1)
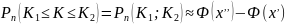
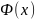 – функция Лапласа
находящаяся по таблице
– функция Лапласа
находящаяся по таблице
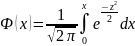
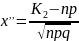
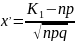
Чтобы правильно пользоваться таблицей рассмотрим некоторые свойства функции Лапласа:
-
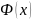 – нечетная, т.е.
– нечетная, т.е.
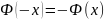
-
является монотонно
возрастающей
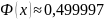 ,
поэтому для х>5
можно считать, что
,
поэтому для х>5
можно считать, что
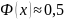
-
Случайные величины
Переменные величины которые принимают различные значения в зависимости о случая, называются случайные величины
Обозначаются: заглавными латинским буквами X;Y;Z..
значение, которое принимают случайные величины в результате испытания, называют ее возможные значения
Х – число очков, выпавших при подбрасывание игральной кости: х₁=1, х₂=2,х₃=3,х₄=4,х₅=5,х₆=6
Случайные величины подразделяются на 2 вида: дискретные и непрерывные
Дискретной называют случайную величину, возможное значение которой образует дискретный ряд чисел. Число этих значений может быть конечным и бесконечным.
Непрерывной называют случайную величину, возможное значение которой полностью заполняет некоторый промежуток (конечный или бесконечный) . Число всегда бесконечно
-
Закон распределения дискретной случайной величины
Для задания дискретной случайной величины недостаточно перечислить все ее возможные значения, нужно указать еще и их вероятность.
Законом распределения дискретной случайной величины называют соответствие между возможными значениями случайной величины и вероятностями их появления.
Закон распределения можно задать таблично, аналитически (в виде формулы) или графически (в виде многоугольника распределения).
Рассмотрим случайную величину X, которая принимает значения x1, x2, x3 ... xn с некоторой вероятностью pi, где i = 1.. n. Сумма вероятностей pi равна 1.
Таблица соответствия значений случайной величины и их вероятностей вида
x1 x2 x3 ... xn ... p1 p2 p3 pn
называется рядом распределения дискретной случайной величины или просто рядом распределения. Эта таблица является наиболее удобной формой задания дискретной случайной величины.
-
Числовые характеристики дискретных случайных величин
Закон распределения полностью характеризует дискретную случайную величину. Однако, когда невозможно определить закон распределения, или этого не требуется, можно ограничиться нахождением значений, называемых числовыми характеристиками случайной величины:
Математическое ожидание, Дисперсия, Среднее квадратичное отклонение
Эти величины определяют некоторое среднее значение, вокруг которого группируются значения случайной величины, и степень их разбросанности вокруг этого среднего значения.
Математическое ожидание M дискретной случайной величины - это среднее значение случайной величины, равное сумме произведений всех возможных значений случайной величины на их вероятности.
|
|
Определение
функции распределения Действительно, рассмотрим случайную величину , возможные значения которой сплошь заполняют интервал . Можно ли составить перечень всех возможных значений ? Очевидно, что этого сделать нельзя. Этот пример указывает на целесообразность дать общий способ задания любых типов случайных величин. С этой целью и вводят функции распределения вероятностей случайной величины. Пусть — действительное число. Вероятность события, состоящего в том, что примет значение, меньшее , т.е. вероятность события , обозначим через . Разумеется, если изменяется, то, вообще говоря, изменяется и , т.е. — функция от .Функцией распределения называют функцию , определяющую вероятность того, что случайная величина в результате испытания примет значение, меньшее , т.е. Геометрически это равенство можно истолковать так: есть вероятность того, что случайная величина примет значение, которое изображается на числовой оси точкой, лежащей левее точки .Иногда вместо термина «функция распределения» используют термин «интегральная функция». Теперь можно дать более точное определение непрерывной случайной величины: случайную величину называют непрерывной, если ее функция распределения есть непрерывная, кусочно-дифференцируемая функция с непрерывной производной. |
-
Плотность распределения вероятностей НСВ. Вероятность попадания НСВ. Свойства плотности распределения. Числовые характеристики НСВ.
Определение и свойства функции распределения сохраняются и для непрерывной случайной величины, для которой функцию распределения можно считать одним из видов задания закона распределения. Но для непрерывной случайной величины вероятность каждого отдельного ее значения равна 0. Это следует из свойства 4 функции распределения: р(Х = а) = F(a) — F(a) = 0. Поэтому для такой случайной величины имеет смысл говорить только о вероятности ее попадания в некоторый интервал.
Вторым способом задания закона распределения непрерывной случайной величины является так называемая плотность распределения (плотность вероятности, дифференциальная функция).
Определение 5.1. Функция f(x), называемая плотностью распределения непрерывной случайной величины, определяется по формуле:
f (x) = F′(x),
то есть является производной функции распределения.
Свойства плотности распределения.
1) f(x) ≥ 0, так как функция распределения является неубывающей.
2) , что следует из определения плотности распределения.
3) Вероятность попадания случайной величины в интервал (а, b) определяется формулой Действительно,
4) (условие нормировки). Его справедливость следует из того, что а
5) так как при
Таким образом, график плотности распределения представляет собой кривую, располо-женную выше оси Ох, причем эта ось является ее горизонтальной асимптотой при (последнее справедливо только для случайных величин, множеством возможных значений которых является все множество действительных чисел). Площадь криволинейной трапеции, ограниченной графиком этой функции, равна единице.
Замечание. Если все возможные значения непрерывной случайной величины сосредоточе-ны на интервале [a, b], то все интегралы вычисляются в этих пределах, а вне интервала [a, b] f(x) ≡ 0.
Основные числовые характеристики дискретных и непрерывных случайных величин: математическое ожидание, дисперсия и среднее квадратическое отклонение. Их свойства и примеры. Закон распределения (функция распределения и ряд распределения или плотность веро-ятности) полностью описывают поведение случайной величины. Но в ряде задач доста-точно знать некоторые числовые характеристики исследуемой величины (например, ее среднее значение и возможное отклонение от него), чтобы ответить на поставленный во-прос. Рассмотрим основные числовые характеристики дискретных случайных величин. Математическое ожидание. Определение 7.1. Математическим ожиданием дискретной случайной величины называ-ется сумма произведений ее возможных значений на соответствующие им вероятности: М(Х) = х1р1 + х2р2 + … + хпрп . (7.1)Если число возможных значений случайной величины бесконечно, то , если полученный ряд сходится абсолютно. Замечание 1. Математическое ожидание называют иногда взвешенным средним, так как оно приближенно равно среднему арифметическому наблюдаемых значений случайной величины при большом числе опытов. Замечание 2. Из определения математического ожидания следует, что его значение не меньше наименьшего возможного значения случайной величины и не больше наибольше-го. Замечание 3. Математическое ожидание дискретной случайной величины есть неслучай-ная (постоянная) величина. В дальнейшем увидим, что это же справедливо и для непре-рывных случайных величин. |
|
|
14. Нормальное распределение.
Нормальный закон распр-я н.с.в. – закон, который хар-ся след.пл-тью распр-я .
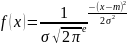 →
норм-ый закон
опред-ся двумя параметрами а
и ( жигма)
→
норм-ый закон
опред-ся двумя параметрами а
и ( жигма)
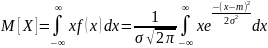 =
а
=
а
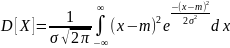 = Q₂
= Q₂
Q= D(Х) под корнем = Q (Х) , → параметр a = мат. ожид-ю , а пар. Q = среднему квадратич. О откл- ю нормально распр-ой с.в.х.
15. Генеральная совокупность и выборка.
Для исследования этого признака применяют метод сплошных наблюдений , при котором исследуют каждый объект данной соб-ти относительно изучаемого признака.
Осн-ые причины: 1) число объектов велико 2) исслед-е физич-и велико 3) исслед-е связано с большими затратами 4) исслед-е связано с ун. объектов. Если этот метод не используют, то применяют выборку.
Осн-ые способы отбора: 1) простой, случайный, повторный 2) простой, бесповторный 3) механический 4) серийный
Статистическое распределение выборки: 1) наблюдаемые значения количеств-го признака Х1, Х2…. Х2 (варианты) 2) число наблюдений N1,N2….NK(частота этих вариантов) 3) отношение частоты к выборке(относительная частота). Выборка- число объектов выборной или ген. сов-сти . 4) Варианты расположены в порядке возрастания и образуют вариационный ряд. Хи..х1 х2 х3..хн ; ни.. н1 н2 н3..нк; ви..в1 в2 в3 ..вк. Сумма всех частот = в выборке; сумма относительных частот = 1.
16. Вариационный ряд.
Вариационный ряд - последовательность всех элементов выборки, расположенных в неубывающем порядке. Одинаковые элементы повторяются.
По этому ряду уже можно сделать несколько выводов. Например, средний элемент вариационного ряда (медиана) может быть оценкой наиболее вероятного результата измерения. Первый и последний элемент вариационного ряда (т.е. минимальный и максимальный элемент выборки) показывают разброс элементов выборки. Иногда если первый или последний элемент сильно отличаются от остальных элементов выборки, то их исключают из результатов измерений, считая, что эти значения получены в результате какого-то грубого сбоя, например, техники.
17. Графическое изображение вариационных рядов, полигон и гистограмма.
Графическое изображение вариац. рядов: 1. Полигонная частота- линия отрезка, которой соединяют точки с координатами (х1,н1) (х2,н2) (хн,нк). Точки соединяются с координатами (х1,в1) ( х2,в2) (хн,вн).
2. Для непрерывного распр-я колличеств-ти признака Х, используют гистограмму частот или относит. частот. Для гистограммы относит. частот высоты прямоугол = ви : альфа.
18. Эмпирическая ф-ция распределения.
mx- число наблюдений, при которых наблюдалось значение признака, меньшее х; п- общее число наблюдений (объем выборки). Ясно, что относительная частота события Х < х равна. mx/n. Если хизменяется, то изменяется и относительная частота, т. е. относительная частота есть функция от х. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической. Эмпирической функцией распределения (функцией распределения выборки) называют функцию определяющую для каждого значения х относительную частоту события Х < х, т.е.
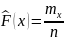 Из теоремы Бернулли
следует, что относительная частота
события Х < х, т.
е. эмпирическая функция стремится
по вероятности к вероятности F
(х) этого
события. Отсюда следует целесообразность
использования эмпирической функции
распределения выборки для приближенного
представления теоретической (интегральной)
функции распределения генеральной
совокупности.
Из теоремы Бернулли
следует, что относительная частота
события Х < х, т.
е. эмпирическая функция стремится
по вероятности к вероятности F
(х) этого
события. Отсюда следует целесообразность
использования эмпирической функции
распределения выборки для приближенного
представления теоретической (интегральной)
функции распределения генеральной
совокупности.
Эмпирическая функция обладает всеми свойствами F(x):
1) ее значения принадлежат отрезку [0, 1]; 2) неубывающая; 3) если хi -наименьшая варианта, то
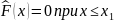 ,
если x k -
наибольшая варианта, то
,
если x k -
наибольшая варианта, то
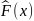 =1
при
=1
при
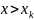
Итак, эмпирическая функция распределения выборки служит для оценки теоретической функции распределения генеральной совокупности.
19. Выборочная средняя, её свойства.
Вы́борочное (эмпири́ческое) сре́днее — это приближение теоретического среднего распределения, основанное на выборке из него.
Определение:
Пусть 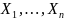 — выборка из распределения
вероятности,
определённая на некотором вероятностном
пространстве (Ω,F,P).
Тогда её выборочным средним
называется случайная
величина.
— выборка из распределения
вероятности,
определённая на некотором вероятностном
пространстве (Ω,F,P).
Тогда её выборочным средним
называется случайная
величина.
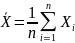
Свойства выборочного среднего :
Пусть 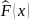 — выборочная
функция распределения данной
выборки. Тогда для любого
фиксированного ω
— выборочная
функция распределения данной
выборки. Тогда для любого
фиксированного ω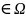 функция
функция 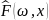 является
(неслучайной) функцией дискретного
распределения.
Тогда математическое
ожидание этого
распределения равно
является
(неслучайной) функцией дискретного
распределения.
Тогда математическое
ожидание этого
распределения равно 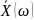
Выборочное среднее — несмещённая оценка теоретического среднего:
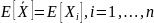
Выборочное среднее — сильно состоятельная оценка теоретического среднего:
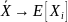 почти
наверное при
почти
наверное при 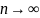 .
.
Выборочное
среднее — асимптотически
нормальная оценка.
Пусть дисперсия случайных
величин 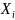 конечна
и ненулевая, то есть
конечна
и ненулевая, то есть 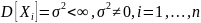
Тогда 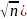 по
распределению при
,
по
распределению при
,
где 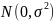 — нормальное
распределение со
средним 0 и
дисперсией
— нормальное
распределение со
средним 0 и
дисперсией 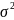 .
.
Выборочное среднее из нормальной выборки — эффективная оценка её среднего
20. Выборочная дисперсия, её свойства.
Выборочная дисперсия в математической статистике — это оценка теоретической дисперсии распределения на основе выборки. Различают выборочную дисперсию и несмещённую, или исправленную, выборочные дисперсии.
Определения
Пусть 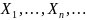 — выборка из распределения
вероятности.
Тогда
— выборка из распределения
вероятности.
Тогда
Выборочная дисперсия — это случайная величина
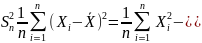 ,
,
где
символ ![]() обозначает выборочное
среднее.
обозначает выборочное
среднее.
Несмещённая (исправленная) дисперсия — это случайная величина
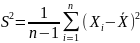 .
.
Замечание
Очевидно,
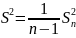 .
.
Свойства выборочных дисперсий
Выборочная
дисперсия является
теоретической дисперсией выборочного
распределения.
Более точно, пусть
— выборочная
функция распределения данной
выборки. Тогда для любого фиксированного ω
функция
является
(неслучайной) функцией дискретного
распределения.
Дисперсия этого распределения равна 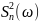 .
.
Обе
выборочные дисперсии являются состоятельными
оценками теоретической
дисперсии. Если ,
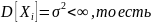
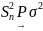 И
И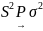 ,
,
где 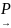 обозначает сходимость
по вероятности.
обозначает сходимость
по вероятности.
Выборочная дисперсия является смещённой оценкой теоретической дисперсии, а исправленная выборочная дисперсия несмещённой:
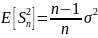 ,И
,И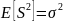
Выборочная
дисперсия нормального
распределения имеет распределение
хи-квадрат.
Пусть ![]() .
Тогда
.
Тогда
![]()
21. Статистические оценки: несмещенные, эффективные, состоятельные
Состоятельной называют такую точечную статистическую оценку, которая при n стрем к бесконечн стремится по вероятности к оцениваемому параметру. В частности, если дисперсия несмещенной оценки при n стр к беск стремится к нулю, то такая оценка оказывается и состоятельной.
Рассмотрим оценку θn числового параметра θ, определенную при n = 1, 2, … Оценка θnназывается состоятельной, если она сходится по вероятности к значению оцениваемого параметра θ при безграничном возрастании объема выборки. Выразим сказанное более подробно. Статистика θn является состоятельной оценкой параметра θ тогда и только тогда, когда для любого положительного числа ε справедливо предельное соотношение
![]()
Пример
3. Из закона
больших чисел следует, что θn = ![]() является
состоятельной оценкой θ = М(Х) (в
приведенной выше теореме Чебышёва
предполагалось существование
дисперсии D(X); однако,
как доказал А.Я. Хинчин [6], достаточно
выполнения более слабого условия –
существования математического
ожидания М(Х)).
является
состоятельной оценкой θ = М(Х) (в
приведенной выше теореме Чебышёва
предполагалось существование
дисперсии D(X); однако,
как доказал А.Я. Хинчин [6], достаточно
выполнения более слабого условия –
существования математического
ожидания М(Х)).
Пример 4. Все указанные выше оценки параметров нормального распределения являются состоятельными.
Вообще, все (за редчайшими исключениями) оценки параметров, используемые в вероятностно-статистических методах принятия решений, являются состоятельными.
Пример 5. Так, согласно теореме В.И. Гливенко, эмпирическая функция распределенияFn(x) является состоятельной оценкой функции распределения результатов наблюденийF(x)
Несмещенной называют такую точечную статистическую оценку Q*математическое ожидание которой равно оцениваемому параметру: M(Q*)=Q
Второе важное свойство оценок – несмещенность. Несмещенная оценка θn – это оценка параметра θ, математическое ожидание которой равно значению оцениваемого параметра: М(θn) = θ.
Пример
6. Из
приведенных выше результатов следует,
что ![]() и
и ![]() являются
несмещенными оценками
параметров m и σ2 нормального
распределения. Поскольку М(
являются
несмещенными оценками
параметров m и σ2 нормального
распределения. Поскольку М(![]() )
= М(m**)
= m,
то выборочная медиана
)
= М(m**)
= m,
то выборочная медиана ![]() и
полусумма крайних членов вариационного
ряда m** -
также несмещенные оценки математического
ожидания mнормального
распределения. Однако
и
полусумма крайних членов вариационного
ряда m** -
также несмещенные оценки математического
ожидания mнормального
распределения. Однако
![]()
поэтому оценки s2 и (σ2)** не являются состоятельными оценками дисперсии σ2нормального распределения.
Оценки, для которых соотношение М(θn) = θ неверно, называются смещенными. При этом разность между математическим ожиданием оценки θn и оцениваемым параметром θ, т.е. М(θn) – θ, называется смещением оценки.
Пример 7. Для оценки s2, как следует из сказанного выше, смещение равно
М(s2) - σ2 = - σ2/n.
Смещение оценки s2 стремится к 0 при n → ∞.
Оценка, для которой смещение стремится к 0, когда объем выборки стремится к бесконечности, называется асимптотически несмещенной. В примере 7 показано, что оценка s2 является асимптотически несмещенной.
Практически все оценки параметров, используемые в вероятностно-статистических методах принятия решений, являются либо несмещенными, либо асимптотически несмещенными. Для несмещенных оценок показателем точности оценки служит дисперсия – чем дисперсия меньше, тем оценка лучше. Для смещенных оценок показателем точности служит математическое ожидание квадрата оценки М(θn – θ)2. Как следует из основных свойств математического ожидания и дисперсии,
![]() (3)
(3)
т.е. математическое ожидание квадрата ошибки складывается из дисперсии оценки и квадрата ее смещения.
Для подавляющего большинства оценок параметров, используемых в вероятностно-статистических методах принятия решений, дисперсия имеет порядок 1/n, а смещение – не более чем 1/n, где n – объем выборки. Для таких оценок при больших n второе слагаемое в правой части (3) пренебрежимо мало по сравнению с первым, и для них справедливо приближенное равенство
![]() (4)
(4)
где с – число, определяемое методом вычисления оценок θn и истинным значением оцениваемого параметра θ.
Эффективной называют такую точечную статистическую оценку, которая при фиксированном n имеет наименьшую дисперсию.
С дисперсией оценки связано третье важное свойство метода оценивания –эффективность. Эффективная оценка – это несмещенная оценка, имеющая наименьшую дисперсию из всех возможных несмещенных оценок данного параметра.
Доказано
[11], что ![]() и
и ![]() являются
эффективными оценками
параметров m и σ2нормального
распределения. В то же время для
выборочной медианы
являются
эффективными оценками
параметров m и σ2нормального
распределения. В то же время для
выборочной медианы ![]() справедливо
предельное соотношение
справедливо
предельное соотношение
![]()
Другими
словами, эффективность выборочной
медианы, т.е. отношение дисперсии
эффективной оценки ![]() параметра m к
дисперсии несмещенной оценки
параметра m к
дисперсии несмещенной оценки ![]() этого
параметра при больших n близка к 0,637.
Именно из-за сравнительно низкой
эффективности выборочной медианы в
качестве оценки математического
ожидания нормального распределения
обычно используют выборочное среднее
арифметическое.
этого
параметра при больших n близка к 0,637.
Именно из-за сравнительно низкой
эффективности выборочной медианы в
качестве оценки математического
ожидания нормального распределения
обычно используют выборочное среднее
арифметическое.
Понятие эффективности вводится для несмещенных оценок, для которых М(θn) = θ для всех возможных значений параметра θ. Если не требовать несмещенности, то можно указать оценки, при некоторых θ имеющие меньшую дисперсию и средний квадрат ошибки, чем эффективные.
Пример
8. Рассмотрим
«оценку» математического ожидания m1 ≡
0. Тогда D(m1) =
0, т.е. всегда меньше дисперсии D(![]() )
эффективной оценки
)
эффективной оценки ![]() .
Математическое ожидание среднего
квадрата ошибки dn(m1)
= m2,
т.е. при
.
Математическое ожидание среднего
квадрата ошибки dn(m1)
= m2,
т.е. при ![]() имеем dn(m1)
< dn(
имеем dn(m1)
< dn(![]() ).
Ясно, однако, что статистику m1 ≡
0 бессмысленно рассматривать в качестве
оценки математического ожидания m.
).
Ясно, однако, что статистику m1 ≡
0 бессмысленно рассматривать в качестве
оценки математического ожидания m.
Пример 9. Более интересный пример рассмотрен американским математиком Дж. Ходжесом:
![]()
Ясно, что Tn – состоятельная, асимптотически несмещенная оценка математического ожидания m, при этом, как нетрудно вычислить,
![]()
Последняя
формула показывает, что при m ≠
0 оценка Tn не
хуже ![]() (при
сравнении по среднему квадрату
ошибки dn),
а при m =
0 – в четыре раза лучше.
(при
сравнении по среднему квадрату
ошибки dn),
а при m =
0 – в четыре раза лучше.
Подавляющее большинство оценок θn, используемых в вероятностно-статистических методах, являются асимптотически нормальными, т.е. для них справедливы предельные соотношения:
![]()
для любого х, где Ф(х) – функция стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1. Это означает, что для больших объемов выборок (практически - несколько десятков или сотен наблюдений) распределения оценок полностью описываются их математическими ожиданиями и дисперсиями, а качество оценок – значениями средних квадратов ошибок dn(θn).
22. Точечные и интервальные оценки.
Точечной оценкой неизвестного параметра называют число (точку на числовой оси), которое приблизительно равно оцениваемому параметру и может заменить его с достаточной степенью точности в статистических расчетах.
Для того чтобы точечные статистические оценки обеспечивали “хорошие” приближения неизвестных параметров, они должны быть несмещенными, состоятельными и эффективными.
Определение :Пусть ![]() —
случайная выборка из распределения,
зависящего от параметра
—
случайная выборка из распределения,
зависящего от параметра ![]() .
Тогда статистику
.
Тогда статистику ![]() ,
принимающую значения в
,
принимающую значения в ![]() ,
называют точечной оценкой
параметра
,
называют точечной оценкой
параметра ![]() Замечание
Замечание
Формально
статистика ![]() может
не иметь ничего общего с интересующим
нас значением параметра
может
не иметь ничего общего с интересующим
нас значением параметра ![]() .
Её полезность для получения практически
приемлемых оценок вытекает из
дополнительных свойств, которыми она
обладает или не обладает.
.
Её полезность для получения практически
приемлемых оценок вытекает из
дополнительных свойств, которыми она
обладает или не обладает.
Свойства точечных оценок
Оценка ![]() называется несмещённой,
если её математическое ожидание равно
оцениваемому параметру генеральной
совокупности:
называется несмещённой,
если её математическое ожидание равно
оцениваемому параметру генеральной
совокупности:
![]() ,
,
где ![]() обозначает математическое
ожидание в
предположении, что
обозначает математическое
ожидание в
предположении, что ![]() —
истинное значение параметра (распределения
выборки
—
истинное значение параметра (распределения
выборки ![]() ).
).
Оценка ![]() называется эффективной,
если она обладает минимальной дисперсией
среди всех возможных несмещенных
точечных оценок.
называется эффективной,
если она обладает минимальной дисперсией
среди всех возможных несмещенных
точечных оценок.
Оценка ![]() называется состоятельной,
если она по вероятности с увеличением
объема выборки n стремится к параметру
генеральной совокупности:
называется состоятельной,
если она по вероятности с увеличением
объема выборки n стремится к параметру
генеральной совокупности: ![]() ,
,
![]() по
вероятности при
по
вероятности при ![]() .
.
Оценка ![]() называется сильно
состоятельной,
если
называется сильно
состоятельной,
если ![]() ,
,
![]() почти
наверное при
почти
наверное при ![]() .
.
Надо отметить, что проверить на опыте сходимость «почти наверное» не представляется возможным, поэтому с точки зрения прикладной статистики имеет смысл говорить только о сходимости по вероятности.
Интервальной называют оценку, которая определяется двумя числами – концами отрезка.
Интервальные оценки – характеризуют не единственно возможную ситуацию, а их множественность. Этот вид экспертных оценок широко распространен. Одним из определяющих свойств интервальной оценки является то, что на множестве задано бинарное отношение МЕЖДУ.
Определение
Пусть ![]() -
неизвестный параметр генеральной
совокупности.
По сделанной выборке по определенным
правилам находятся числа
-
неизвестный параметр генеральной
совокупности.
По сделанной выборке по определенным
правилам находятся числа ![]() и
и ![]() такие
чтобы выполнялось неравенство:
такие
чтобы выполнялось неравенство:
![]()
Интервал ![]() является доверительным
интервалом для
параметра
является доверительным
интервалом для
параметра ![]() ,
а число
,
а число ![]() - доверительной
вероятностью или надежностью сделанной
оценки. Обычно надежность задается
заранее, причем выбираются числа близкие
к 1 (0.95, 0.99 или 0.999).
- доверительной
вероятностью или надежностью сделанной
оценки. Обычно надежность задается
заранее, причем выбираются числа близкие
к 1 (0.95, 0.99 или 0.999).
Пример 1. Доверительное оценивание по вариационному ряду.
Пусть
задана выборка ![]() некоторой случайной
величины
некоторой случайной
величины ![]() Построим вариационный
ряд выборки
Построим вариационный
ряд выборки ![]()
![]()
Очевидно,
что вероятность попасть в любой из ![]() -
го интервалов значений случайной
величины X одинакова
и равна
-
го интервалов значений случайной
величины X одинакова
и равна ![]() Тогда
вероятность того, что случайная
величина X приняла
значение из интервала
Тогда
вероятность того, что случайная
величина X приняла
значение из интервала ![]() где
где ![]() будет
равна:
будет
равна:
![]()
Вопрос: чему
должен быть равен размер выборки n чтобы
вероятность попасть в интервал ![]() составила
95%.
составила
95%.
Подставляя значение для доверительной вероятности в формулу выше, получим:
![]()
откуда ![]()
Таким
образом, при достаточном для заданной
доверительной вероятности числе
измерений случайной величины ![]() по
набору ее порядковых
статистикможет
быть оценен диапазон принимаемых ею
значений.
по
набору ее порядковых
статистикможет
быть оценен диапазон принимаемых ею
значений.
Пример 2. Доверительный интервал для медианы.
Пусть
задана выборка ![]() некоторой случайной
величины X
некоторой случайной
величины X
При ![]() доверительный
интервал для медианы
доверительный
интервал для медианы ![]() определяется порядковыми
статистиками
определяется порядковыми
статистиками
![]()
где
![]() при
при ![]()
![]() при
при ![]()
![]() при
при ![]()
Для
значений ![]() номера
порядковых статистик, заключающих в
себе медиану, при
номера
порядковых статистик, заключающих в
себе медиану, при ![]() и
и ![]() приведены
в таблице 1, взятой из [3].
приведены
в таблице 1, взятой из [3].
Пример 3. Доверительный интервал для математического ожидания.
Пусть
задана выборка ![]() некоторой случайной
величины X,
арактеристики которой (дисперсия D и
математическое ожидание M) неизвестны.
Эти параметры оценим так:
некоторой случайной
величины X,
арактеристики которой (дисперсия D и
математическое ожидание M) неизвестны.
Эти параметры оценим так:
![]()
![]() -
несмещенная оценка дисперсии.
-
несмещенная оценка дисперсии.
Величину ![]() называют
оценкой среднего квадратического
отклонения. Воспользуемся тем, что
величина
называют
оценкой среднего квадратического
отклонения. Воспользуемся тем, что
величина ![]() представляет
собой сумму
представляет
собой сумму ![]() независимых
случайных величин, и, согласно центральной
предельной теореме, при достаточно
большом
независимых
случайных величин, и, согласно центральной
предельной теореме, при достаточно
большом ![]() ее
закон близок к нормальному. Поэтому
будем считать, что величина
ее
закон близок к нормальному. Поэтому
будем считать, что величина ![]() распределена
по нормальному закону. Характеристики
этого закона - математическое ожидание
и дисперсия - равны соответственно M
(настоящее МО случайной величины
распределена
по нормальному закону. Характеристики
этого закона - математическое ожидание
и дисперсия - равны соответственно M
(настоящее МО случайной величины ![]() )
и
)
и ![]() .
.
Найдем
такую величину ![]() ,
для которой
,
для которой ![]() .
Перепишем это в эквивалентном виде
.
Перепишем это в эквивалентном виде ![]() и
скажем, что случайная величина перед
знаком неравенства есть модуль от
стандартной нормальной. Получаем,
что
и
скажем, что случайная величина перед
знаком неравенства есть модуль от
стандартной нормальной. Получаем,
что ![]() ,
и
,
и ![]() .
В случае неизвестной дисперсии ее можно
заменить на оценку
.
В случае неизвестной дисперсии ее можно
заменить на оценку ![]() .
.
Например,
выбирая ![]() ,
получаем коэффициент
,
получаем коэффициент ![]()
Окончательно:
с вероятностью ![]() можно
сказать, что
можно
сказать, что ![]()
23. Точность и надежность оценки, доверительный интервал.
Точность
оценка характеризуется положительным
числом
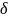 ,
которое характеризует величину
расхождения между оценками выборки и
генеральной совокупности:
,
которое характеризует величину
расхождения между оценками выборки и
генеральной совокупности:
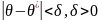
Надежностью
(доверительной вероятностью) оценки
0 по 0* называют вероятность у, с которой
осуществляется неравенство
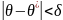
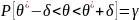
В качестве параметров надежности наиболее часто используют величины, близкие к единице: 0,95; 0,99 и 0,999.
Доверительным
называют интервал
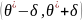 ,
который покрывает
,
который покрывает
неизвестный параметр с заданной надежностью у.
24. Интегральная оценка неизвестного математического ожидания нормально распределенной генеральной совокупности.
Существуют два основных метода построения доверительных интервалов: байесовский метод и метод доверительных интервалов, предложенный Нейманом. Применяя метод построения доверительных интервалов, основанный на формуле Байеса, исходят из предположения, что оцениваемый параметр сам случаен. Предполагается также, что известно априорное распределение параметра. Этот метод часто неприменим, так как оцениваемая величина на практике является просто неизвестной постоянной, а не случайной величиной. Кроме того, ее распределение бывает также неизвестным. От этих недостатков свободен метод доверительных интервалов. Рассмотрим примеры построения доверительных интервалов в ряде случаев.
2.1. Доверительный интервал для математического ожидания при известной дисперсии
Пусть
по выборке достаточно большого объема, ![]() ,
и при заданной доверительной
вероятности
,
и при заданной доверительной
вероятности ![]() необходимо
определить доверительный интервал для
математического ожидания
необходимо
определить доверительный интервал для
математического ожидания ![]() ,
в качестве оценки которого используется
среднее арифметическое (среднее
выборочное)
,
в качестве оценки которого используется
среднее арифметическое (среднее
выборочное) ![]() .
.
Закон
распределения оценки математического
ожидания близок к нормальному
(распределение суммы независимых
случайных величин с конечной дисперсией
асимптотически нормально). Если
потребовать абсолютную надежность
оценки математического ожидания, то
границы доверительного интервала будут
бесконечными ![]() .
Выбор любых более узких границ связан
с риском ошибки, вероятность которой
определяется уровнем значимости
.
Выбор любых более узких границ связан
с риском ошибки, вероятность которой
определяется уровнем значимости ![]() ,
где значения
,
где значения ![]() выбираются
достаточно близкими к единице, например,
0,9, 0,95, 0,98, 0,99. Величину
выбираются
достаточно близкими к единице, например,
0,9, 0,95, 0,98, 0,99. Величину ![]() называют
надежностью или доверительной
вероятностью. Интерес представляет
максимальная точность оценки, т.е.
наименьшее значение интервала. Для
симметричных функций минимальный
интервал тоже будет симметричным
относительно оценки
называют
надежностью или доверительной
вероятностью. Интерес представляет
максимальная точность оценки, т.е.
наименьшее значение интервала. Для
симметричных функций минимальный
интервал тоже будет симметричным
относительно оценки ![]() .
В этом случае выражение для доверительной
вероятности имеет вид
.
В этом случае выражение для доверительной
вероятности имеет вид ![]() ,
где
,
где ![]() –
абсолютная погрешность оценивания.
–
абсолютная погрешность оценивания.
Нормальный
закон ![]() полностью
определяется двумя параметрами –
математическим ожиданием
полностью
определяется двумя параметрами –
математическим ожиданием ![]() и
дисперсией
и
дисперсией ![]() .
Величина
.
Величина ![]() является
несмещенной, состоятельной и эффективной
оценкой математического ожидания,
поэтому ее значение принимаем за
значение математического ожидания в
качестве точечной оценки. Будем полагать,
что дисперсия
является
несмещенной, состоятельной и эффективной
оценкой математического ожидания,
поэтому ее значение принимаем за
значение математического ожидания в
качестве точечной оценки. Будем полагать,
что дисперсия ![]() известна,
тогда выборочное среднее
известна,
тогда выборочное среднее ![]() –
нормально распределенная случайная
величина с параметрами
–
нормально распределенная случайная
величина с параметрами ![]() .
Для такой случайной величины вероятность
попадания на симметричный относительно
математического ожидания интервал
выражается через функцию Лапласа
.
Для такой случайной величины вероятность
попадания на симметричный относительно
математического ожидания интервал
выражается через функцию Лапласа ![]() ,
где
,
где ![]() .
При заданной надежности
.
При заданной надежности ![]() ,
уравнение
,
уравнение ![]() можно
решить приближенно с помощью таблицы
значений функции Лапласа (см. приложение,
таблица 1). Если точного значения
можно
решить приближенно с помощью таблицы
значений функции Лапласа (см. приложение,
таблица 1). Если точного значения ![]() в
списке значений нет, то надо найти два
ближайших к нему значения, одно большее,
а другое меньшее, чем
в
списке значений нет, то надо найти два
ближайших к нему значения, одно большее,
а другое меньшее, чем ![]() ,
и найти их среднее арифметическое.
Известное значение параметра t позволяет
записать абсолютную погрешность
,
и найти их среднее арифметическое.
Известное значение параметра t позволяет
записать абсолютную погрешность ![]() .
Теперь можно указать симметричный
интервал
.
Теперь можно указать симметричный
интервал ![]() .
Полученное соотношение означает, что
доверительный интервал
.
Полученное соотношение означает, что
доверительный интервал ![]() покрывает
неизвестный параметр a (математическое
ожидание) с вероятностью (надежностью)
покрывает
неизвестный параметр a (математическое
ожидание) с вероятностью (надежностью) ![]() ,
а точность оценки
,
а точность оценки ![]() .
.
При
фиксированном объеме выборки из
оценки ![]() следует,
что чем больше доверительная вероятность
следует,
что чем больше доверительная вероятность ![]() ,
тем шире границы доверительного
интервала (тем больше ошибка в оценке
математического ожидания). Чтобы снизить
ошибку в оценке значения, можно увеличить
объем выборки. При этом, чтобы снизить
относительную погрешность на порядок,
необходимо увеличить объем выборки на
два порядка.
,
тем шире границы доверительного
интервала (тем больше ошибка в оценке
математического ожидания). Чтобы снизить
ошибку в оценке значения, можно увеличить
объем выборки. При этом, чтобы снизить
относительную погрешность на порядок,
необходимо увеличить объем выборки на
два порядка.
25. Метод моментов для точечной оценки параметров распределения.
Метод моментов оценивания параметров распределения генеральной совокупности состоит в том, на основании выборки х1, х2, ..., хn вычисляются выборочные моменты (начальные или центральные). Полученные значения приравниваются соответствующим теоретическим моментам. Количество моментов должно ровняться числу оцениваемых параметров. Затем решают полученную систему уравнений относительно этих параметров.
Рассмотрим случай, когда метод моментов используется для нахождения оценки одного параметра. Положим, что плотность распределения f(x;a) случайной величины Х зависит только от одного параметраа, и необходимо найти оценку параметра а. Для нахождения оценки одного параметра достаточно иметь одно уравнение относительно этого параметра, используя, например, на основании выборки х1, х2, ... , ,хnпервый начальный момент
![]() .
.
Приравняем его значение первому теоретическому моменту
![]() =
=![]() ,
,
рассматривая
правую часть равенства как функцию
от а. Решая
это уравнение относительно неизвестного
параметра а,
получаем точечную оценку ![]() ,
которая теперь является функцией от
вариант выборки, то есть
,
которая теперь является функцией от
вариант выборки, то есть
![]() .
.
Пример. Пусть Х –
непрерывная случайная величина подчинена
показательному (экспоненциальному)
закону, плотность распределения которого
зависит от одного неизвестного
параметра ![]() :
:
![]() , х
, х![]() 0.
0.
Используя
полученные экспериментальные
данные х1, х2,
... , хn,
получить оценку параметра ![]() .
.
Решение. На основании выборки х1, х2, ... , хn находим первый выборочный момент и приравниваем его первому моменту случайной величины Х, подчиненной показательному закону:
![]() =
= ![]() =
=![]() .
.
Отсюда
получаем оценку параметра ![]() :
:
![]() .
.
Если
функция плотности распределения
случайной величины Х зависит
от двух параметров, например ![]() ,
то для отыскания оценок параметров
,
то для отыскания оценок параметров ![]() необходимо
иметь уже два уравнения относительно
этих параметров. Для этого можно
воспользоваться, например, первым
начальным моментом (математическим
ожиданием) и вторым центральным
(дисперсией).
необходимо
иметь уже два уравнения относительно
этих параметров. Для этого можно
воспользоваться, например, первым
начальным моментом (математическим
ожиданием) и вторым центральным
(дисперсией).
Примеры.
1.
По выборке х1, х2,
... , хп методом
моментов найти точечные оценки
параметров mx и ![]() нормального
распределения:
нормального
распределения:
![]() .
.
Решение.
Так как первый начальный момент
нормального распределения равен
параметру тх.,
а второй центральный момент равен
параметру ![]() ,
,
то
![]()
![]() ,
, ![]() .
.
2. По выборке х1, х2, ... , хп методом моментов найти точечные оценки параметров а1, а2 равномерного распределения на интервале [а1, а2]:
![]()
Решение. Используя выборку х1, х2, ... , хп, находим выборочные первый начальный и второй центральные моменты:
![]() ,
,![]() ,(
,(![]() )
(8.2)
)
(8.2)
Для равномерного распределения имеем теоретические моменты
![]() ,
, ![]() .
.
Прировняем теоретические моменты выборочным и получаем систему двух уравнений с двумя неизвестными для нахождения оценок параметров а1, а2:
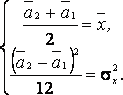
Решая эту систему, получаем в окончательном виде
![]() ,
, ![]() ,
,
где
величины ![]() ,
, ![]() определены
соотношениями (2).
определены
соотношениями (2).
26. Функциональная, статистическая и корреляционная зависимости.
Пусть у нас имеются n серии значений двух параметров X и Y: (x1;y1),(x2;y2),...,(xn;yn). Подразумевается, что у одного и того же объекта измерены два параметра. Нам надо выяснить есть ли значимая связь между этими параметрами.
Как известно, случайные величины X и Y могут быть либо зависимыми, либо независимыми. Существуют следующие формы зависимости – функциональная и статистическая. В математике функциональной зависимостью переменной Y от переменной Х называют зависимость вида y=f(x), где каждому допустимому значению X ставится в соответствие по определенному правилу единственно возможное значение Y.
Однако, если X и Y случайные величины, то между ними может существовать зависимость иного рода, называемая статистической. Дело в том, что на формирование значений случайных величин X и Y оказывают влияние различные факторы. Под воздействием этих факторов и формируются конкретные значения X и Y. Допустим, что на Х и У влияют одни те же факторы, например Z1, Z2, Z3, тогда X и Y находятся в полном соответствии друг с другом и связаны функционально. Предположим теперь, что на X воздействуют факторы Z1, Z2, Z3, а на только Y и Z1, Z2. Обе величины и X и Y являются случайными, но так как имеются общие факторы Z1 и Z2, оказывающие влияние и на X и на Y, то значения X и Y обязательно будут взаимосвязаны. И связь это уже не будет функциональной: фактор Z3, влияющий лишь на одну из случайных величин, разрушает прямую (функциональную) зависимость между значениями X и Y, принимаемыми в одном и том же испытании. Связь носит вероятностный случайный характер, в численном выражении меняясь, от испытания к испытанию, но эта связь определенно присутствует и называется статистической. При этом каждому значению X может соответствовать не одно значение Y, как при функциональной зависимости, а целое множество значений.
ОПРЕДЕЛЕНИЕ. Зависимость случайных величин называют статистической, если изменения одной из них приводит к изменению закона распределения другой.
ОПРЕДЕЛЕНИЕ. Если изменение одной из случайных величин влечет изменение среднего другой случайной величины, то статистическую зависимость называют корреляционной. Сами случайные величины, связанные коррреляционной зависимостью, оказываются коррелированными.
Примерами
коррреляционной зависимости являются:
зависимость массы от роста:
-
каждому значению роста (X) соответствует
множество значений массы (Y), причем,
несмотря на общую тенденцию, справедливую
для средних, большему значению роста
соответствует и большее значение массы
– в отдельных наблюдениях субъект с
большим ростом может иметь и меньшую
массу.
- зависимость заболеваемости
от воздействия внешних факторов,
например, запыленности, уровня радиации,
солнечной активности и т.д.
-
количество (X) вводимого объекту препарата
и его концентрация в крови (Y).
-
между показателями уровня жизни
населения и процентом смертности;
-
между количеством пропущенных студентами
лекций и оценкой на экзамене.
Именно
корреляционные зависимости наиболее
часто встречаются в природе в силу
взаимовлияния и тесного переплетения
огромного множества самых различных
факторов, определяющих значения
изучаемых показателей.
Корреляционную зависимость Y от X можно описать с помощью уравнения вида:
yx=f(x) (1)
где yx - условное среднее величины Y, соответствующее значению x величины X, а f(x) некоторая функция. Уравнение (1) называется выборочным уравнением регрессии Y на X. Функцию f(x) называют выборочной регрессией Y на X, а ее график – выборочной линией регрессии Y на X.
Совершенно аналогично выборочным уравнением регрессии X на Y является уравнение: xy=φ(y)
В зависимости от вида уравнения регрессии и формы соответствующей линии регрессии определяют форму корреляционнной зависимости между рассматриваемыми величинами – линейной, квадратической, показательной, экспоненциальной.
Важнейшим является вопрос выбора вида функции регрессии f(x) [или φ(y)], например линейная или нелинейная (показательная, логарифимическая и т.д.)
На практике вид функции регрессии можно определить, построив на координатной плоскости множество точек, соответствующих всем имеющимся парам наблюдений (x;y).
![]()
Рис. 1. Линейная регрессия значима. Модель Y=a+bX.
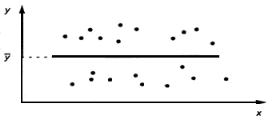
Рис.
2. Линейная регрессия незначима. Модель
Y=![]()
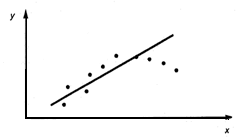
Рис. 3. Линейная регрессия значима. Нелинейная модель (y=ax2+bx+c)
Например,
на рис.1. видна тенденция роста значений
Y с ростом X, при этом средние значения
Y располагается визуально на прямой.
Имеет смысл использовать линейную
модель (вид зависимости Y от X принято
называть моделью) зависимости Y от X. На
рис.2. средние значения Y не зависят от
x, следовательно линейная регрессия
незначима (функция регрессии постоянна
и равна ![]() ).
На рис. 3. прослеживается тенденция
нелинейности модели.
).
На рис. 3. прослеживается тенденция
нелинейности модели.
27. Условные средние выборочные уравнения регрессии.
Во многих задачах требуется установить и оценить зависимость изучаемой слу-
чайной величины Y от одной или нескольких других величин.
Рассмотрим сначала зависимость Y от одной случайной (или неслучайной)
величины X. Две случайные величины могут быть связаны либо функциональ-
ной зависимостью, либо зависимостью другого рода, называемой статистиче-
ской, либо быть независимыми.
Строгая функциональная зависимость реализуется редко, так как обе вели-
чины или одна из них подвержены еще действию случайных факторов, причем
среди них могут быть и общие для обеих величин (под общими здесь подразу-
меваются такие факторы, которые воздействуют и на Y и на X). В этом случае
возникает статистическая зависимость.
Например, если Y зависит от случайных факторов Z1, Z2, V1, V2, a X
зависит от случайных факторов Z1, Z2, U1, U2, то между Y и X имеется ста-
тистическая зависимость, так как среди случайных факторов есть общие: Z1 и
Z2.
Определение 71. Статистической называют зависимость, при которой из-
менение одной из величин влечет изменение распределения другой.
В частности, статистическая зависимость проявляется в том, что при из-
менении одной из величин изменяется среднее значение другой; в этом случае
статистическую зависимость называют корреляционной.
Рассмотрим пример случайной величины Y , которая не связана с величи-
ной X функционально, а связана корреляционно. Пусть Y - урожай зерна, X
- количество удобрений. С одинаковых по площади участков земли при рав-
ных количествах внесенных удобрений снимают различный урожай, т. е. Y не
является функцией от X.
Это объясняется влиянием случайных факторов (осадки, температура возду-
ха и др.). Вместе с тем, как показывает опыт, средний урожай является функци-
ей от количества удобрений, т. е. Y связан с X корреляционной зависимостью.
15.1.2. Условные средние
В качестве оценок условных математических ожиданий принимают условные
средние, которые находят по данным наблюдений (по выборке).
Определение 72. Условным средним yx называется среднее арифметическое
наблюдавшихся значений Y, соответствующих X = x.
Пример.
Если при x1 = 2 величина Y приняла значения y1 = 5, y2 = 6, y3 = 10, то
условное среднее yx1 =5 + 6 + 10/3= 7
Аналогично определяется условное среднее xy.15.1. Теория корреляций 119
Определение 73. Условным средним xy называется среднее арифметическое
наблюдавшихся значений X, соответствующих Y = y.
15.1.3. Выборочные уравнения регрессии
При изучении условных вероятностей мы вводили понятие условного математи-
ческого ожидания
Условным математическим ожиданием дискретной случайной величины
Y при X = x (x - определенное возможное значение X) называется произведе-
ние возможных значений Y на их условные вероятности:
M[Y|X = x] = Xm
j=1
yjp(yj|x).
Для непрерывных величин
M[Y |X = x] = Z ∞
−∞
yψ(y|x)dy,
где ψ(y|x) - условная плотность случайной величины Y при X = x.
Условное математическое ожидание M[Y|X = x] есть функция от x:
M[Y|X = x] = M[Y|x] = f(x),
которая называется функцией регрессии Y на X.
Аналогично определяются условное математическое ожидание случайной ве-
личины X и функция регрессии X на Y :
M[X|Y = y] = M[X|y] = ϕ(y).
Условное математическое ожидание M[Y |x] является функцией от x, следова-
тельно, его оценка, т. е. условное среднее yx
, также функция от x; обозначив
эту функцию через f
∗
(x), получим уравнение
yx = f
∗
(x).
Определение 74.
Выборочным уравнением регрессии Y на X называется уравнение
yx = f
∗
(x).
Выборочной регрессией Y на X называется функция f
∗
(x).
Выборочной линией регрессии Y на X называется график функции f
∗
(x).
Аналогично уравнение
xy = ϕ
∗
(y).
называется выборочным уравнением регрессии X на Y; функция ϕ
∗
(y) называ-
ется выборочной регрессией X на Y , а ее график - выборочной линией регрессии
X на Y.
28. Построение линейных моделей:
1)по не сгруппированным выборочным данным.
2) по сгруппированным выборочным даннымю
Для того, чтобы найти объясненную часть, т. е. величину математического ожидания Мх(У), требуется нахождение условных распределений случайной величины Y. На практике это почти никогда не возможно.
В большинстве случаях при решении задач по эконометрике применяется стандартная процедура сглаживания экспериментальных данных. Эта процедура состоит из двух этапов:
1) определяется параметрическое семейство, к которому принадлежит искомая функция Мх(У) (определяемая как функция от значений объясняющих переменных X). Это может быть линейная функция, показательная функция и т.д.;
2) находятся оценки параметров этой функции с помощью одного из методов мат. статистики.
Формально никаких способов выбора параметрического семейства нет. Однако в большинстве случаев модели в задачах предмета эконометрика выбираются линейными.
Кроме очевидного преимущества линейной модели — ее относительной простоты, — для этого выбора имеются, как минимум, две существенные причины.
Первая причина: если случайная величина (X, У) имеет совместное нормальное распределение, то уравнения регрессии линейные.
В других случаях сами величины Y или X могут не иметь нормального распределения, но некоторые функции от них распределены нормально. Например, известно, что логарифм доходов на душу населения — нормально распределенная случайная величина. В большинстве случаев гипотеза о нормальном распределении принимается, когда нет явного ей противоречия, и, как показывает практика, подобная предпосылка бывает вполне разумной.
Вторая причина, по которой линейная регрессионная модель оказывается предпочтительнее других, является меньший риск значительной ошибки прогноза.
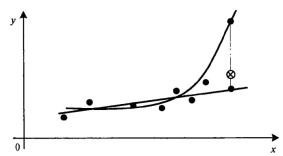
Рисунок показывает два выбора функции регрессии — линейной и квадратичной. Как видно, имеющееся множество экспериментальных данных (точек) парабола сглаживает, пожалуй, даже лучше, чем прямая. Однако парабола быстро удаляется от корреляционного поля и для добавленного наблюдения теоретическое значение может очень значительно отличаться от эмпирического.
Можно определить точный математический смысл этому утверждению: ожидаемое значение ошибки прогноза, т.е. математическое ожидание квадрата отклонения наблюдаемых значений от сглаженных (или теоретических) оказывается меньше в том случае, если выбрано линейное уравнение регрессии.
29. Выборочный коэффициент корреляции,методика его вычисления
Понятие корреляции является одним из основных понятий теории вероятностей и математической статистики, оно было введено Гальтоном и Пирсоном.
Закон природы или общественного развития может быть представлен описанием совокупности взаимосвязей. Если эти зависимости стохастичны, а анализ осуществляется по выборке из генеральной совокупности, то данная область исследования относится к задачам стохастического исследования зависимостей, которые включают в себя корреляционный, регрессионный, дисперсионный и ковариационный анализы. В данном разделе рассмотрена теснота статистической связи между анализируемыми переменными, т.е. задачи корреляционного анализа.
В качестве измерителей степени тесноты парных связей между количественными переменными используются коэффициент корреляции (или то же самое "коэффициент корреляции Пирсона") и корреляционное отношение.
Пусть
при проведении некоторого опыта
наблюдаются две случайные величины X и Y,
причем одно и то же
значение x встречается ![]() раз,
раз, ![]() раз,
одна и та же пара чисел (x,y) наблюдается
раз,
одна и та же пара чисел (x,y) наблюдается ![]() раз.
Все данные записываются в виде таблицы,
которую называют корреляционной.
раз.
Все данные записываются в виде таблицы,
которую называют корреляционной.
Выборочная ковариация k(X,Y) величин X и Y определяется формулой
![]()
где ![]() ,
а
,
а ![]() ,
, ![]() -
выборочные средние величин X и Y.
При небольшом количестве экспериментальных
данных k(X,Y) удобно
находить как полный вес ковариационного
графа:
-
выборочные средние величин X и Y.
При небольшом количестве экспериментальных
данных k(X,Y) удобно
находить как полный вес ковариационного
графа:
Выборочный коэффициент корреляции находится по формуле
![]()
где ![]() -
выборочные средние квадратические
отклонения величин X и Y.
-
выборочные средние квадратические
отклонения величин X и Y.
Выборочный
коэффициент корреляции ![]() показывает
тесноту линейной связи между X и Y:
чем ближе
показывает
тесноту линейной связи между X и Y:
чем ближе ![]() к
единице, тем сильнее линейная связь
между X и Y.
к
единице, тем сильнее линейная связь
между X и Y.
30. Статистические гипотезы, ошибки 1-го и 2-го рода, уровень значимости.
Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость ее проверки. Поскольку проверку производят статистическими методами, ее называют статистической. В итоге статистической проверки гипотезы в двух случаях может быть принято неправильное решение, т. е. могут быть допущены ошибки двух родов.
Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза.
Ошибка второго рода состоит в том, что будет принята неправильная гипотеза.
Вероятность
совершить ошибку первого рода принято
обозначать через ![]() ;
ее называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0.05 или 0.01. Если, например, принят
уровень значимости, равный 0.05, то это
означает, что в пяти случаях из ста мы
рискуем допустить ошибку первого рода
(отвергнуть правильную гипотезу).
;
ее называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0.05 или 0.01. Если, например, принят
уровень значимости, равный 0.05, то это
означает, что в пяти случаях из ста мы
рискуем допустить ошибку первого рода
(отвергнуть правильную гипотезу).
Пусть
дана выборка ![]() из
неизвестного совместного распределения
из
неизвестного совместного распределения ![]() ,
и поставлена бинарная задача проверки
статистических гипотез:
,
и поставлена бинарная задача проверки
статистических гипотез:
![]()
где ![]() — нулевая
гипотеза,
а
— нулевая
гипотеза,
а ![]() — альтернативная
гипотеза.
Предположим, что задан статистический
критерий
— альтернативная
гипотеза.
Предположим, что задан статистический
критерий
![]() ,
,
31. Статистический критерий проверки нулевой гипотезы.
Для проверки нулевой гипотезы используют специально подобранную случайную величину, точное или приближенное распределение которой известно. Эту величину обозначают через U или Z, если она распределена нормально, F или v2 – по закону Фишера-Снедекора, T – по закону Стьюдента, c² – по закону «хи квадрат» и т. д. Все эти случайные величины обозначим через К.
Статистическим критерием (или просто критерием) называют случайную величину К, которая служит для проверки нулевой гипотезы.
Для проверки гипотезы по данным выборок вычисляют частные значения входящих в критерий величин, и таким образом получают частное (наблюдаемое) значение критерия.
Наблюдаемым значением Кнабл назначают значение критерия, вычисленное по выборкам.
32. Критическая область. Область принятия гипотезы, критические точки.
После выбора определенного критерия множество всех его возможных значений разбивают на два непересекающихся подмножества, одно из которых содержит значения критерия, при которых нулевая гипотеза отвергается, а другое – при которых она принимается.
Критической областью называют совокупность значений критерия, при которых нулевую гипотезу отвергают.
Областью принятия гипотезы (областью допустимых значений) называют совокупность значений критерия, при которых гипотезу принимают.
Основной принцип проверки статистических гипотез можно сформулировать так: если наблюдаемое значение критерия принадлежит критической области – гипотезу отвергают, если области принятия гипотезы – гипотезу принимают.
Так как критерий K – одномерная случайная величина, то все ее возможные значения принадлежат некоторому интервалу и, соответственно, должны существовать точки, разделяющие критическую область и область принятия гипотезы. Такие точки называются критическими точками.
Различают одностороннюю (правостороннюю и левостороннюю) и двустороннюю критические области.
Правосторонней
называют критическую область, определяемую
неравенством ![]() ,
где
,
где ![]() –
положительное число.
–
положительное число.
Левосторонней
называют критическую область, определяемую
неравенством ![]() ,
где
,
где ![]() –
отрицательное число.
–
отрицательное число.
Двусторонней
называют критическую область, определяемую
неравенствами ![]() ,
где
,
где ![]() .
В частности, если критические точки
симметричны относительно нуля,
двусторонняя критическая область
определяется неравенствами
.
В частности, если критические точки
симметричны относительно нуля,
двусторонняя критическая область
определяется неравенствами ![]() или
равносильным неравенством
или
равносильным неравенством ![]() .
Различия между вариантами критических
областей иллюстрирует следующий
рисунок.
.
Различия между вариантами критических
областей иллюстрирует следующий
рисунок.
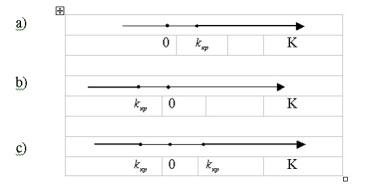
Рис. 1. Различные варианты критических областей a) правосторонняя, b) левосторонняя, с) двусторонняя
Резюмируя, сформулируем этапы проверки статистической гипотезы:
Формулируется
нулевая гипотеза ![]() ;
Определяется критерий K, по значениям
которого можно будет принять или
отвергнуть
;
Определяется критерий K, по значениям
которого можно будет принять или
отвергнуть ![]() и
выбирается уровень значимости
и
выбирается уровень значимости ![]() ;
По уровню значимости определяется
критическая область; По выборке
вычисляется значение критерия K,
определяется, принадлежит ли оно
критической области и на основании
этого принимается
;
По уровню значимости определяется
критическая область; По выборке
вычисляется значение критерия K,
определяется, принадлежит ли оно
критической области и на основании
этого принимается ![]() или
или ![]() .
.
33. Сравнение 2-х дисперсий нормально распределенных генеральных совокупностей.
Пусть имеются две выборки объемов n1
и n2, извлеченные из нормально
распределенных генеральных совокупностей Х и Y. Требуется по
исправленным выборочным дисперсиям Sх2 и Sу2
проверить нулевую
гипотезу о равенстве генеральных дисперсий рассматриваемых генеральных
совокупностей:Ho: D (X) = D (Y).
Критерием служит случайная величина = − 2
2
м
б
s
s
F отношение большей
исправленной дисперсии к меньшей, которая при условии справедливости
нулевой гипотезы имеет распределение Фишера - Снедекора со степенями
свободы k
1
= n1 – 1 и k
2
= n2 – 1. Критическая область зависит от вида
конкурирующей гипотезы:
1) если H1: D (X) > D (Y), то критическая область правосторонняя:
( ( , , )) . p F > Fкр α k
1
k
2
=α
Критическая точка ( , , )
1 2
F k k
кр α находится по таблице критических точек
распределения Фишера - Снедекора. Если = < кр −
м
б
набл F
s
s
F 2
2
нулевая гипотеза
принимается, в противном случае – отвергается.
2) При конкурирующей гипотезе H1: D (X) ≠ D (Y) критическая область
двусторонняя: .
2
, ( )
2
( )
1 2
α α
p F < F = p F > F =
При этом достаточно найти
, , ).
2
(
2 1 2
F F k k
кр
α
=
Тогда, если = < кр −
м
б
набл F
s
s
F 2
2
нет оснований отвергнуть
нулевую гипотезу, если Fнабл > Fкр − нулевую гипотезу отвергают.