Файл: Технологические платформы обработки больших данных.docx
Добавлен: 22.11.2023
Просмотров: 6820
Скачиваний: 23
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Глава 1.Теоретические основы исследования платформ обработки больших данных
1.1. Платформы анализа больших данных: понятие и характеристика
1.2.Функции платформы обработки больших данных
Глава 2. Современные технологические платформы обработки больших данных
2.1.Анализ и структура российских платформ
2.2. Факторы внедрения технологических платформ для анализа больших данных
Глава 3.Направления совершенствования технологических платформ обработки больших данных
3.1.Проблемы формирования технологических платформ
3.2.Перспективы развития технологических платформ обработки больших данных
Следовательно, функциями платформы обработки больших данных являются:
-
сбор данных и исследование; -
экспериментирование и разработка модели; -
развертывание и интеграция.
На каждом из этапов ставятся задачи, которые выполняет платформа.
Существуют также задачи, которые являются общими, которые включают управление данными, управление процессами обработки и масштабирования.
Для того, чтобы решать данные задачи, платформы выполняют следующие функции: прием, подготовка и исследование данных, генерация признаков, создание, обучение, тестирование и деплой моделей, мониторинг и обслуживание системы.
Отметим и то, что платформа должна обеспечить безопасность данных, хранение данные.
Демонстрация визуальных аналитических данных и прогнозов доступна на мобильных устройствах, в облаке, на веб-сайтах или в локальной среде.
Развитие языков программирования позволяет предположить дальнейшие совершенствования в данной сфере, в связи с чем необходимо выявить основные направления и особенности функционирования средств и методов визуализации на данный момент.
Язык программирования Python – один из лучших инструментов программиста при необходимости визуализации любого количества нумерованных и ненумерованных данных. Жертвуя скоростью выполнения, программист получает простоту и удобство в использовании большого числа продуктов (библиотек) для решения различных задач, каждый из которых имеет свои преимущества и недостатки. Библиотеки визуализации Python позволяют получить различные графики на основе данных, полученных из различных источников. Python также имеет возможность реализации моделей машинного обучения различной сложности. Чаще всего подобные модели имеют высокий коэффициент правдивости, что положительно сказывается на обработке данных при использовании машины в тестировании.
Рассмотрим наиболее популярные библиотеки с точки зрения их удобства и функциональности.
Seaborn одна из известных библиотек для визуализации. Ее основным преимуществом является «низкий порог входа»: очень проста в использовании, что делает ее хорошим вариантом для начинающих программистов. Скорость выполнения операций Seaborn позволяет строить графики и обрабатывать их с высокой скоростью, которую может обеспечить не каждая библиотека. Функционал включает в себя все основные типы графиков: линейные (рисунок 1), столбчатые,
графики распределения, тепловые карты и так далее.
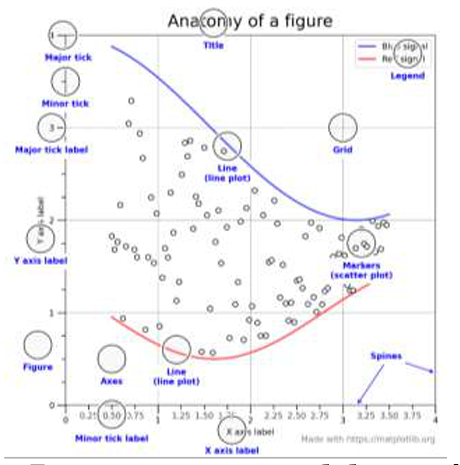
Рисунок 1- Линейная модель данных библиотеки Matplotlib3
Основным недостатком данной библиотеки является то, что она создана на основе Matplotlib - многофункциональной библиотеки для визуации. Именно поэтому для точной настройки различных графиков программисту необходимо знать тонкости настройки аргументов Matplotlib, что может быть затруднительно. Matplotlib одна из базовых и известнейших библиотек для визуализации на языке Python.
Plotly – комплексная библиотека для визуализации данных на языке Python. Ее главным отличием является то, что графики, построенные с помощью данной библиотеки, не являются статичными изображениями, а имеют собственное графическое оформление (возможность приближения, получения детальной информации о части графика, экспорт изображения и т.д.). Plotly также позволяет создавать .html файлы с детальным отчетом о данных (Plotly dash). Функционал библиотеки схож с Matplotlib – имеется детальная настройка большинства параметров графика. Plotly также позволяет строить 3D-графики и картограммы, что является редкостью из-за относительной сложности детализации мелких объектов (населенных пунктов, городов и стран).
Проведем сравнительный анализ свойств перечисленных библиотек (таблица 2).
Таблица 2
Сравнительный анализ современных средств визуализации данных4
| Функциональные особенности | Seaborn | Matplotlib | Plotly |
| Внешняя настройка графика | + | + | - |
| Возможность приближения | - | - | + |
| Анимация, графика | - | - | + |
| Экспорт в HTML | - | - | + |
| Скорость обработки | средняя | высокая | низкая |
| Подача информации | статическое изображение | статическое изображение | динамическое изображение, анимация, увеличение-уменьшение объекта |
| Порог входа | низкий | высокий | средний |
| Возможность настройки | частично настраиваемая | гибкая настройка | гибкая настройка |
| Требовательность к ресурсам | низкое потребление | низкое потребление | высокое потребление, зависимость потребления от количества графиков |
Проанализировав три наиболее популярные библиотеки визуализации (Seaborn, Matplotlib и Plotly) можно отметить, что при работе с данными библиотека Plotly имеет большее количество преимуществ (создание анимаций, 3D проекций, использование для отображения виртуальной и дополненной реальности) по сравнению с другими. Необходимо учитывать требовательность данной библиотеки по затрачиваемым времени и ресурсам для обработки данных и создания изображений, как статических, так и динамических. Данное ограничение несущественно при использования небольших наборов и минимального количества графиков на базовых системах.
Таким образом, технологические платформы обработки больших данных обеспечивают возможности обработки полной информации об исследуемых объектах.
Глава 2. Современные технологические платформы обработки больших данных
2.1.Анализ и структура российских платформ
Цифровизация открывает новые разделы информационных технологий, такие как, облачные технологии, большие данные, аналитика данных и другие.
Данные накапливались годами и их становилось очень много, и появилась задача использования этих сохраненных данных т.е. обрабатывать эти данные таким образом, чтобы они могли нам «добывать» полезную информацию.
В России, на данный момент, не так много учебных программ для специалистов по работе с Большими данными. Программы обучения предлагают: Московский физико-технический институт на факультете инноваций и высоких технологий кафедра «Яндекс»; МГУ имени М. В. Ломоносова факультет вычислительной математики и кибернетики предлагает программу «Большие данные и методы решения задач», а также похожие программы предлагает ВШЭ и СПбГУ5.
На текущий момент на рынке представлен большой ряд программных продуктов, имеющих схожий между собой функционал и ввиду этого, проблема выбора программного средства является актуальной.
Рассмотрим две отечественные аналитические платформы Loginom и Deductor.
Оба данных программных продукта поддерживают русский язык, однако в Loginom также присутствует и английский язык.
Интерфейс Loginom, изображён на рисунке 2, представляет собой веб приложение.
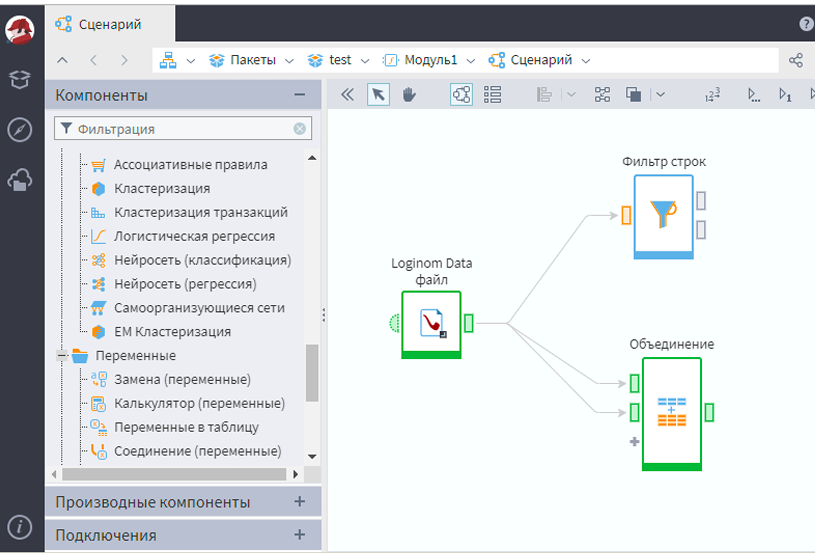
Рисунок 2 – Интерфейс Loginom6
Deductor, представлен на рисунке 3, это приложение для операционной системы Windows.
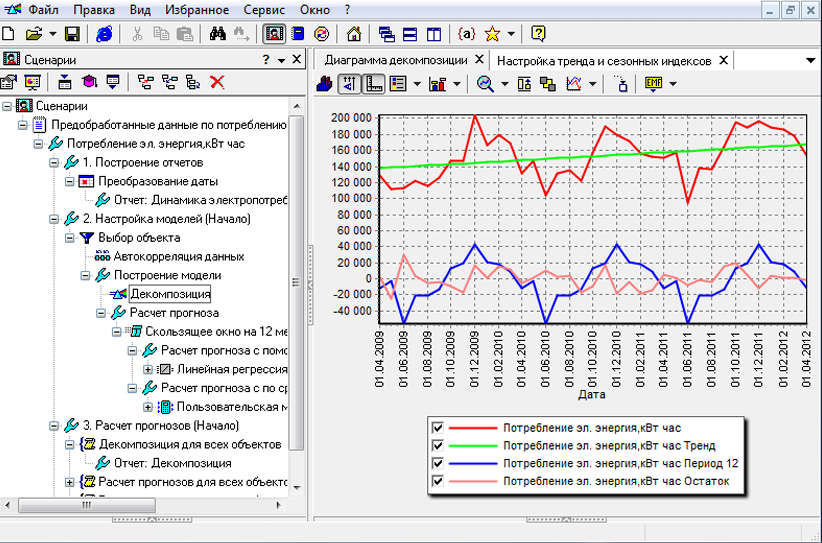
Рисунок 3 – Интерфейс Deductor7
Оба программных продукта можно использовать на персональном компьютере и сервере предприятия, однако Loginom может работать в облаке (SaaS), что позволяет использовать данное программное обеспечение на серверах поставщика программы.
Сценарий в Deductor представлен в форме дерева, состоящее из узлов обработчиков данных и визуализаторов. Этот метод удобен, когда нужно реализовать простую логику.
Однако у этого метода имеются свои минусы: постоянно необходимо объединять, разделять, подтягивать данные на различных этапах анализа, декомпозировать большие задачи и объединять логические блоки в подмодели.
В Loginom сценарий отображается в форме графа, который более естественно отображает перемещение данных между узлами, что дает больше возможностей для реализации сложной логики.
Одним из отличий Loginom от Deductor является поддержка четырёх парадигм объектно-ориентированного моделирования: абстракция, инкапсуляция наследование, полиморфизм.
Разработка сценариев в Deductor реализовано по модели «снизу вверх», то есть необходимо наличие данных на входе.
К преимуществам данной модели можно отнести:
– высокую скорость реализации, благодаря наличию информации о структуре данных на входе;
– простоту поиска ошибок и отладки.
Недостатками модели являются:
– ориентированность на отдельных задачах;
– сложность повторного использования в аналогичных задачах;
– необходимость редактирования всего сценария при изменении входных данных.
В Loginom есть возможность проектировать сценарии как «снизу вверх», так и «сверху вниз», то есть при отсутствии входных данных.
Преимущества разработки сценария «сверху вниз» следующие:
– структурированность процесса проектирования;
– описание требований к данных для проектируемой модели;
– возможность повторного использования.
Недостатками модели являются:
– необходимо иметь представление о конечной структуре модели;
– необходимо продумать входы и выходы модели.
Сравнение функционала данных программ представлено в таблице 3.
Таблица 3
Сравнение Loginom и Deductor8
| Функции | Платформа | |
| Loginom | Deductor | |
| Администрирование | Присутствует | Присутствует |
| Анализ больших данных | Присутствует | Отсутствует |
| Визуализация данных | Присутствует | Присутствует |
| Интеллектуальный анализ данных | Присутствует | Присутствует |
| Машинное обучение | Присутствует | Присутствует |
| Многопользовательский доступ | Присутствует | Присутствует |
| Наличие API | Присутствует | Отсутствует |
| Потоковая аналитика | Присутствует | Отсутствует |
| Создание собственных компонентов и подключаемые пакеты | Присутствует | Отсутствует |