Файл: Реферат по дисциплине Архитектура эвм по теме Построение вычислительных кластеров.docx
Добавлен: 30.11.2023
Просмотров: 47
Скачиваний: 3
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
метод передачи сообщений и метод распределенной совместно используемой памяти. Метод передачи сообщений опирается на явную передачу информационных сообщений между узлами кластера. При распределенной совместно используемой памяти также происходит передача сообщений, но движение данных между узлами кластера скрыто от программиста.
Кластеры обеспечивают высокий уровень доступности — в них отсутствуют единая операционная система и совместно используемая память, то есть нет проблемы когерентности кэшей. Кроме того, специальное программное обеспечение в каждом узле постоянно производит контроль работоспособности всех остальных узлов. Этот контроль основан на периодической рассылке каждым узлом сигнала «Я еще бодрствую». Если сигнал от некоторого узла не поступает, то такой узел считается вышедшим из строя; ему не дается возможность выполнять ввод/вывод, его диски и другие ресурсы (включая сетевые адреса) переназначаются другим узлам, а выполнявшиеся в вышедшем из строя узле программы перезапускаются в других узлах.
Производительность кластеров хорошо масштабируется при добавлении узлов. В кластере может выполняться несколько отдельных приложений, но для масштабирования отдельного приложения требуется, чтобы его части взаимодействовали путем обмена сообщениями. Нельзя, однако, не учитывать, что взаимодействия между узлами кластера занимают гораздо больше времени, чем в традиционных ВС.
Возможность практически неограниченного наращивания числа узлов и отсутствие единой операционной системы делают кластерные архитектуры исключительно хорошо масштабируемыми. Успешно используются системы с сотнями и тысячами узлов.
При создании кластеров с большим количеством узлов могут применяться самые разнообразные топологии. В данном разделе остановимся на топологиях, характерных для наиболее распространенных «малых» кластеров, состоящих из 2-4 узлов.
Топология кластерных пар используется при организации 2-х или 4-х узловых кластеров (рис. 2).
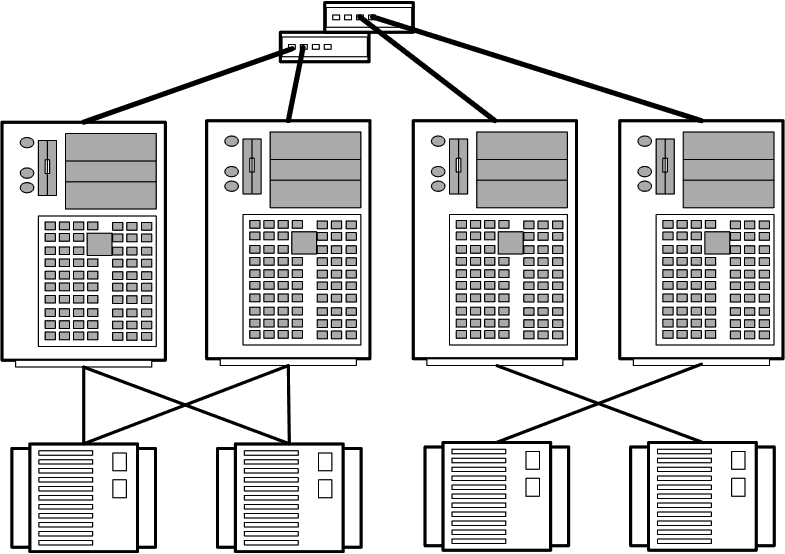
Рис. 2. Топология кластерных пар
Узлы группируются попарно. Дисковые массивы присоединяются к обоим узлам, входящим в состав пары, причем каждый узел пары имеет доступ ко всем дисковым массивам данной пары. Один из узлов пары используется как резервный для другого.
4-х узловая кластерная пара представляет собой простое расширение 2-х узловой топологии. Обе кластерные пары с точки зрения администрирования и настройки рассматриваются как единое целое.
Данная топология может быть применена для организации кластеров с высокой готовностью данных, но отказоустойчивость реализуется только в пределах пары, так как принадлежащие паре устройства хранения информации не имеют физического соединения с другой парой.
Топология используется при организации параллельной работы СУБД Informix XPS.
Топология N+1 позволяет создавать кластеры из 2-, 3- и 4-х узлов (рис. 3).
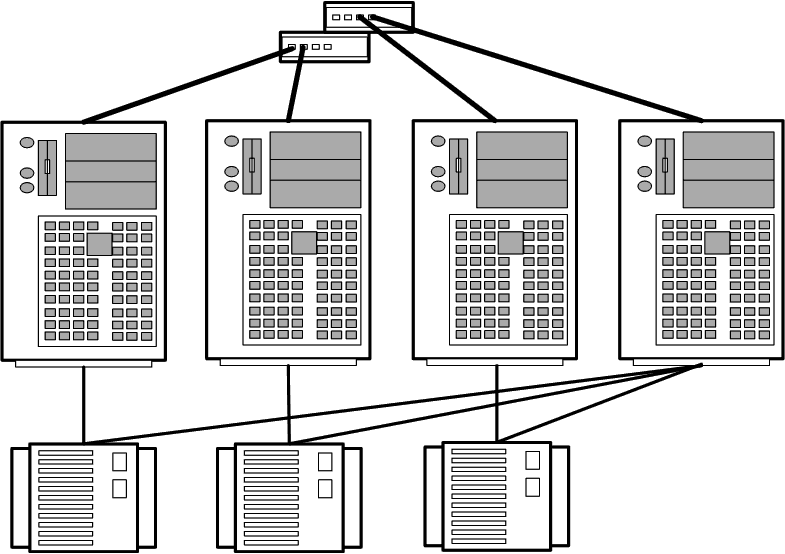
Рис. 3. Топология N+1
Каждый дисковый массив подключаются только к двум узлам кластера. Дисковые массивы организованы по схеме RAID 1. Один сервер имеет соединение со всеми дисковыми массивами и служит в качестве резервного для всех остальных (основных или активных) узлов. Резервный сервер может использоваться для обеспечения высокой степени готовности в паре с любым из активных узлов.
Топология рекомендуется для организации кластеров высокой готовности. В тех конфигурациях, где имеется возможность выделить один узел для резервирования, эта топология позволяет уменьшить нагрузку на активные узлы и гарантировать, что нагрузка вышедшего из строя узла будет воспроизведена на резервном узле без потери производительности. Отказоустойчивость обеспечивается между любым из основных узлов и резервным узлом. В то же время топология не позволяет реализовать глобальную отказоустойчивость, поскольку основные узлы кластера и их системы хранения информации не связаны друг с другом.
Аналогично топологии N+1, топология NN (рис. 14.12) позволяет создавать кластеры из 2-, 3- и 4-х узлов, но в отличие от первой обладает большей гибкостью и масштабируемостью.
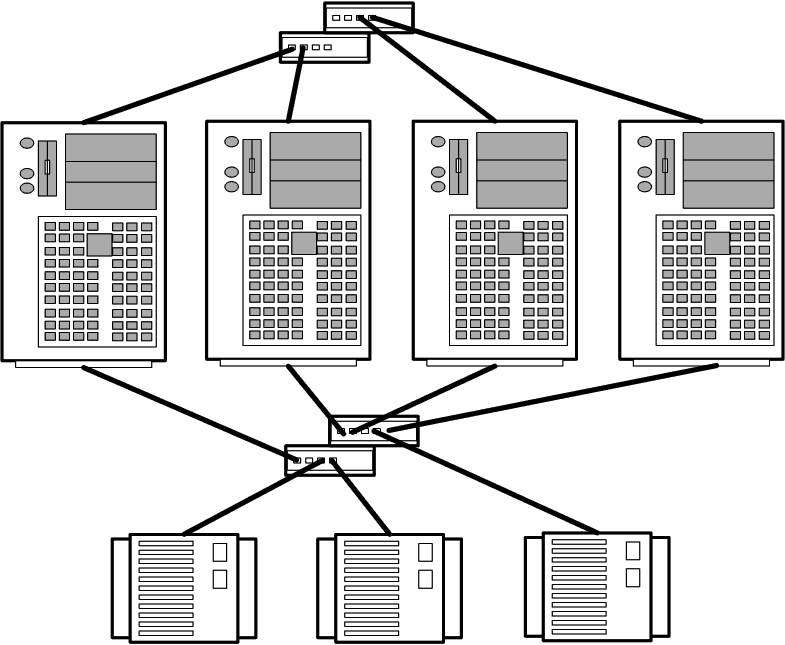
Рис. 4. Топология NN
Только в этой топологии все узлы кластера имеют доступ ко всем дисковым массивам, которые, в свою очередь, строятся по схеме RAID 1 (с дублированием). Масштабируемость топологии проявляется в простоте добавления к кластеру дополнительных узлов и дисковых массивов без изменения соединений в существующей системе.
Топология позволяет организовать каскадную систему отказоустойчивости, при которой обработка переносится с неисправного узла на резервный, а в случае его выхода из строя на следующий резервный узел и т.д. Кластеры с топологией NN обеспечивают поддержку приложения Oracle Parallel Server, требующего соединения всех узлов со всеми системами хранения информации. В целом топология обладает лучшей отказоустойчивостью и гибкостью по сравнению с другими топологиями.
В топологии с полностью раздельным доступом(рис. 5) каждый дисковый массив соединяется только с одним узлом кластера.
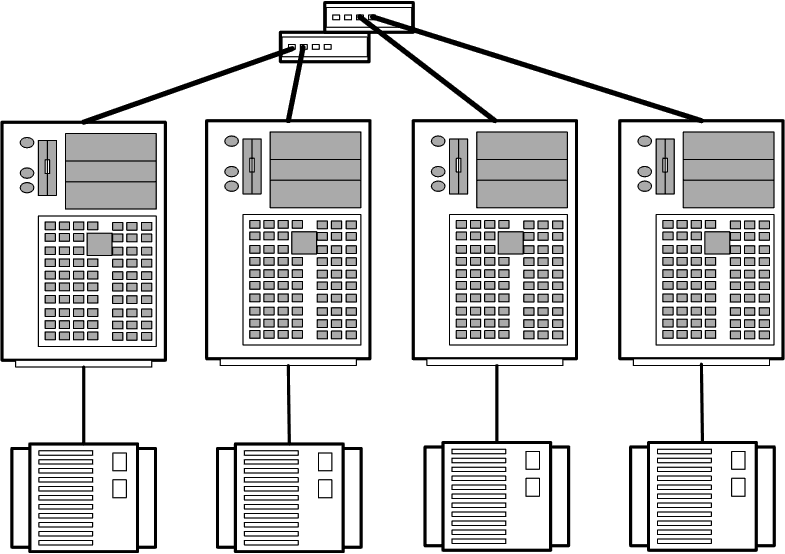
Рис. 5. Топология с полностью раздельным доступом
Топология рекомендуется только для тех приложений, для которых характерна архитектура полностью раздельного доступа, например, для уже упоминавшейся СУБД Informix XPS.
Компания DEC в 1983 году первой анонсировала концепцию кластерной системы, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер (рис. 6) представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования. VAX-кластер обладает следующими свойствами.
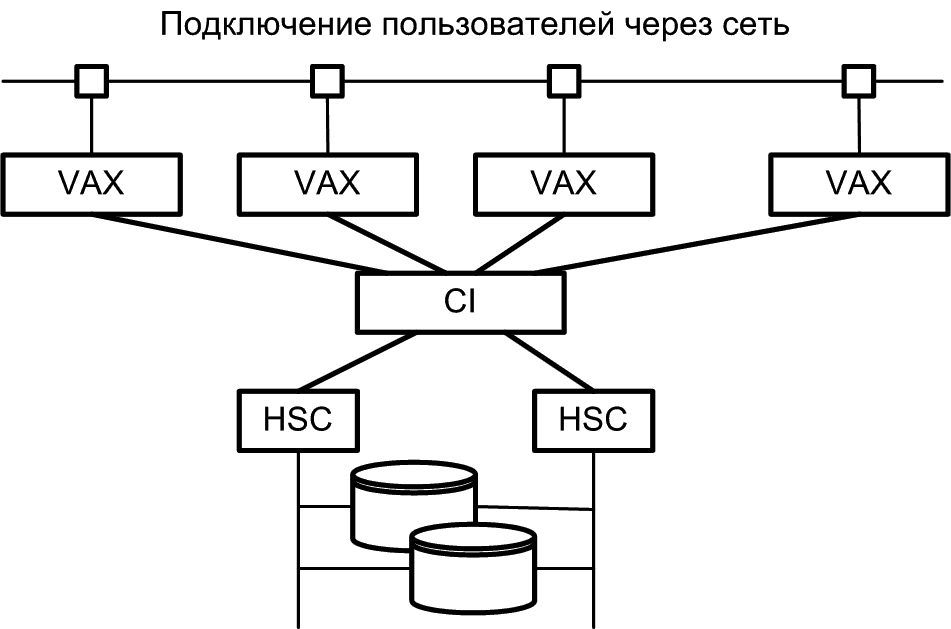
Рис. 6..VAX/VMS-кластер
Работа VAX-кластера определяется двумя главными компонентами: высокоскоростным механизмом связи и системным программным обеспечением, которое обеспечивает клиентам прозрачный доступ к системному сервису. Физически связи внутри кластера реализуются с помощью трех различных шинных технологий с различными характеристиками производительности.
Шина связи компьютеров CI (Computer Interconnect) работает со скоростью 100 Мбит/с и используется для соединения компьютеров VAX и контроллеров HSC с помощью коммутатора Star Coupler. Каждая связь CI имеет двойные избыточные линии, две для передачи и две для приема. Линии функционируют по технологии CSMA, которая для устранения коллизий использует специфические для данного узла задержки. Максимальная длина связи CI составляет 45 метров. Звездообразный коммутатор Star Coupler может поддерживать подключение до 32 шин CI, каждая из которых предназначена для подсоединения компьютера VAX или контроллера HSC. Контроллер HSC представляет собой интеллектуальное устройство, которое управляет работой дисковых и ленточных накопителей.
В основе системного программного обеспечения рассматриваемой кластерной системы лежит распределенный менеджер блокировок (DLM, Distributed Lock Manager). Он гарантирует правильное взаимодействие процессоров друг с другом при обращениях к общим ресурсам, таким, например, как диски. Очень важной функцией DLM является обеспечение когерентного состояния дисковых кэшей для операций ввода/вывода операционной системы и прикладных программ. Следует, однако, отметить, что работа с DLM связана со значительными накладными расходами. Накладные расходы в среде VAX/VMS могут быть большими, требующими передачи до шести сообщений по шине CI для одной операции ввода/вывода и могут достигать величины 20% для каждого процессора в кластере.
Во всем мире насчитывалось более 20000 установок VAX-кластеров. Почти все из них построены с использованием шинного интерфейса CI.
Альтернативой VAX-кластерам стали так называемые UNIX-кластеры. Одно из наибольших их отличий связано с реализацией восстановления клиентов в случае отказа. В VAX-кластерах такое восстановление осуществляется средствами программного обеспечения самого VAX-кластера. В UNIX-кластерах эти возможности обычно реализуются отдельным уровнем программного обеспечения, называемым
монитором транзакций. В UNIX-кластерах мониторы транзакций, кроме того, используются также для целей балансировки нагрузки, в то время как VAX-кластеры имеют встроенную в программное обеспечение утилиту балансировки загрузки.
Компания IBM предложила несколько типов UNIX-кластеров на базе RS/6000, работающих под управлением программного продукта High-Availability Clustered Multiprocessor/6000 (HACMP/6000). В этих системах поддерживаются три режима автоматического восстановления системы после отказа:
Максимальное количество узлов в кластере равно восьми. В составе кластера есть узлы с симметричной многопроцессорной обработкой, построенные по технологии Data Crossbar Switch, обеспечивающей линейный рост производительности с увеличением числа процессоров. Кластеры RS/6000 строятся на базе локальных сетей Ethernet, Token Ring или FDDI и могут быть сконфигурированы различными способами с точки зрения обеспечения повышенной надежности:
Список литературы.
1. Агальцов, В.П. Базы данных. В 2-х т. Т. 2. Распределенные и удаленные базы данных: Учебник / В.П. Агальцов. – М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2021. – 272 c.
Кластеры обеспечивают высокий уровень доступности — в них отсутствуют единая операционная система и совместно используемая память, то есть нет проблемы когерентности кэшей. Кроме того, специальное программное обеспечение в каждом узле постоянно производит контроль работоспособности всех остальных узлов. Этот контроль основан на периодической рассылке каждым узлом сигнала «Я еще бодрствую». Если сигнал от некоторого узла не поступает, то такой узел считается вышедшим из строя; ему не дается возможность выполнять ввод/вывод, его диски и другие ресурсы (включая сетевые адреса) переназначаются другим узлам, а выполнявшиеся в вышедшем из строя узле программы перезапускаются в других узлах.
Производительность кластеров хорошо масштабируется при добавлении узлов. В кластере может выполняться несколько отдельных приложений, но для масштабирования отдельного приложения требуется, чтобы его части взаимодействовали путем обмена сообщениями. Нельзя, однако, не учитывать, что взаимодействия между узлами кластера занимают гораздо больше времени, чем в традиционных ВС.
Возможность практически неограниченного наращивания числа узлов и отсутствие единой операционной системы делают кластерные архитектуры исключительно хорошо масштабируемыми. Успешно используются системы с сотнями и тысячами узлов.
Топология кластеров
При создании кластеров с большим количеством узлов могут применяться самые разнообразные топологии. В данном разделе остановимся на топологиях, характерных для наиболее распространенных «малых» кластеров, состоящих из 2-4 узлов.
Топология кластерных пар
Топология кластерных пар используется при организации 2-х или 4-х узловых кластеров (рис. 2).
Рис. 2. Топология кластерных пар
Узлы группируются попарно. Дисковые массивы присоединяются к обоим узлам, входящим в состав пары, причем каждый узел пары имеет доступ ко всем дисковым массивам данной пары. Один из узлов пары используется как резервный для другого.
4-х узловая кластерная пара представляет собой простое расширение 2-х узловой топологии. Обе кластерные пары с точки зрения администрирования и настройки рассматриваются как единое целое.
Данная топология может быть применена для организации кластеров с высокой готовностью данных, но отказоустойчивость реализуется только в пределах пары, так как принадлежащие паре устройства хранения информации не имеют физического соединения с другой парой.
Топология используется при организации параллельной работы СУБД Informix XPS.
Топология N+1
Топология N+1 позволяет создавать кластеры из 2-, 3- и 4-х узлов (рис. 3).
Рис. 3. Топология N+1
Каждый дисковый массив подключаются только к двум узлам кластера. Дисковые массивы организованы по схеме RAID 1. Один сервер имеет соединение со всеми дисковыми массивами и служит в качестве резервного для всех остальных (основных или активных) узлов. Резервный сервер может использоваться для обеспечения высокой степени готовности в паре с любым из активных узлов.
Топология рекомендуется для организации кластеров высокой готовности. В тех конфигурациях, где имеется возможность выделить один узел для резервирования, эта топология позволяет уменьшить нагрузку на активные узлы и гарантировать, что нагрузка вышедшего из строя узла будет воспроизведена на резервном узле без потери производительности. Отказоустойчивость обеспечивается между любым из основных узлов и резервным узлом. В то же время топология не позволяет реализовать глобальную отказоустойчивость, поскольку основные узлы кластера и их системы хранения информации не связаны друг с другом.
Топология NN
Аналогично топологии N+1, топология NN (рис. 14.12) позволяет создавать кластеры из 2-, 3- и 4-х узлов, но в отличие от первой обладает большей гибкостью и масштабируемостью.
Рис. 4. Топология NN
Только в этой топологии все узлы кластера имеют доступ ко всем дисковым массивам, которые, в свою очередь, строятся по схеме RAID 1 (с дублированием). Масштабируемость топологии проявляется в простоте добавления к кластеру дополнительных узлов и дисковых массивов без изменения соединений в существующей системе.
Топология позволяет организовать каскадную систему отказоустойчивости, при которой обработка переносится с неисправного узла на резервный, а в случае его выхода из строя на следующий резервный узел и т.д. Кластеры с топологией NN обеспечивают поддержку приложения Oracle Parallel Server, требующего соединения всех узлов со всеми системами хранения информации. В целом топология обладает лучшей отказоустойчивостью и гибкостью по сравнению с другими топологиями.
Топология с полностью раздельным доступом
В топологии с полностью раздельным доступом(рис. 5) каждый дисковый массив соединяется только с одним узлом кластера.
Рис. 5. Топология с полностью раздельным доступом
Топология рекомендуется только для тех приложений, для которых характерна архитектура полностью раздельного доступа, например, для уже упоминавшейся СУБД Informix XPS.
VAX/VMS кластеры фирмы DEC
Компания DEC в 1983 году первой анонсировала концепцию кластерной системы, определив ее как группу объединенных между собой вычислительных машин, представляющих собой единый узел обработки информации. По существу VAX-кластер (рис. 6) представляет собой слабосвязанную многомашинную систему с общей внешней памятью, обеспечивающую единый механизм управления и администрирования. VAX-кластер обладает следующими свойствами.
-
Разделение ресурсов. Вычислительные машины VAX в кластере могут разделять доступ к общим ленточным и дисковым накопителям. Все машины в кластере могут обращаться к отдельным файлам данных как к локальным. -
Высокая готовность. Если происходит отказ в одном из узлов, задания пользователей автоматически могут быть перенесены на другой узел кластера. При наличии в системе нескольких контроллеров иерархической внешней памяти (HSC, Hierarchical Storage Controller) и отказе одного из них другие контроллеры HSC автоматически подхватывают его работу. -
Высокая пропускная способность. Приложения могут пользоваться возможностью параллельного выполнения заданий на нескольких машинах кластера. -
Удобство обслуживания системы. Общие базы данных могут обслуживаться с единственного места. Прикладные программы могут инсталлироваться только однажды на общих дисках кластера и разделяться между всеми узлами кластера. -
Расширяемость. Увеличение вычислительной мощности кластера достигается подключением к нему дополнительных ВМ типа VAX. Дополнительные накопители на магнитных дисках и магнитных лентах становятся доступными для всех ВМ, входящих в кластер.
Рис. 6..VAX/VMS-кластер
Работа VAX-кластера определяется двумя главными компонентами: высокоскоростным механизмом связи и системным программным обеспечением, которое обеспечивает клиентам прозрачный доступ к системному сервису. Физически связи внутри кластера реализуются с помощью трех различных шинных технологий с различными характеристиками производительности.
Шина связи компьютеров CI (Computer Interconnect) работает со скоростью 100 Мбит/с и используется для соединения компьютеров VAX и контроллеров HSC с помощью коммутатора Star Coupler. Каждая связь CI имеет двойные избыточные линии, две для передачи и две для приема. Линии функционируют по технологии CSMA, которая для устранения коллизий использует специфические для данного узла задержки. Максимальная длина связи CI составляет 45 метров. Звездообразный коммутатор Star Coupler может поддерживать подключение до 32 шин CI, каждая из которых предназначена для подсоединения компьютера VAX или контроллера HSC. Контроллер HSC представляет собой интеллектуальное устройство, которое управляет работой дисковых и ленточных накопителей.
В основе системного программного обеспечения рассматриваемой кластерной системы лежит распределенный менеджер блокировок (DLM, Distributed Lock Manager). Он гарантирует правильное взаимодействие процессоров друг с другом при обращениях к общим ресурсам, таким, например, как диски. Очень важной функцией DLM является обеспечение когерентного состояния дисковых кэшей для операций ввода/вывода операционной системы и прикладных программ. Следует, однако, отметить, что работа с DLM связана со значительными накладными расходами. Накладные расходы в среде VAX/VMS могут быть большими, требующими передачи до шести сообщений по шине CI для одной операции ввода/вывода и могут достигать величины 20% для каждого процессора в кластере.
Во всем мире насчитывалось более 20000 установок VAX-кластеров. Почти все из них построены с использованием шинного интерфейса CI.
UNIX-кластеры компании IBM
Альтернативой VAX-кластерам стали так называемые UNIX-кластеры. Одно из наибольших их отличий связано с реализацией восстановления клиентов в случае отказа. В VAX-кластерах такое восстановление осуществляется средствами программного обеспечения самого VAX-кластера. В UNIX-кластерах эти возможности обычно реализуются отдельным уровнем программного обеспечения, называемым
монитором транзакций. В UNIX-кластерах мониторы транзакций, кроме того, используются также для целей балансировки нагрузки, в то время как VAX-кластеры имеют встроенную в программное обеспечение утилиту балансировки загрузки.
Компания IBM предложила несколько типов UNIX-кластеров на базе RS/6000, работающих под управлением программного продукта High-Availability Clustered Multiprocessor/6000 (HACMP/6000). В этих системах поддерживаются три режима автоматического восстановления системы после отказа:
-
режим 1 — в конфигурации с двумя системами, одна из которых является основной, а другая находится в горячем резерве, в случае отказа обеспечивает автоматическое переключение с основной системы на резервную; -
режим 2 — в той же двухмашинной конфигурации позволяет резервному процессору обрабатывать некритичные приложения, выполнение которых в случае отказа основной системы можно либо прекратить совсем, либо продолжать их обработку в режиме деградации; -
режим 3 — можно действительно назвать кластерным решением, поскольку системы в этом режиме работают параллельно, разделяя доступ к логическим и физическим ресурсам пользуясь возможностями менеджера блокировок, входящего в состав HACMP/6000.
Максимальное количество узлов в кластере равно восьми. В составе кластера есть узлы с симметричной многопроцессорной обработкой, построенные по технологии Data Crossbar Switch, обеспечивающей линейный рост производительности с увеличением числа процессоров. Кластеры RS/6000 строятся на базе локальных сетей Ethernet, Token Ring или FDDI и могут быть сконфигурированы различными способами с точки зрения обеспечения повышенной надежности:
-
горячий резерв или простое переключение в случае отказа. В этом режиме активный узел выполняет прикладные задачи, а резервный может выполнять некритичные задачи, которые могут быть остановлены в случае необходимости переключения при отказе активного узла; -
симметричный резерв. Аналогичен горячему резерву, но роли главного и резервного узлов не фиксированы; -
взаимный подхват или режим с распределением нагрузки. В этом режиме каждый узел в кластере может «подхватывать» задачи, которые выполняются на любом другом узле кластера.
Список литературы.
1. Агальцов, В.П. Базы данных. В 2-х т. Т. 2. Распределенные и удаленные базы данных: Учебник / В.П. Агальцов. – М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2021. – 272 c.