Файл: Лабораторная работа 1 по курсу Инструменты бизнесаналитики исполнитель Богомолов Д. Н. Фио.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.11.2023
Просмотров: 10
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
МОСКОВСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
им. Н.Э. Баумана
Кафедра «Систем обработки информации и управления»
ОТЧЕТ
Лабораторная работа №_1_
по курсу «Инструменты бизнес-аналитики»
ИСПОЛНИТЕЛЬ: ___Богомолов Д.Н.___
ФИО
группа ИУ5-43М __________________
подпись
"__"_________2021_ г.
ПРЕПОДАВАТЕЛЬ: __________________
ФИО
_____Сухобоков А.В.___
подпись
"__"_________2021_ г.
Москва - 2021
Лабораторная работа №1
Цель. Необходимо построить модель для удержания маятника в равновесии (cartpole), используя обучение с подкреплением (Reinforcement Learning).
Cartpole - известный также как Перевернутый маятник с центром тяжести над своей точкой поворота. Он нестабилен, но его можно контролировать, перемещая точку поворота под центром массы. Цель состоит в том, чтобы сохранить равновесие карпола, прикладывая соответствующие усилия к точке поворота.
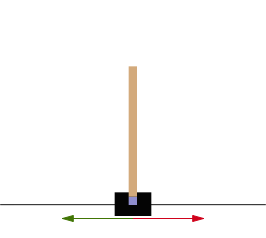
Рисунок 1. – Схематическое изображение тележки
Фиолетовый квадрат указывает на опорную точку.
Красные и зеленые стрелки показывают возможные горизонтальные силы, которые могут быть применены к точке поворота.
Полюс прикреплен неиспользуемым соединением к тележке, которая движется по дорожке без трения. Система управляется приложением силы +1 или -1 к тележке. Маятник начинается вертикально, и цель состоит в том, чтобы предотвратить его падение. Награда +1 предоставляется за каждый временной шаг, когда шест остается в вертикальном положении. Эпизод заканчивается, когда полюс отклоняется от вертикали более чем на 15 градусов или тележка перемещается более чем на 2,4 единицы от центра.
Импорт библиотек
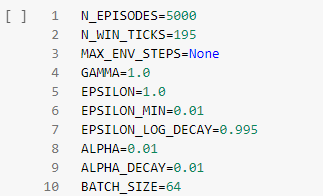
Настройка гиперпараметров
Архитектура нейронной сети

Работа с моделью
class DQNCartPoleSolver():
def __init__(self, n_episodes=1000, n_win_ticks=195, max_env_steps=None, gamma=1.0, epsilon=1.0, epsilon_min=0.01,
epsilon_log_decay=0.995, alpha=0.01, alpha_decay=0.01, batch_size=64, monitor=False, quiet=False):
self.memory = deque(maxlen=100000)
self.env = gym.make('CartPole-v0')
if monitor: self.env = gym.wrappers.Monitor(self.env,
'../data/cartpole-1', force=True)
self.gamma = gamma
self.epsilon = epsilon
self.epsilon_min = epsilon_min
self.epsilon_decay = epsilon_log_decay
self.alpha = alpha
self.alpha_decay = alpha_decay
self.n_episodes = n_episodes
self.n_win_ticks = n_win_ticks
self.batch_size = batch_size
self.quiet = quiet
self.model = get_model(self.alpha, self.alpha_decay)
if max_env_steps is not None: self.env._max_episode_steps = max_env_steps
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def choose_action(self, state, epsilon):
return self.env.action_space.sample() if (np.random.random() <= epsilon)
else np.argmax(self.model.predict(state))
def get_epsilon(self, t):
return max(self.epsilon_min, min(self.epsilon, 1.0 –
math.log10((t + 1) * self.epsilon_decay)))
def preprocess_state(self, state):
return np.reshape(state, [1, 4])
def replay(self, batch_size):
x_batch, y_batch = [], []
minibatch = random.sample(self.memory, min(len(self.memory), batch_size))
for state, action, reward, next_state, done in minibatch:
y_target = self.model.predict(state)
y_target[0][action] = reward if done else reward + self.gamma *
np.max(self.model.predict(next_state)[0])
x_batch.append(state[0])
y_batch.append(y_target[0])
self.model.fit(np.array(x_batch), np.array(y_batch), batch_size=len(x_batch),
verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def run(self):
scores = deque(maxlen=100)
for e in range(self.n_episodes):
state = self.preprocess_state(self.env.reset())
done = False
i = 0
while not done:
q = self.get_epsilon(e)
self.debug.append(q)
action = self.choose_action(state, q)
next_state, reward, done, _ = self.env.step(action)
next_state = self.preprocess_state(next_state)
self.remember(state, action, reward, next_state, done)
state = next_state
i += 1
scores.append(i)
mean_score = np.mean(scores)
if mean_score >= self.n_win_ticks and e >= 100:
if not self.quiet: print('Ran {} episodes. Solved after {} trials with mean {} ✔'.format(e,
e - 100,
mean_score))
return e - 100
if e % 100 == 0 and not self.quiet:
print('[Episode {}] - Mean survival time over last {} episodes was {} ticks.'.format(e,
100,
mean_score))
self.replay(self.batch_size)
if not self.quiet: print('Did not solve after {} episodes ????'.format(e))
return e
Создание экземпляра класса и запуск обучения

Кривая обучения
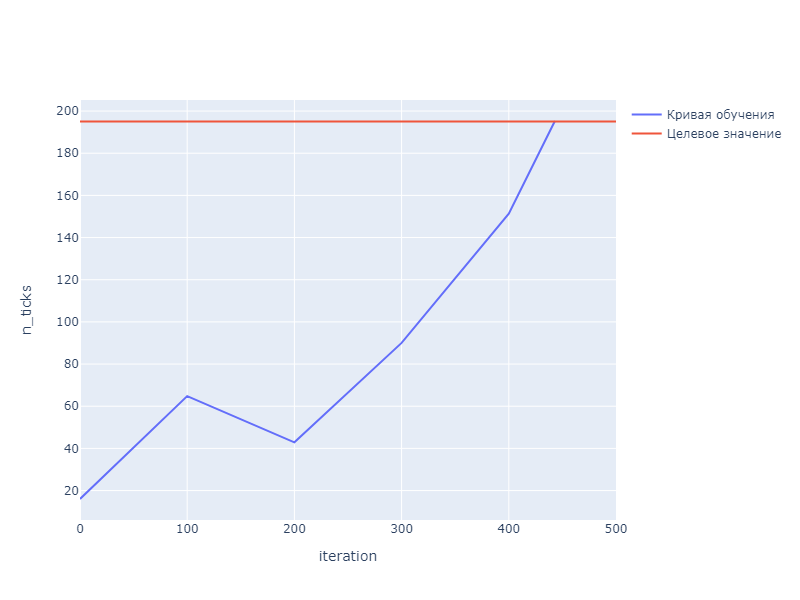
Рисунок 2 – график обучения модели
Тестирование модели
Устанавливаем максимальное количество тиков и тестируем модель.
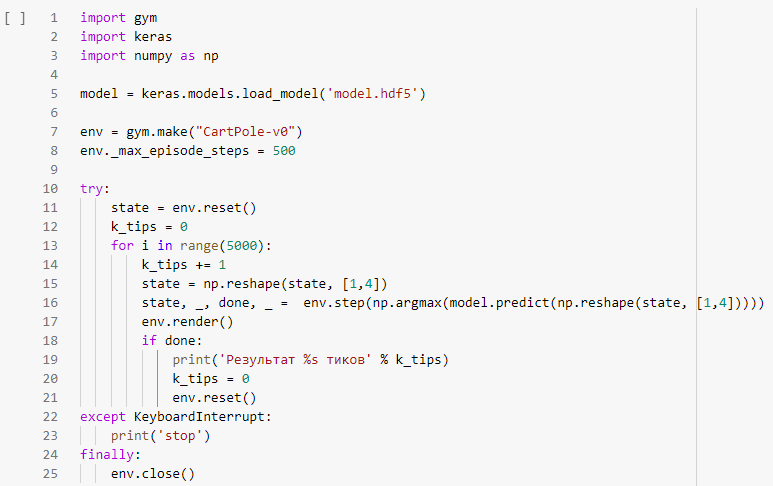
Результат работы модели
Результат 300 тиков
Результат 250 тиков
Результат 480 тиков
Результат 300 тиков
Результат 200 тиков
Результат 500 тиков
Результат 150 тиков
Результат 246 тиков
Результат 424 тиков
Результат 199 тиков
Результат 315 тиков
Результат 345 тиков
Результат 195 тиков
Результат 350 тиков
Результат 421 тиков