Файл: Лабораторная работа 1 Установка и настройка кластера Hadoop на Ubuntu.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 01.12.2023
Просмотров: 72
Скачиваний: 6
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Лабораторная работа №1
Установка и настройка кластера Hadoop на Ubuntu
Рассмотрим установку Hadoop на Linux Ubuntu 20.04, а также настройку кластера. В нашем примере мы будем использовать 3 сервера:
haddop1, 192.168.1.15 (мастер).
haddop2, 192.168.1.20 (слейв).
haddop3, 192.168.1.25 (слейв).
Пошагово, мы выполним работы по предварительной настройке серверов, установке и конфигурирования Hadoop, а также созданию кластера.
Обновление пакетов
Как показывает практика, не обновленный список пакетов может привести к ошибкам при установке программного обеспечения.
Для обновления списка пакетов вводим команду:
apt update
Также, при желании, мы можем обновить установленные пакеты (особенно рекомендуется на чистых системах):
apt upgrade
Настройка брандмауэра
Для корректной работы кластера нам нужно открыть следующие порты:
iptables -I INPUT -p tcp --dport 9870 -j ACCEPT
iptables -I INPUT -p tcp --dport 8020 -j ACCEPT
iptables -I INPUT -p tcp --match multiport --dports 9866,9864,9867 -j ACCEPT
* где порт:
-
9870 — веб-интерфейс для управления.
-
8020 — RPC адрес для клиентских подключений.
-
9866 — DataNode (передача данных).
-
9864 — DataNode (http-сервис).
-
9867 — DataNode (IPC-сервис).
Для сохранения правил используем утилиту netfilter-persistent:
apt install iptables-persistent
netfilter-persistent save
Настройка hosts
Узлы нашего кластера должны уметь обращаться друг к другу по имени. В продуктивной среде для этого, обычно, используется DNS. Но если такой возможности нет, то необходимо на серверах добавить в файл hosts следующее:
vi /etc/hosts
#127.0.1.1 haddop1
192.168.1.15 haddop1
192.168.1.20 haddop2
192.168.1.25 haddop3
* в данном примере мы указываем соответствия IP-адресов и имен для нашего конкретного примера. Само собой, в вашем случае это будут другие данные.
** обратите внимание на закомментированную строку 127.0.1.1. Если этого не сделать, то сервер будет запускаться на локальном адресе 127.0.1.1 и вторичные серверы не смогут подключиться к мастеру.
Установка Java
Hadoop разработан на языке программирования Java, поэтому на наших серверах должна быть установлена данная платформа.
Выполняем команду:
apt install default-jdk
Готово. Смотрим версию установленной Java:
java -version
Мы должны увидеть что-то на подобие:
openjdk version "11.0.13" 2021-10-19
OpenJDK Runtime Environment (build 11.0.13+8-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.13+8-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
Установка Hadoop
Установка выполняется вручную ‑ необходимо скачать бинарник с сайта разработчика и разместить на сервере, создать файлы с переменными окружения и настроить автозапуск с помощью systemd. Данные действия выполняем на всех серверах. Также необходимо обеспечить возможность подключения по ssh ко всем серверам кластера.
Загрузка исходника
Переходим на страницу загрузки Hadoop и кликаем по ссылке для скачивания нужной версии программного обеспечения (в нашем примере, самой свежей):
Копируем ссылку на загрузку архива:
Используя ссылку, загружаем на наши серверы архив:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
Установка и настройка среды
Создадим каталог, в который поместим файлы приложения:
mkdir /usr/local/hadoop
Распаковываем содержимое загруженного архива в созданный каталог:
tar -zxf hadoop-*.tar.gz -C /usr/local/hadoop --strip-components 1
Создаем пользователя hadoop:
useradd hadoop -m
И зададим ему пароль:
passwd hadoop
Задаем в качестве владельца каталога hadoop созданного пользователя:
chown -R hadoop:hadoop /usr/local/hadoop
Создаем файл с профилем:
vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export YARN_HOME=$HADOOP_HOME
export PATH="$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin"
* в данном примере мы задаем системные переменные, требующиеся для работы hadoop:
-
HADOOP_HOME — путь, где находятся файлы hadoop.
-
HADOOP_HDFS_HOME — директория распределенной файловой системы HDFS.
-
HADOOP_MAPRED_HOME — необходима для возможности отправки задания MapReduce с помощью MapReduce v2 в YARN.
-
HADOOP_COMMON_HOME — путь хранения файлов для модуля common.
-
HADOOP_COMMON_LIB_NATIVE_DIR —месторазмещениябиблиотеки native-hadoop.
-
HADOOP_OPTS — дополнительные опции запуска.
-
YARN_HOME — путь размещения файлов модуля YARN.
-
PATH — дополняет общую переменную PATH, где хранятся пути хранения бинарников для запуска приложений.
Теперь откроем файл:
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Находим:
# export JAVA_HOME=
Меняем на:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
* мы прописали актуальный путь до файлов openjdk.
Проверка настройки среды
Заходим под пользователем hadoop:
su - hadoop
Попробуем выполнить команду:
$ env | grep -i -E "hadoop|yarn"
Мы должны увидеть следующее:
MAIL=/var/mail/hadoop
USER=hadoop
HADOOP_COMMON_HOME=/usr/local/hadoop
HOME=/home/hadoop
HADOOP_COMMON_LIB_NATIVE_DIR=/usr/local/hadoop/lib/native
LOGNAME=hadoop
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
YARN_HOME=/usr/local/hadoop
HADOOP_MAPRED_HOME=/usr/local/hadoop
HADOOP_HDFS_HOME=/usr/local/hadoop
HADOOP_HOME=/usr/local/hadoop
Теперь вводим:
$ hadoop version
Примерно, вывод команды будет таким:
Hadoop 3.3.1
Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2
Compiled by ubuntu on 2021-06-15T05:13Z
Compiled with protoc 3.7.1
From source with checksum 88a4ddb2299aca054416d6b7f81ca55
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.1.jar
Остаемся в системе под пользователем hadoop.
Создание сертификатов
Для работы hadoop нужен сертификат, так как внутренние обращения выполняются с помощью запросов ssh. Нам нужно сгенерировать его на одном из серверов и скопировать на остальные.
На мастер-сервере вводим команду, чтобы создать ключи:
$ ssh-keygen
* на все вопросы можно ответить по умолчанию, нажав Enter.
Копируем публичный ключ на локальный компьютер:
$ ssh-copy-id localhost
При первом обращении по SSH будет запрос на принятие сертификата:
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Система запросит ввести пароль для нашего пользователя hadoop. После успешного ввода, мы должны увидеть:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'localhost'"
and check to make sure that only the key(s) you wanted were added.
Теперь скопируем нужные ключи на остальные ноды кластера:
$ scp -r .ssh hadoop@haddop2:
$ scp -r .ssh hadoop@haddop3:
Лабораторная работа №1
Установка и настройка кластера Hadoop на Ubuntu
Рассмотрим установку Hadoop на Linux Ubuntu 20.04, а также настройку кластера. В нашем примере мы будем использовать 3 сервера:
haddop1, 192.168.1.15 (мастер).
haddop2, 192.168.1.20 (слейв).
haddop3, 192.168.1.25 (слейв).
Пошагово, мы выполним работы по предварительной настройке серверов, установке и конфигурирования Hadoop, а также созданию кластера.
Обновление пакетов
Как показывает практика, не обновленный список пакетов может привести к ошибкам при установке программного обеспечения.
Для обновления списка пакетов вводим команду:
apt update
Также, при желании, мы можем обновить установленные пакеты (особенно рекомендуется на чистых системах):
apt upgrade
Настройка брандмауэра
Для корректной работы кластера нам нужно открыть следующие порты:
iptables -I INPUT -p tcp --dport 9870 -j ACCEPT
iptables -I INPUT -p tcp --dport 8020 -j ACCEPT
iptables -I INPUT -p tcp --match multiport --dports 9866,9864,9867 -j ACCEPT
* где порт:
-
9870 — веб-интерфейс для управления. -
8020 — RPC адрес для клиентских подключений. -
9866 — DataNode (передача данных). -
9864 — DataNode (http-сервис). -
9867 — DataNode (IPC-сервис).
Для сохранения правил используем утилиту netfilter-persistent:
apt install iptables-persistent
netfilter-persistent save
Настройка hosts
Узлы нашего кластера должны уметь обращаться друг к другу по имени. В продуктивной среде для этого, обычно, используется DNS. Но если такой возможности нет, то необходимо на серверах добавить в файл hosts следующее:
vi /etc/hosts
#127.0.1.1 haddop1
192.168.1.15 haddop1
192.168.1.20 haddop2
192.168.1.25 haddop3
* в данном примере мы указываем соответствия IP-адресов и имен для нашего конкретного примера. Само собой, в вашем случае это будут другие данные.
** обратите внимание на закомментированную строку 127.0.1.1. Если этого не сделать, то сервер будет запускаться на локальном адресе 127.0.1.1 и вторичные серверы не смогут подключиться к мастеру.
Установка Java
Hadoop разработан на языке программирования Java, поэтому на наших серверах должна быть установлена данная платформа.
Выполняем команду:
apt install default-jdk
Готово. Смотрим версию установленной Java:
java -version
Мы должны увидеть что-то на подобие:
openjdk version "11.0.13" 2021-10-19
OpenJDK Runtime Environment (build 11.0.13+8-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.13+8-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
Установка Hadoop
Установка выполняется вручную ‑ необходимо скачать бинарник с сайта разработчика и разместить на сервере, создать файлы с переменными окружения и настроить автозапуск с помощью systemd. Данные действия выполняем на всех серверах. Также необходимо обеспечить возможность подключения по ssh ко всем серверам кластера.
Загрузка исходника
Переходим на страницу загрузки Hadoop и кликаем по ссылке для скачивания нужной версии программного обеспечения (в нашем примере, самой свежей):
Копируем ссылку на загрузку архива:
Используя ссылку, загружаем на наши серверы архив:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
Установка и настройка среды
Создадим каталог, в который поместим файлы приложения:
mkdir /usr/local/hadoop
Распаковываем содержимое загруженного архива в созданный каталог:
tar -zxf hadoop-*.tar.gz -C /usr/local/hadoop --strip-components 1
Создаем пользователя hadoop:
useradd hadoop -m
И зададим ему пароль:
passwd hadoop
Задаем в качестве владельца каталога hadoop созданного пользователя:
chown -R hadoop:hadoop /usr/local/hadoop
Создаем файл с профилем:
vi /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
export YARN_HOME=$HADOOP_HOME
export PATH="$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin"
* в данном примере мы задаем системные переменные, требующиеся для работы hadoop:
-
HADOOP_HOME — путь, где находятся файлы hadoop. -
HADOOP_HDFS_HOME — директория распределенной файловой системы HDFS. -
HADOOP_MAPRED_HOME — необходима для возможности отправки задания MapReduce с помощью MapReduce v2 в YARN. -
HADOOP_COMMON_HOME — путь хранения файлов для модуля common. -
HADOOP_COMMON_LIB_NATIVE_DIR —месторазмещениябиблиотеки native-hadoop. -
HADOOP_OPTS — дополнительные опции запуска. -
YARN_HOME — путь размещения файлов модуля YARN. -
PATH — дополняет общую переменную PATH, где хранятся пути хранения бинарников для запуска приложений.
Теперь откроем файл:
vi /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Находим:
# export JAVA_HOME=
Меняем на:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
* мы прописали актуальный путь до файлов openjdk.
Проверка настройки среды
Заходим под пользователем hadoop:
su - hadoop
Попробуем выполнить команду:
$ env | grep -i -E "hadoop|yarn"
Мы должны увидеть следующее:
MAIL=/var/mail/hadoop
USER=hadoop
HADOOP_COMMON_HOME=/usr/local/hadoop
HOME=/home/hadoop
HADOOP_COMMON_LIB_NATIVE_DIR=/usr/local/hadoop/lib/native
LOGNAME=hadoop
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
YARN_HOME=/usr/local/hadoop
HADOOP_MAPRED_HOME=/usr/local/hadoop
HADOOP_HDFS_HOME=/usr/local/hadoop
HADOOP_HOME=/usr/local/hadoop
Теперь вводим:
$ hadoop version
Примерно, вывод команды будет таким:
Hadoop 3.3.1
Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2
Compiled by ubuntu on 2021-06-15T05:13Z
Compiled with protoc 3.7.1
From source with checksum 88a4ddb2299aca054416d6b7f81ca55
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.1.jar
Остаемся в системе под пользователем hadoop.
Создание сертификатов
Для работы hadoop нужен сертификат, так как внутренние обращения выполняются с помощью запросов ssh. Нам нужно сгенерировать его на одном из серверов и скопировать на остальные.
На мастер-сервере вводим команду, чтобы создать ключи:
$ ssh-keygen
* на все вопросы можно ответить по умолчанию, нажав Enter.
Копируем публичный ключ на локальный компьютер:
$ ssh-copy-id localhost
При первом обращении по SSH будет запрос на принятие сертификата:
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Система запросит ввести пароль для нашего пользователя hadoop. После успешного ввода, мы должны увидеть:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'localhost'"
and check to make sure that only the key(s) you wanted were added.
Теперь скопируем нужные ключи на остальные ноды кластера:
$ scp -r .ssh hadoop@haddop2:
* в данном примере мы скопируем каталог .ssh на серверы haddop2 и haddop3, которые в нашем примере используются в качестве слейвов.
Проверим вход в систему по ssh на все серверы ‑ мы должны подключиться без запроса пароля:
$ ssh localhost
После отключаемся:
$ exit
B также подключаемся другим двум серверам:
$ ssh haddop2
$ exit
$ ssh haddop3
$ exit
Установка и настройка Hadoop завершена. Возвращаемся в консоль первичного пользователя:
$ exit
Настройка и запуск
Отредактируем некоторые конфигурационные файлы (на всех узлах кластера), выполним пробный запуск и настроим сервис для автозапуска.
Открываем файл для общих настроек:
vi /usr/local/hadoop/etc/hadoop/core-site.xml
Приведем его к виду:
...
* где fs.default.name указывает на узел и порт обращения к внутренней файловой системе. В нашем примере на мастер-сервер (localhost) порту 9000. Данная настройка должна быть такой на всех нодах.
Редактируем файл с настройками файловой системы HDFS:
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
В итоге должно получиться:
...
* где:
-
dfs.replication — количество реплик. Не может быть больше узлов кластера. -
dfs.name.dir — путь хранения таблицы имен fsimage. Можно перечи -
dfs.data.dir — каталог для хранения блоков файловой системой HDFS.
Открываем для редактирования файл для настройки MapReduce:
vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
Задаем следующие параметры:
...
/configuration>
* где mapreduce.framework.name ‑ фреймворк для управления кластером.
Открываем файл для настройки YARN:
vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
Приводим его к виду:
...
* где yarn.nodemanager.aux-services перечисляет вспомогательные классы обслуживания. По документации рекомендуют использовать mapreduce_shuffle.
Создаем каталоги, которые мы указали для использования HDFS:
mkdir -p /hadoop/hdfs/{namenode,datanode}
Для каталога /hadoop выставим в качестве владельца созданного пользователя hadoop:
chown -R hadoop:hadoop /hadoop
Наши серверы настроены.
Открываем файл с узлами кластера:
vi /usr/local/hadoop/etc/hadoop/workers
И перечислим все slave-узлы:
haddop2
haddop3
Можно запускать кластер.
Проверка запуска
На мастер-сервере заходим под пользователем hadoop:
su - hadoop
Создаем файловую систему:
$ /usr/local/hadoop/bin/hdfs namenode -format
Для запуска кластера выполняем следующие команды:
$ /usr/local/hadoop/sbin/start-dfs.sh
$ /usr/local/hadoop/sbin/start-yarn.sh
Ждем еще немного (около 10 секунд) для окончательной загрузки java-приложения. После открываем в браузере адрес http://
Мы должны увидеть что-то на подобие:
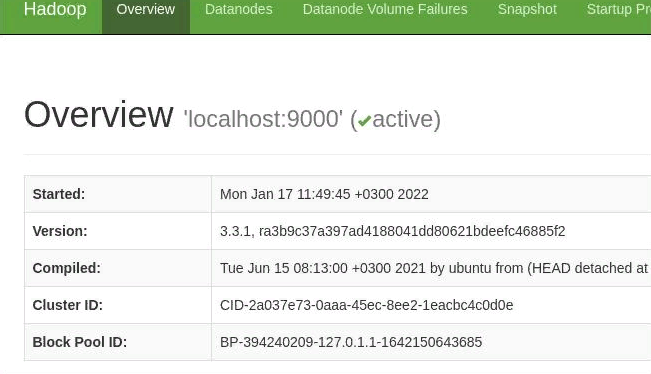
А на вкладке Datanodes мы должны увидеть все наши вторичные ноды.
Кластер работает.
Автозапуск сервиса
И последнее ‑ настроим запуск hadoop в качестве сервиса. Это делаем на мастер-сервере.
Создаем файл:
vi /etc/systemd/system/hadoop.service
[Unit]
Description=Hdfs service
After=network.target
[Service]
Type=forking
User=hadoop
Group=hadoop
ExecStart=/usr/local/hadoop/sbin/start-all.sh
ExecStop=/usr/local/hadoop/sbin/stop-all.sh
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
Перечитываем конфигурацию systemd:
systemctl daemon-reload
Разрешаем автозапуск:
systemctl enable hadoop
Для проверки можно перезагрузить сервер.