Файл: Пояснительная записка к курсовой работе по дисциплине "Надежность информационных систем" кр 02068055. 230201. 09 042 пз.rtf
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 07.11.2023
Просмотров: 68
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Studlancer.net - закажи реферат, курсовую, диплом!
Министерство образования и науки Российской Федерации
ФГБОУ ВПО "Брянская государственная инженерно – технологическая академия"
Кафедра информационных технологий
Расчет и повышение надежности информационной системы
Пояснительная записка к курсовой работе
по дисциплине "Надежность информационных систем"
КР – 02068055.230201.09 – 3.042 ПЗ
Брянск 2013
Содержание
Задание на курсовую работу
Введение
1. Первая часть. Кластерные вычислительные системы
1.1 Классификация архитектур кластерных систем
1.2 Топология кластеров
1.3 Топология кластерных пар
1.3.1 Топология N+1
1.3.2 Топология N×N
1.3.3 Топология с полностью раздельным доступом
2. Вторая часть
2.1 Задание
2.2 Исходные данные
2.3 Декомпозиция схемы
Вывод по 2 части
3. Задание
3.1 Расчет
Вывод по 3 части
Заключение
Список используемой литературы
Задание на курсовую работу
В процессе выполнения курсовой работы необходимо:
-
Ознакомиться с основными понятиями и методами расчета теории надежности.
-
Рассмотреть и описать основные структурные схемы надежности.
-
Получить навыки расчета базовых параметров системы (элемента), таких как вероятность безотказной работы, вероятность отказа, интенсивность отказов и др.
-
В соответствии с заданием увеличить надежность рассматриваемых систем с помощью метода резервирования и метода повышения вероятности безотказной работы элементов.
-
Для каждой из рассматриваемых задач построить графики зависимости вероятности безотказной работы элементов от времени, сделать выводы.
Введение
Надежность является фундаментальным понятием теории надежности, с помощью которого определяются другие понятия.
Надежность – это свойство объекта сохранять во времени в установленных пределах значения всех параметров, характеризующих его способность выполнять требуемые функции в заданных режимах и условиях применения, технического обслуживания, хранения и транспортирования.
Надежность является сложным свойством, и формируется такими составляющими, как безотказность, долговечность, восстанавливаемость и сохраняемость. Основным здесь является свойство безотказности – способность изделия непрерывно сохранять работоспособное состояние в течение времени. Потому наиболее важным в обеспечении надежности является повышение безотказности.
Особенностью проблемы надежности является ее связь со всеми этапами "жизненного цикла" от зарождения идеи создания до списания: при расчете и проектировании изделия его надежность закладывается в проект, при изготовлении надежность обеспечивается, при эксплуатации – реализуется.
Поэтому проблема надежности – комплексная проблема и решать ее необходимо на всех этапах и разными средствами. На этапе проектирования изделия определяется его структура, производится выбор или разработка элементной базы, поэтому здесь имеются наибольшие возможности обеспечения требуемого уровня надежности.
Основным методом решения этой задачи являются расчеты надежности (в первую очередь – безотказности), в зависимости от структуры объекта и характеристик его составляющих частей, с последующей необходимой коррекцией проекта. В результате расчета определяются количественные значения показателей надёжности.
1. Первая часть. Кластерные вычислительные системы
Одно из самых современных направлений в области создания вычислительных систем – это кластеризация. По производительности и коэффициенту готовности кластеризация представляет собой альтернативу симметричным мультипроцессорным системам. Понятие "кластер" можно определить как группу взаимно соединенных вычислительных систем (узлов), работающих совместно как единый вычислительный ресурс и создающих иллюзию наличия единственной ВМ. В качестве узла кластера может выступать как однопроцессорная ВМ, так и ВС типа SMP или MPP. Важно лишь то, что каждый узел может использоваться самостоятельно и отдельно от кластера. В плане архитектуры суть кластерных вычислений сводится к объединению нескольких узлов высокоскоростной сетью. Для описания такого подхода, помимо термина кластерные вычисления, достаточно часто применяют такие термины, как: "кластер рабочих станций" (workstation cluster), "гипервычисления" (hypercomputing), "параллельные вычисления на базе сети" (network-based concurrent computing), "ультравычисления" (ultracomputing).
Изначально перед кластерами ставились две задачи: достичь большой вычислительной мощности и обеспечить повышенную надежность ВС. Пионером в области кластерных архитектур считается корпорация DEC, создавшая первый коммерческий кластер в начале 80-х годов прошлого века.
В качестве узлов кластеров могут использоваться как одинаковые ВС (гомогенные кластеры), так и разные (гетерогенные кластеры). По своей архитектуре кластерная ВС является слабосвязанной системой.
В работе [BREW97] перечисляются четыре преимущества, достигаемые с помощью кластеризации:
-
абсолютная масштабируемость. Возможно создание больших кластеров, превосходящих по вычислительной мощности даже самые производительные одиночные ВМ. Кластер может содержать десятки узлов, каждый из которых представляет собой мультипроцессор;
-
наращиваемая масштабируемость. Кластер строится так, что его можно наращивать, добавляя новые узлы небольшими порциями. Таким образом, пользователь может начать с умеренной системы, расширяя ее по мере необходимости;
-
высокий коэффициент готовности. Поскольку каждый узел кластера – самостоятельная ВМ или ВС, отказ одного из узлов не приводит к потере работоспособности кластера. Во многих системах отказоустойчивость автоматически поддерживается программным обеспечением;
-
Превосходное соотношение цена/производительность. Кластеры любой производительности можно создать, используя стандартные "строительные блоки", при этом стоимость кластера будет ниже, чем у одиночной ВМ с эквивалентной вычислительной мощностью.
На уровне аппаратного обеспечения кластер – это просто совокупность независимых вычислительных систем, объединенных сетью. При соединении машин в кластер почти всегда поддерживаются прямые межмашинные связи. Решения могут быть простыми, основывающимися на аппаратуре Ethernet, или сложными с высокоскоростными сетями с пропускной способностью в сотни мегабайт в секунду. К последней категории относятся RS/6000 SP фирмы IBM, системы фирмы Digital на основе Memory Channel, ServerNet фирмы Compac Computer Corp.
Узлы кластера контролируют работоспособность друг друга и обмениваются специфической кластерной информацией. Контроль работоспособности осуществляется с помощью специального сигнала, часто называемого heartbeat, что можно перевести как сердцебиение. Этот сигнал передается узлами кластера друг другу чтобы подтвердить их нормальное функционирование.
Неотъемлемая часть кластера – специализированное программное (ПО) обеспечение, на которое возлагается задача поддержания вычислений при отказе одного или нескольких узлов. Такое ПО производит перераспределение вычислительной нагрузки при отказе одного или нескольких узлов кластера, а также восстановление вычислений при сбое в узле. Кроме того, при наличии в кластере совместно используемых дисков, кластерное ПО поддерживает единую файловую систему.
1.1 Классификация архитектур кластерных систем
В литературе приводятся различные способы классификации кластеров. Так, простейшая классификация ориентируется на то, являются ли диски в кластере совместно используемыми всеми узлами. На рис. 1, а показан кластер из двух узлов, координация работы которых обеспечивается за счет высокоскоростной линии, используемой для обмена сообщениями. Такой линией может быть локальная сеть, используемая также и не входящими в кластер компьютерами, либо выделенная линия. В последнем случае один или несколько узлов кластера будут иметь выход на локальную или глобальную сеть, благодаря чему обеспечивается связь между серверным кластером и удаленными клиентскими системами.
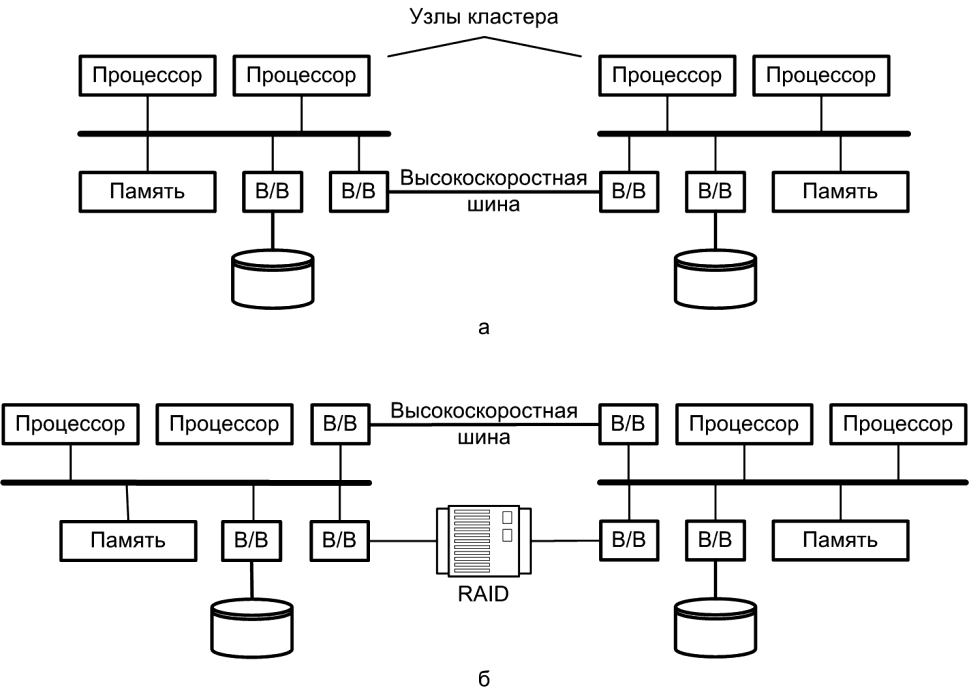
Рисунок 1 – Конфигурации кластеров: а – без совместно используемых дисков; б – с совместно используемыми дисками
Более ясную картину дает классификация кластеров по их функциональным особенностям. Такая классификация приведена в таблице 1.
Таблица 1 – Методы кластеризации
Studlancer.net - закажи реферат, курсовую, диплом!
Ознакомиться с основными понятиями и методами расчета теории надежности.
Рассмотреть и описать основные структурные схемы надежности.
Получить навыки расчета базовых параметров системы (элемента), таких как вероятность безотказной работы, вероятность отказа, интенсивность отказов и др.
В соответствии с заданием увеличить надежность рассматриваемых систем с помощью метода резервирования и метода повышения вероятности безотказной работы элементов.
Для каждой из рассматриваемых задач построить графики зависимости вероятности безотказной работы элементов от времени, сделать выводы.
абсолютная масштабируемость. Возможно создание больших кластеров, превосходящих по вычислительной мощности даже самые производительные одиночные ВМ. Кластер может содержать десятки узлов, каждый из которых представляет собой мультипроцессор;
наращиваемая масштабируемость. Кластер строится так, что его можно наращивать, добавляя новые узлы небольшими порциями. Таким образом, пользователь может начать с умеренной системы, расширяя ее по мере необходимости;
высокий коэффициент готовности. Поскольку каждый узел кластера – самостоятельная ВМ или ВС, отказ одного из узлов не приводит к потере работоспособности кластера. Во многих системах отказоустойчивость автоматически поддерживается программным обеспечением;
Превосходное соотношение цена/производительность. Кластеры любой производительности можно создать, используя стандартные "строительные блоки", при этом стоимость кластера будет ниже, чем у одиночной ВМ с эквивалентной вычислительной мощностью.
| Пассивное резервирование | Вторичный сервер при отказе первичного берет управление на себя |
| Резервирование с активным вторичным сервером | Вторичный сервер, как и первичный используется при решении задач |
| Самостоятельные серверы | Самостоятельные серверы имеют собственные диски, а данные постоянно копируются с первичного сервера на вторичный |
| Серверы с подключением ко всем дискам | Серверы подключены к одним и тем же дискам, но каждый сервер владеет своими дисками. Если один из серверов отказывает, то управление его дисками берет на себя другой сервер |
| Серверы с совместно используемыми дисками | Множество серверов совместно используют доступ к дискам |
Кластеризация с резервированием – наиболее старый и универсальный метод. Один из серверов берет на себя всю вычислительную нагрузку, в то время как второй остается неактивным, но готовым перенять вычисления при отказе основного сервера. Активный или первичный сервер периодически посылает резервному тактирующее сообщение. При отсутствии тактирующих сообщений (это рассматривается как отказ первичного сервера) вторичный сервер берет управление на себя. Такой подход повышает коэффициент готовности, но не улучшает производительности. Более того, если единственный вид общения между узлами – обмен сообщениями, и если оба сервера кластера не используют диски совместно, то резервный сервер не имеет доступа к базам данных, управляемым первичным сервером.
Пассивное резервирование для кластеров не характерно. Термин "кластер" относят к множеству взаимосвязанных узлов активно участвующих в вычислительном процессе и совместно создающих иллюзию одного мощной вычислительной машины. К такой конфигурации обычно применяют понятие системы "с активным вторичным сервером", и здесь выделяют три метода кластеризации: самостоятельные серверы, серверы без совместного использования дисков и серверы с совместным использованием дисков.
В первом подходе каждый узел кластера рассматривается как самостоятельный сервер с собственными дисками, причем ни один из дисков в системе не является совместно используемым (рис. 1, а). Схема обеспечивает высокую производительность и высокий коэффициент готовности, однако требует специального программного обеспечения для планирования распределения запросов клиентов по серверам так, чтобы добиться сбалансированного и эффективного использования всех серверов. Необходимо также обеспечить, чтобы при отказе одного из узлов в процессе выполнения какого-либо приложения, другой узел кластера мог перехватить и завершить данное приложение. Для этого данные в системе должны постоянно копироваться, чтобы каждый сервер имел доступ ко всем наиболее свежим данным в системе. Из-за этих издержек высокий коэффициент готовности обеспечивается лишь за счет потери производительности.
Для сокращения коммуникационных издержек, большинство кластеров в настоящее время состоят из серверов, подключенных к общим дискам, обычно представленным дисковым массивом RAID (рис. 1, б
).
Один из вариантов такого подхода предполагает, что совместно использование дисков не применяется. Общие диски разбиваются на разделы, и каждому узлу кластера выделяется свой раздел. Если один из узлов отказывает, кластер может быть реконфигурирован так, что права доступа к его разделу общего диска передаются другому узлу.
При втором варианте множество серверов разделяют во времени доступ к общим дискам, так что любой узел имеет доступ ко всем разделам всех общих дисков. Такой подход требует наличия каких-либо средств блокировки, гарантирующих, что в любой момент времени доступ к данным будет иметь только один из серверов.
Вычислительные машины (системы) в кластере взаимодействуют в соответствии с одним их двух транспортных протоколов. Первый из них – протокол TCP (Transmission Control Protocol) оперирует потоками байтов, гарантируя надежность доставки сообщения. Второй – UDP (User Datagram Protocol) "пытается" посылать пакеты данных без гарантии их доставки. В последнее время применяют специальные протоколы, которые работают намного лучше. Так, возглавляемый компанией Intel консорциум предложил новый протокол для внутрикластерных коммуникаций, который называется Virtual Interface Architecture и претендует на роль стандарта.
При обмене информацией используются два программных метода: метод передачи сообщений и метод распределенной совместно используемой памяти. Метод передачи сообщений опирается на явную передачу информационных сообщений между узлами кластера. При распределенной совместно используемой памяти также происходит передача сообщений, но движение данных между узлами кластера скрыто от программиста.
Кластеры обеспечивают высокий уровень доступности – в них отсутствуют единая операционная система и совместно используемая память, то есть нет проблемы когерентности кэшей. Кроме того, специальное программное обеспечение в каждом узле постоянно производит контроль работоспособности всех остальных узлов. Этот контроль основан на периодической рассылке каждым узлом сигнала "Я еще бодрствую". Если сигнал от некоторого узла не поступает, то такой узел считается вышедшим из строя; ему не дается возможность выполнять ввод/вывод, его диски и другие ресурсы (включая сетевые адреса) переназначаются другим узлам, а выполнявшиеся в вышедшем из строя узле программы перезапускаются в других узлах.
Производительность кластеров хорошо масштабируется при добавлении узлов. В кластере может выполняться несколько отдельных приложений, но для масштабирования отдельного приложения требуется, чтобы его части взаимодействовали путем обмена сообщениями. Нельзя, однако, не учитывать, что взаимодействия между узлами кластера занимают гораздо больше времени, чем в традиционных ВС.
Возможность практически неограниченного наращивания числа узлов и отсутствие единой операционной системы делают кластерные архитектуры исключительно хорошо масштабируемыми. Успешно используются системы с сотнями и тысячами узлов.
1.2 Топология кластеров
кластеризация резервирование мультипроцессорный
При создании кластеров с большим количеством узлов могут применяться самые разнообразные топологии. В данном разделе остановимся на топологиях, характерных для наиболее распространенных "малых" кластеров, состоящих из 2-4 узлов.
1.3 Топология кластерных пар
Топология кластерных пар используется при организации 2-х или 4-х узловых кластеров (рис. 2).
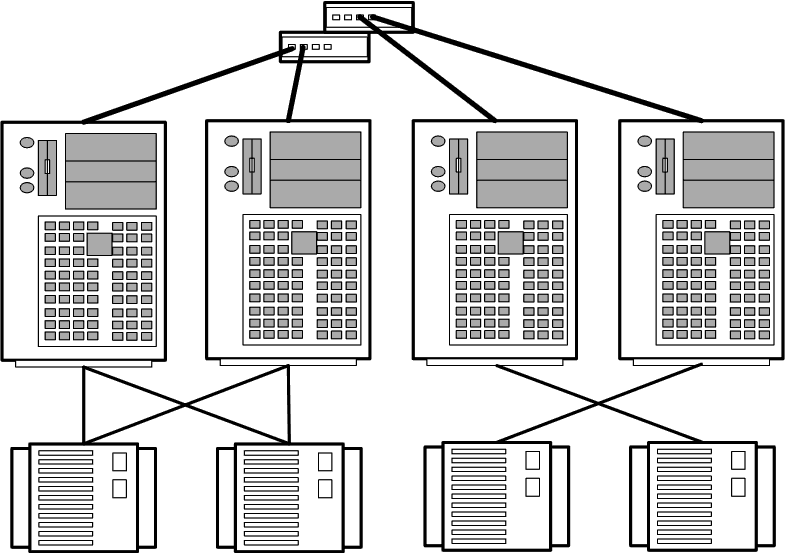
Рисунок 2 – Топология кластерных пар
Узлы группируются попарно. Дисковые массивы присоединяются к обоим узлам, входящим в состав пары, причем каждый узел пары имеет доступ ко всем дисковым массивам данной пары. Один из узлов пары используется как резервный для другого.
4-х узловая кластерная пара представляет собой простое расширение 2-х узловой топологии. Обе кластерные пары с точки зрения администрирования и настройки рассматриваются как единое целое.
Данная топология может быть применена для организации кластеров с высокой готовностью данных, но отказоустойчивость реализуется только в пределах пары, так как принадлежащие паре устройства хранения информации не имеют физического соединения с другой парой.
Топология используется при организации параллельной работы СУБД Informix XPS.
1.3.1 Топология N+1
Топология N+1 позволяет создавать кластеры из 2-, 3- и 4-х узлов (рис. 3).
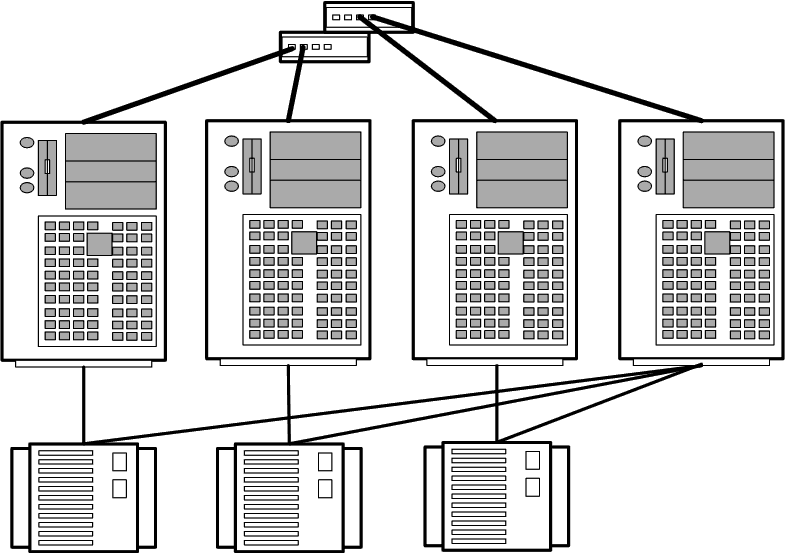
Рисунок 3 – Топология N+1
Каждый дисковый массив подключаются только к двум узлам кластера. Дисковые массивы организованы по схеме RAID 1. Один сервер имеет соединение со всеми дисковыми массивами и служит в качестве резервного для всех остальных (основных или активных) узлов. Резервный сервер может использоваться для обеспечения высокой степени готовности в паре с любым из активных узлов.
Топология рекомендуется для организации кластеров высокой готовности. В тех конфигурациях, где имеется возможность выделить один узел для резервирования, эта топология позволяет уменьшить нагрузку на активные узлы и гарантировать
, что нагрузка вышедшего из строя узла будет воспроизведена на резервном узле без потери производительности. Отказоустойчивость обеспечивается между любым из основных узлов и резервным узлом. В то же время топология не позволяет реализовать глобальную отказоустойчивость, поскольку основные узлы кластера и их системы хранения информации не связаны друг с другом.
1.3.2 Топология NN
Аналогично топологии N+1, топология NN позволяет создавать кластеры из 2-, 3- и 4-х узлов, но в отличие от первой обладает большей гибкостью и масштабируемостью.
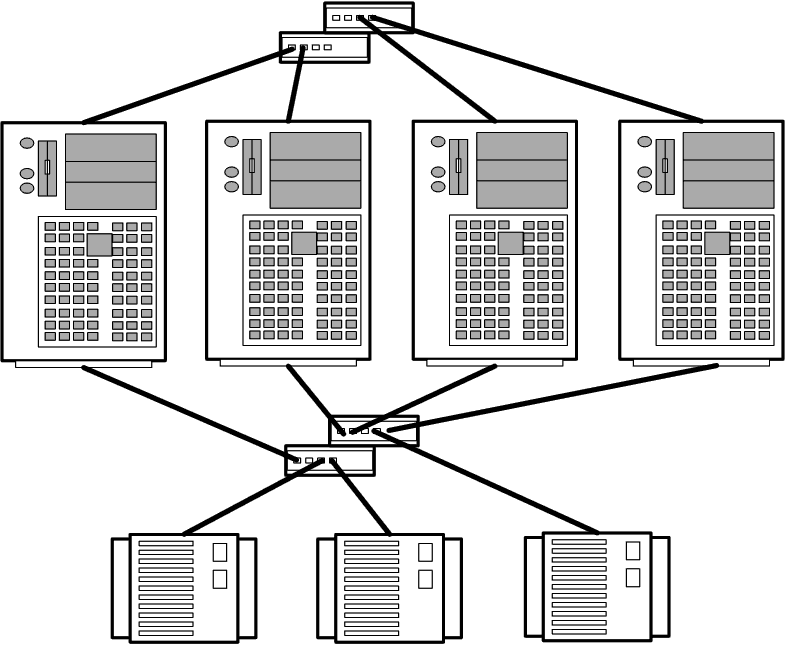
Рисунок 4 – Топология NN
Только в этой топологии все узлы кластера имеют доступ ко всем дисковым массивам, которые, в свою очередь, строятся по схеме RAID 1 (с дублированием). Масштабируемость топологии проявляется в простоте добавления к кластеру дополнительных узлов и дисковых массивов без изменения соединений в существующей системе.
Топология позволяет организовать каскадную систему отказоустойчивости, при которой обработка переносится с неисправного узла на резервный, а в случае его выхода из строя на следующий резервный узел и т.д. Кластеры с топологией NN обеспечивают поддержку приложения Oracle Parallel Server, требующего соединения всех узлов со всеми системами хранения информации. В целом топология обладает лучшей отказоустойчивостью и гибкостью по сравнению с другими топологиями.
1.3.3 Топология с полностью раздельным доступом
В топологии с полностью раздельным доступом(рис.5) каждый дисковый массив соединяется только с одним узлом кластера.
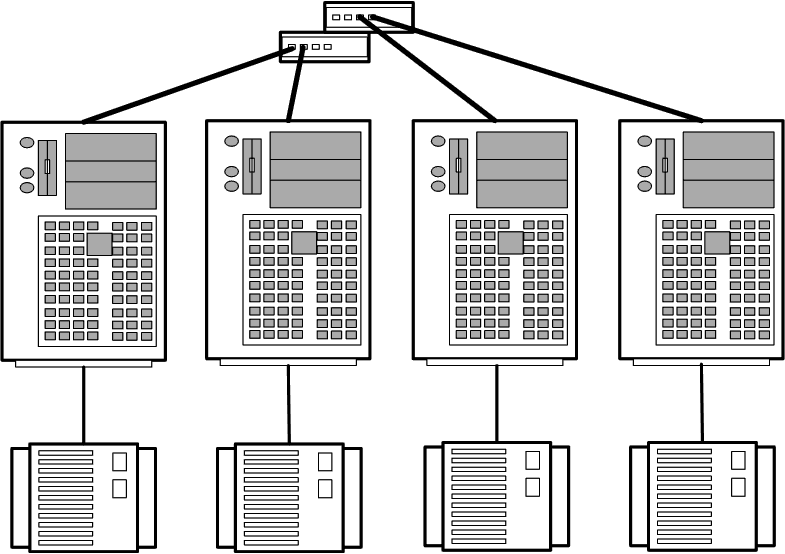
Рисунок 5 – Топология с полностью раздельным доступом
Топология рекомендуется только для тех приложений, для которых характерна архитектура полностью раздельного доступа, например, для уже упоминавшейся СУБД Informix XPS.
2. Вторая часть
2.1 Задание
По структурной схеме надежности технической системы в соответствии с вариантом задания, требуемому значению вероятности безотказной работы системы γ и значениям интенсивностей отказов ее элементов λi требуется:
1. Построить график изменения вероятности безотказной работы системы от времени наработки в диапазоне снижения вероятности до уровня 0.1 – 0.2.
2. Определить γ – процентную наработку технической системы.