Файл: Беспятый Г. Ю. должность, уч степень, звание подпись, дата инициалы, фамилия отчет о лабораторной работе 1 по курсу теория систем и системный анализ.docx
Добавлен: 23.11.2023
Просмотров: 70
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ
федеральное государственное автономное образовательное учреждение высшего образования
«САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ»
Кафедра 2
ОТЧЕТ
ЗАЩИЩЕН С ОЦЕНКОЙ
ПРЕПОДАВАТЕЛЬ
| ассистент | | | | Беспятый Г.Ю. |
| должность, уч. степень, звание | | подпись, дата | | инициалы, фамилия |
| ОТЧЕТ О ЛАБОРАТОРНОЙ РАБОТЕ №1 |
| |
по курсу: ТЕОРИЯ СИСТЕМ И СИСТЕМНЫЙ АНАЛИЗ |
| |
| |
РАБОТУ ВЫПОЛНИЛ
| СТУДЕНТ ГР. № | М122 | | | | Комаренко М.Ю. |
| | | | подпись, дата | | инициалы, фамилия |
Санкт-Петербург 2023
Описание задачи
-
Выберите данные формате CSV на сайте kaggle. -
Загрузите набор данных в формате CSV с помощью Pandas. -
Используя Pandas, выполните операции по обработке данных:
-
вычисление среднего и медианы -
вычисление дисперсии и стандартного отклонения -
вычисление корреляции между различными переменными -
нахождение зависимостей между различными переменными
Используйте SciPy для выполнения статистических тестов:
-
t-тест для сравнения средних значений двух выборок -
анализ дисперсии (ANOVA) для сравнения средних значений многих выборок -
корреляционный анализ для оценки зависимостей между переменными
Визуализируйте полученные результаты с помощью библиотеки Matplotlib.
Код программы
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
# загрузка данных из CSV-файла
data = pd.read_csv("starbucks.csv")
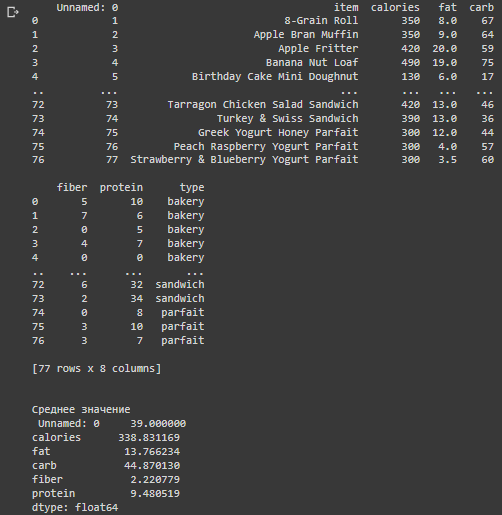
print(data)
print()
# вычисление среднего и медианы
mean = data.mean()
print("\nСреднее значение\n", mean)
median = data.median()
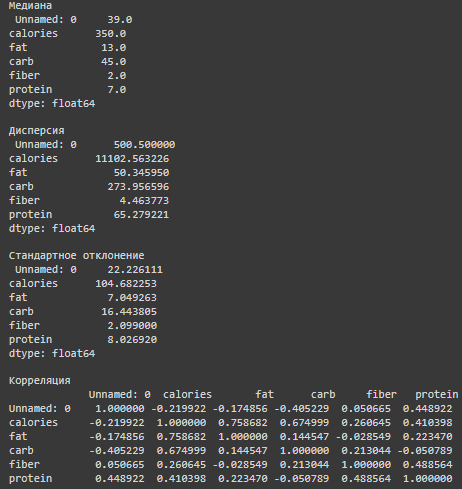
print("\nМедиана\n", median)
# вычисление дисперсии и стандартного отклонения
variance = data.var()
print("\nДисперсия\n", variance)
std_dev = data.std(ddof=0)
print("\nСтандартное отклонение\n", std_dev)
# вычисление корреляций
corr_coef = data.corr()
print("\nКорреляция\n", corr_coef)
# t-тест
t_stat, p_value = stats.ttest_ind(data['calories'], data['carb'])
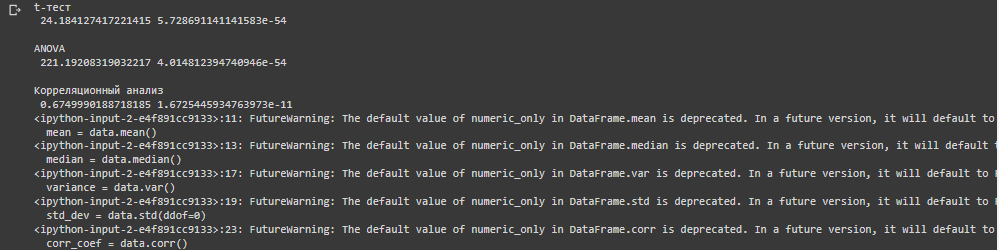
print("\nt-тест\n", t_stat, p_value)
# ANOVA
f_stat, p_value = stats.f_oneway(data['fat'], data['carb'], data['protein'])
print("\nANOVA\n", f_stat, p_value)
# корреляционный анализ
r, p_value = stats.pearsonr(data['calories'], data['carb'])
print("\nКорреляционный анализ\n", r, p_value)
# визуализация результатов
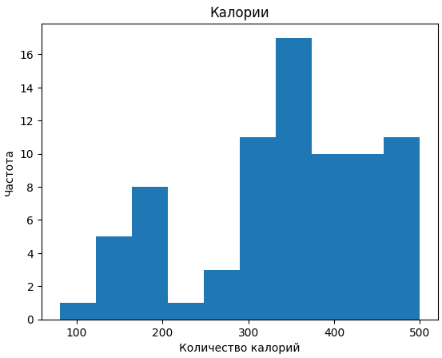
plt.hist(data['calories'], bins=10)
plt.title("Калории")
plt.xlabel("Количество калорий")
plt.ylabel("Частота")
plt.show()
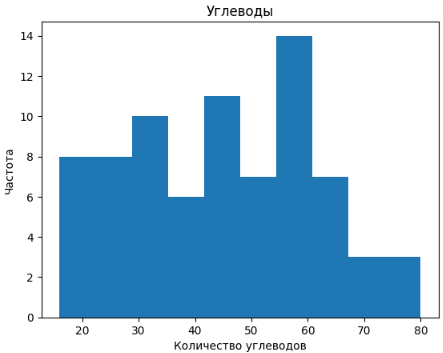
plt.hist(data['carb'], bins=10)
plt.title("Углеводы")
plt.xlabel("Количество углеводов")
plt.ylabel("Частота")
plt.show()
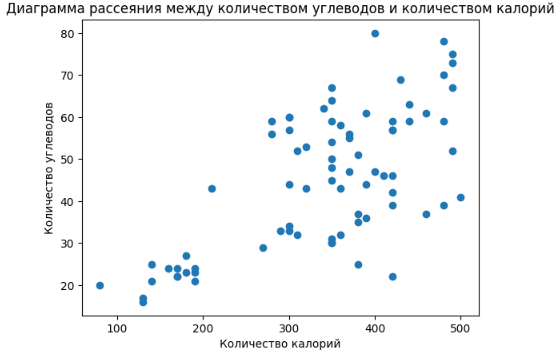
plt.scatter(data['calories'], data['carb'])
plt.title("Диаграмма рассеяния между количеством углеводов и количеством жиров")
plt.xlabel("Количество калорий")
plt.ylabel("Количество углеводов")
plt.show()
Результат программы
Выводы
1) Корреляция. Проанализировав полученные корреляты, можно сделать вывод
, что все единицы пищевой ценности связаны с калорийностью, в большей степени: углеводы и жиры, в меньшей: клетчатка.
2) t – тест. Значение t довольно низкое, что говорит о маленькой разнице средних значений.
3) ANOVA. Высокое значение f показателя говорит о значимой разнице между средними группами.
4) Корреляционный анализ. Показатель r положителен достаточно высокий, что говорит о высокой корреляции значений калорий и углеводов.
5) Получившиеся изображения.
Большинство продуктов имеют калорийность больше 300, набирают они данную калорийность преимущественно за счет жиров и углеводов, также размеры порций не очень большие, учитывая всё выше сказанное, можно сделать вывод, что данные продукты не очень полезные.
Самый низкокалорийный продукт – «Deluxe Fruit Blend», 80 килокалорий, 20г углеводов
Самый высококалорийный продукт – «Sausage & Cheddar Classic Breakfast Sandwic», 500 килокалорий, 41г углеводов
Самый низкоуглеводный продукт – «"Double Fudge Mini Doughnut», 130 килокалорий, 16г углеводов
Самый высокоуглеводный продукт – «Reduced-Fat Banana Chocolate Chip Coffee Cake», 400 килокалорий, 80г углеводов
Категория с самыми высококалорийными продуктами: «sandwich» - 395,7
Категория с самыми низкокалорийными продуктами: «salad» - 80