ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 85
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
-
множество терминальных символов; -
множество нетерминальных символов; -
множество продукций, каждая из которых состоит из нетерминала, называемого левой частью продукции, стрелки и последовательности токенов и/или нетерминалов, называемых правой частью продукции; -
указание одного из нетерминальных символов как стартового, или начального?
Лекция 2. ТЕОРИЯ ТРАНСЛЯЦИИ
План:
-
Лексический анализ. -
Синтаксический анализ. -
Метод рекурсивного спуска. -
Метод операторного предшествования. -
Внутреннее представление программы. -
Генерация кода.
Ключевые слова: трансляция, синтаксический анализ, постфиксная запись, внутреннее представление в виде четверок.
1. Лексический анализ
На вход компилятора, а следовательно и лексического анализатора поступает цепочка символов некоторого алфавита. Работа лексического анализатора заключается в том, чтобы сгруппировать определённые символы в единые синтаксические объекты, называемые лексемами. Какие объекты считать лексемами зависит от определения языка. Кроме терминальных символов (+, -, /, *, (,)), которые сами по себе являются лексемами, в программе некоторые комбинации символов часто рассматриваются как единые объекты. Среди типичных примеров можно указать следующие:
-
В некоторых языках цепочка, состоящая из одного или более пробелов, обычно рассматривается как один пробел. -
В языках программирования есть ключевые слова, такие как begin, епd, to, do, integer и др., каждое из которых считается одним символом. -
Каждая цепочка, представляющая цифровую константу, рассматривается как один элемент текста. -
Идентификаторы, используемые имена переменных, функций, процедур, меток и т.п., также считаются лексическими единицами алгоритмического языка.
Для программы на рис.1 будем считать лексемами терминальные символы, относящиеся к ключевым словам, знакам операций, разделителям (ргоgam, vаг, begin, integer, end, (,), :=, +, -, *, div, rеad, for, write, tо, do, :, ; , .). Кроме того возможны лексемы идентификаторы и
константы.
Итак, лексический анализатор должен исходный текст программы (рис. 1) представить в виде последовательности лексем. Для эффективности последующих действий каждая лексема обычно представляется некоторым кодом фиксированной длины (например, целым числом), а не в виде строки символов переменной длины.
Таблица 1
| Лексема | Код |
| Program | 1 |
| Var | 2 |
| Begin | 3 |
| End | 4 |
| Integer | 5 |
| For | 6 |
| Read | 7 |
| Write | 8 |
| To | 9 |
| Do | 10 |
| . | 11 |
| ; | 12 |
| : | 13 |
| , | 14 |
| := | 15 |
| + | 16 |
| - | 17 |
| * | 18 |
| Div | 19 |
| ( | 20 |
| ) | 21 |
| Ид | 22 |
| Конст | 23 |
Для вышеприведённого примера можно составить кодировочную таблицу (табл. 1). Если распознанная лексема является ключевым словом, разделителем или знаком операции, такая схема кодирования даёт всю необходимую информацию. В случае идентификатора или константы необходимы дополнительные данные (в простейшем случае – тип и указание на адрес ячейки памяти, где они хранятся). Обычно эти данные находятся в таблицах символов и в качестве дополнительной информации для лексемы типа идентификатор или константа может служить указатель на соответствующий элемент таблицы.
Таблица 2
| Строка | Код лексемы | Дополнительные данные | | Строка | Код лексемы | Дополнительные данные |
| 1 | 2 | 3 | 1 | 2 | 3 | |
| 1 | 1 | | 7 | 7 | | |
| | 22 | 1 | | 20 | | |
| | 12 | | | 22 | 3 | |
| 2 | 2 | | | 21 | | |
| | 22 | 2 | | 12 | | |
| | 14 | | 8 | 22 | 2 | |
| | 22 | 3 | | 15 | | |
| | 14 | | | 22 | 2 | |
| | 22 | 4 | | 16 | | |
| | 14 | | | 22 | 3 | |
| | 22 | 5 | 9 | 4 | | |
| | 13 | | | 12 | | |
| | 5 | | 10 | 22 | 4 | |
| | 12 | | | 15 | | |
| 3 | 3 | | | 22 | 2 | |
| 4 | 22 | 2 | | 19 | | |
| | 15 | | | 23 | #100 | |
| | 12 | | | 22 | 3 | |
| 5 | 6 | | | 18 | | |
| | 22 | 5 | | 22 | 3 | |
| | 15 | | | 12 | | |
| | 23 | # 1 | 11 | 8 | | |
| | 9 | | | 20 | | |
| | 23 | # 100 | | 22 | 4 | |
| | 10 | | | 14 | | |
| 6 | 3 | | | 22 | 2 | |
| | | | | 21 | | |
| | | | | 12 | 4 | |
| | | | | 11 | |
Таким образом, результат обработки лексическим анализатором обрабатываемой программы можно представить последовательностью лексем (табл. 2). Здесь в качестве дополнительных данных для констант используется значение самой константы, а для идентификатора – его номер в таблице символов.
2. Синтаксический анализ
Синтаксический анализ - второй этап компиляции. Во время этого этапа предложения программы распознаются как языковые конструкции используемой грамматики. Для того, чтобы выяснить, принадлежит ли предложение языку, необходимо построить алгоритм, который для любого предложения, допустимого грамматикой, давал бы последовательность выводов этой цепочки к начальному символу грамматики. Мы можем рассматривать этот процесс как построение дерева грамматического разбора для транслируемых предложений. Различают две категории алгоритмов разбора: нисходящий (сверху вниз) и восходящий (снизу вверх). Эти термины соответствуют способу построения синтаксических деревьев. Рассмотрим для примера предложение 35 в грамматике целых чисел:
N -> В/NВ; В -> 0/1/2/3/4/5/6/7/8/9
При нисходящем разборе дерево строится от корня (начального символа) вниз к концевым узлам (рис. 4).
Восходящий разбор состоит в том, что, отправляясь от заданной цепочки, пытаются привести её к начальному символу (рис. 5).
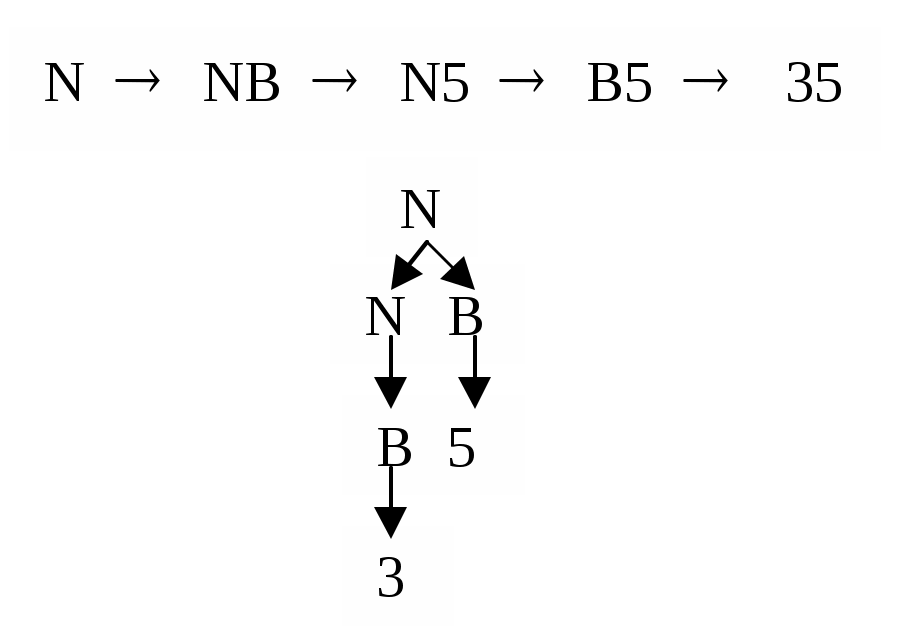
Рис. 4
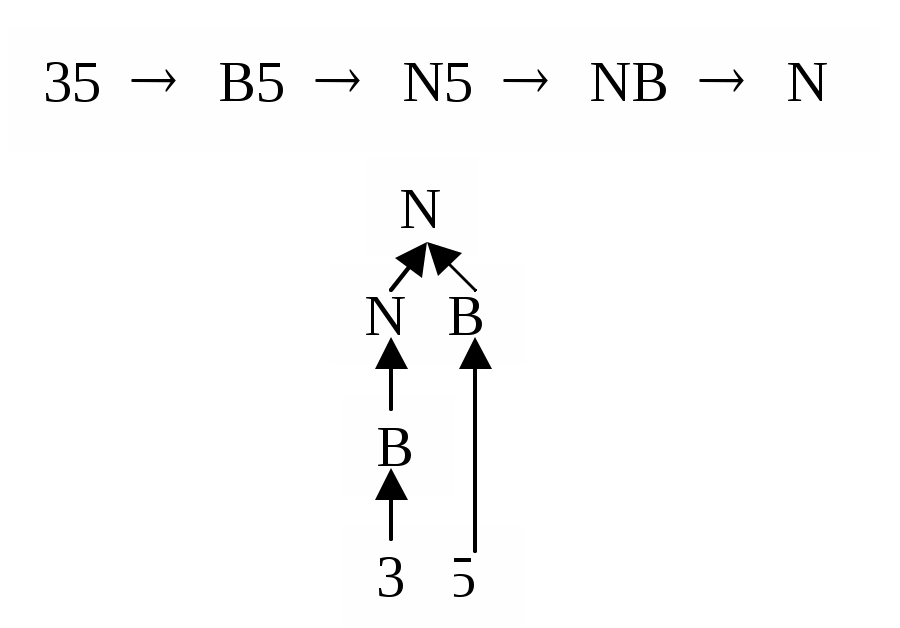
Рис. 5
Разработано множество методов синтаксического анализа. В лабораторных работах рассматриваются два метода: нисходящий и восходящий.
3. Метод рекурсивного спуска
Процесс грамматического разбора для этого метода состоит из отдельных процедур для каждого нетерминального символа, определённого в грамматике. Каждая такая процедура старается во входном потоке найти подстроку, начинающуюся с текущей лексемы, которая может быть интерпретирована как нетерминальный символ, связанный с данной процедурой. В процессе своей работы она может вызывать другие процедуры или даже рекурсивно саму себя для поиска других нетерминальных символов. Если эта процедура находит соответствующий нетерминальный символ, то она заканчивает работу и передаёт в вызывающую её программу признак успешного выполнения. Затем рассматривается следующая лексема, идущая за распознанной подстрокой. Если же процедура не может найти подстроку, которая могла бы быть интерпретирована как требуемый нетерминальный символ, она заканчивается с признаком неудачи или же вызывает процедуру диагностического сообщения.
Рассмотрим в качестве примера правило грамматики:
<ввод> read (<список переменных>)
Процедура метода рекурсивного спуска, соответствующая нетерминальному символу <ввод>, прежде всего исследует две последовательные лексемы "read" и "(" В случае совпадения эта процедура вызывает другую процедуру, соответствующую нетерминальному символу <список переменных>. Если эта процедура закончится успешно, то процедура <ввод> сравнивает следующую лексему с ")". Если все эти проверки окажутся успешными, то процедура <ввод> завершается с признаком успеха и устанавливает указатель текущей лексемы на лексему, следующую за ")".
Ещё пример. Процедура, соответствующая нетерминальному символу <оператор> анализирует очередную лексему для того, чтобы выбрать одну из четырёх альтернатив:
<оператор> <присваивание>/<ввод>/<вывод>/<цикл>
Если это лексема read, то вызывается процедура <ввод>. Если это лексема, соответствующая символу идентификатор, то вызывается процедура <присваивание>, поскольку это единственная альтернатива, которая может начинаться с лексемы идентификатор, и т.д.
Но если мы попытаемся написать полный набор процедур для грамматики, то столкнёмся со следующей трудностью - процедура для нетерминала <список переменных> будет не в состоянии выбрать одну из двух альтернатив, поскольку обе альтернативы: ид и <список переменных> могут начинаться с лексемы ид.
<список переменных>ид / <список переменных>, ид
Тут скрыта и более существенная трудность. Если процедура каким- либо образом решит попробовать альтернативу <список переменных>/ ид, то она немедленно вызовет рекурсивно саму себя для поиска нетерминального символа <список переменных>. Это приведёт ещё к одному рекурсивному вызову и т.д., в результате чего образуется бесконечная цепочка рекурсивных вызовов. Те же проблемы возникнут и для некоторых других правил грамматики (<раздел переменных>, <раздел операторов>, <арифметическое выражение>, <слагаемое>). Как избежать такой рекурсии? Для этого применяют другую запись грамматики. Например:
<список переменных> ид {, ид }
Эта запись, являющаяся широко принятым расширением БНФ означает, что конструкция, заключённая в фигурные скобки, может быть либо опущена, либо повторяться один или более число раз. Таким образом, это правило определяет нетерминальный символ <список переменных> как состоящий из единственной лексемы ид или же из произвольного числа следующих друг за другом лексем ид, разделённых запятой. Это, бесспорно эквивалентно ранее принятому правилу. В соответствии с этим новым определением процедура<список переменных> сначала ищет лексему ид, а затем продолжает