Файл: Введение анализ проблемы и ее современного состояния.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 01.12.2023
Просмотров: 40
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Тематическая модель описывается двумя распределениями:
(????(????|????) (вероятность того, что тема t породит токен w) и ????(????|????) (пропорция темы t в документе d). Часто используется обозначения φ???????? = ????(????|????), θ???????? = ????(????|????). Два искомых распределения можно тогда представить в виде стохастических матриц Φ и Θ. С точки зрения тематического моделирования, корпус документов представляет собой последовательность трёхэлементных кортежей Ω???? = {︀ (???????? ,???????? ,????????) ⃒ ⃒ ???? = 1, . . . ,????}︀ . Токены wi и документы di являются наблюдаемыми переменными, а темы ti являются скрытыми переменными. Тематическое моделирование основано на формализации двух наблюдений лингвистической природы. 1. Существуют естественные кластеры слов, употребляемых вместе (темы). 2. В разных документах эти темы встречаются с разной частотой. Главное допущение, лежащее в основе тематического моделирования, проще всего сформулировать через процесс генерации документов. Тематическая модель «считает», что каждый документ порождается следующим образом:
1. Для каждой словопозиции i автор документа di выбирает случайную тему t из распределения ????(????|????????)
2. Из распределения ????(di|t) выбирается случайное слово wi Кажущаясся нереалистичность этого допущения на практике смягчается тем, что порядок слов в документе не важен для определения его тематики. Модель оперирует только с величинами ndw, обозначающими число вхождений слова w в документ d. Это предположение, называемое гипотезой мешка слов, сильно упрощает математический аппарат и поэтому часто используется в анализе текстов. Ещё одно важное допущение, связанное с постановкой задачи, называется гипотезой условной независимости. Частота токена зависит только от его темы, но не зависит от документа:
????(????|????,????) = ????(????|????). (1.1)
Тема может описывать множество терминов из какой-либо области: например, тема «театр» включает в себя слова «зритель», «опера», «премьера» и не включает в себя слова «космонавтика», «эмпиризм», «кредит» или «гемоглобин». Однако темы могут иметь и более гибкую природу. Например, при анализе художественных текстов можно выделить темы, связанные с определённым персонажем; при анализе обращений в техподдержку можно выделить темы, связанные с конкретными проблемами; в анализе тональности текста (sentiment analysis) можно выделять темы, связанные с определёнными эмоциями. Несмотря на то что тематическое моделирование предназначалось в первую очередь для поиска скрытых тем в текстовых документах, существуют и более экзотические сферы его применения: – Анализ видеозаписей. Видеозапись является документом, в качестве токенов выступают признаки на его кадрах, а в качестве тем – события; например, проезд автомобиля через перекрёсток [28]. – Анализ изображений. Документ — это
одно изображение, его токены — признаковое описание этого изображения, темы — находящиесся на изображении объекты [29]. – Судовые журналы кораблей. Документ — это одно путешествие, токен — координаты корабля в определённый день, а темы — различные «миссии», такие как перевозка грузов в определённый порт или китобойный промысел [16]. – Банковские транзакции. Документ — история покупок одного клиента, токен — код продавца, темы — типы потребительского поведения людей (например, «ремонт квартиры») [24]. 16 – Анализ электрокардиосигналов. Документ — одна кардиограмма, токены — кодограммы (полученные на основе амплитуд и интервалов), темы — отдельные заболевания [30] – Анализ музыкальных произведений. Документ — одно произведение, токены — последовательность тональных высотных классов (tonal pitchclasses), темы — тональные профили [31] Для общности изложения далее мы будем использовать понятие токена вместо понятий термина или слова.
Приложения тематического моделирования в различных областях наталкиваются на проблемы плохой интерпретируемости тем, дублирующих, «мусорных» и вводящих в заблуждение тем, неустойчивости результатов моделирования. Темы должна удовлетворять одновременно многим критериям, что вызывает необходимость как измерения, так и улучшения качества тематических моделей одновременно по множеству критериев.
Неинтерпретируемые темы Не все построенные темы можно однозначно проинтерпретировать. Это ожидаемо: коллекции реальных текстов содержат в себе аномальные документы, неинформативные слова (к числу которых относятся как стоп-слова или слова общей лексики, так и слова, широко распространённые в конкретном корпусе), опечатки и другие артефакты. При этом тематическая модель должна успешно описывать весь корпус, и поэтому таким артефактам нужно найти место. Тем не менее на практике важно минимизировать количество неинтерпретируемых тем и постараться сделать так, чтобы «хорошие» темы не перемешивались с «плохими» и не засорялись «мусорными словами».
В работе [74] были отмечены некоторые частые проблемы, связанные с темами низкого качества.
1. Смешанные темы (mixed topics): набор слов, которые трудно проинтерпретировать вместе, но который содержит хорошо интерпретируемые подмножества слов. Можно сказать, что смешанные темы — это несколько «хороших» тем, которые слиплись вместе.
2. Темы-химеры (chained topics): смешанные темы, объединённые общими словами. В качестве примера такой темы можно привести тему из слов «старение - человек - глобин». Пары «старение человек» и «глобин человек» имеют смысл, но пару «старение глобин» объединяет лишь то, что оба слова часто встречаются рядом со словом «человек». Темы-химеры часто возникают из-за слов-омонимов. Например, тема «reagan, roosevelt, clinton, lincoln, honda, chevrolet, bmw» объединяет в себе имена президентов США и марки автомобилей, слипшихся из-за неоднозначного слова «Линкольн») или из-за иерархических отношений между словами (общее понятие «налог» включает в себя «налог на автомобиль» и «налог на прибыль», из-за чего может появиться тема, содержащая в себе редкое сочетание «автомобиль прибыль».
3. Темы с посторонними словами (intruded topics): в целом осмысленные темы, внутри которых есть слова, не имеющие ничего общего с остальными словами.
4. Случайные темы: набор слов, не имеющих отношения друг к другу.
5. Несбалансированные по охвату темы: содержат внутри себя термины как широкой направленности, так и крайне специфические. Например, «сигнальная трансдукция» (общее название передачи сигнала в молекулярной биологии) и «сигнальный путь Notch» (один из многих сигнальных путей, которые, в свою очередь, являются одним из аспектов сигнальной трансдукции). Отметим, что многие из перечисленных здесь пунктов могут делать потенциально информативные темы некачественными. Этот список проблем далее был уточнён и переработан в работе [18], в которой дополнительно описываются темы с излишней общностью (состоящие из слишком частых и/или неспецифичных токенов), темы с избыточной специфичностью (состоящие из слишком редких и/или специфичных токенов), идентичные темы и темы, «испорченные» неполным списком стоп-слов. Другой класс явных проблем можно определить через расстояние до известных «мусорных» тем: D-Background, W-Vacuous, W-Uniform, среднее геометрическое, равномерное распределение ????(????); или по другим мерам качества (более подробно эти меры качества изложены в следующей главе). Несмотря на то что суммарное качество для модели хорошо коррелирует с общей интерпретируемостью, разбиение мер качества по отдельным темам не всегда коррелирует с экспертной оценкой интерпретируемости индивидуальных тем. В ряде случаев экстремальные по каким-либо мерам качества темы (то есть как «самые хорошие», так и «самые плохие») являются неинтерпретируемыми или низкокачественными с точки зрения экспертов. В противовес явным проблемам, изложенным выше, работа [16] предостерегает исследователей от ряда возможных неявных проблем: «Упрощение тематических моделей для ученых-гуманитариев, которые не будут (и не должны) изучать лежащие в их основе алгоритмы, создаёт огромный потенциал для необоснованных — или даже вводящих в заблуждение — “инсайтов”». Примером такого проблематичного применения может служить исследователь, изучающий график зависимости вероятности темы от времени и рассматривающий одну тему отдельно от всех остальных. Взлёты и падения этой темы он интерпретирует в терминах изменения частоты понятия, характеризуемого её множеством из 10 верхних (наиболее частотных, «топовых», top-10) слов. Автор работы призывает этого исследователя к осторожности и обосновывает свой тезис рядом демонстраций. Первая демонстрация изучает роль верхних токенов в описании темы. Для этого тематическое моделирование применяется в экзотической области анализа географических данных: роль корпуса документов играют судовые журналы, токены которых — координаты корабля в один из дней его путешествия. Главной особенностью этого эксперимента является возможность визуализации всего распределения целиком — задача, которая, как правило, нереалистична в большинстве практических приложений. Автор демонстрирует нерепрезентативность верхних токенов при помощи карты Земли с нанесёнными на неё точками (визуализация заданной темы состоит из линий, соответствующих документам/путешествиям, и из точек, соответствующих верхним токенам/самым частым местоположениям). В большинстве случаев видно, что верхние токены дают очень плохое представление о теме; большинство верхних токенов расположено на границах маршрута и не несёт никакой информации о его форме. Вторая демонстрация проверяет темы на однородность по времени. Коллекция статей журнала Proceedings of the Modern Language Association растянута по времени с 1889 года по 2006 год. Это даёт возможность «разбить построенную тему на две части»: отметить все отнесённые к ней слова во всех документах, затем поделить документы на две хронологические группы (с 1889 по 1959 год и с 1959 по 2006 год) и вычислить частоты этих слов отдельно внутри каждой группы. Полученные таким образом пары списков верхних слов можно сравнить. Около четверти всех тем имеет существенные различия и может иметь две несовместимые интерпретации для этих двух временных периодов. На
основании этих рассуждений автор заключает, что для популяризации тематического моделирования среди учёных-гуманитариев требуются средства визуализации, выходящие за рамки списка верхних слов, а также что инструментарий тематического моделирования должен быть обогащён множеством автоматических проверок. Сформированная в работе критика остаётся актуальной и в настоящее время [15]. Различные реализации тематических моделей могут использовать стохастические элементы в своей инициализации и обучении. Многопоточные реализации алгоритмов обучения могут быть подвержены состоянию гонки (race condition), что делает результат обучения недетерминированным даже в условиях переиспользования одной и той же фиксированной последовательности случайных чисел. Также известно, что многие реализации тематического моделирования неустойчивы относительно порядка документов в корпусе [19]. Более половины из 57 рассмотренных в работе [19] статей в том или ином виде упоминает проблему неустойчивости латентного размещения Дирихле. Это проблематично по ряду причин. Например, затрудняет применение тематических моделей для анализа того, как тематики корпуса эволюционируют во времени или при добавлении новых документов [75]. Если тематическая модель используется для принятия каких-то решений, то неустойчивость может привести к ошибочным выводам, основанным не на объективной структуре корпуса, а на случайных шумоподобных эффектах [17]. Это может ввести пользователя в заблуждение и понизить эффективность других автоматических классификаторов, использующих выход тематической модели как обучающую выборку или дополнительные признаки [19].
2. Анализ методов в области тематического моделирования
Наиболее популярные в настоящий момент методы тематического моделирования можно разделить на две основных группы — алгебраические и вероятностные (генеративные) [2;4]. К алгебраическим моделям относятся стандартная векторная модель текста VSM (Vector Space Model) и латентно-семантический анализ LSA (Latent Semantic Analysis), а среди вероятностных наиболее популярными являются вероятностный латентно-семантический анализ pLSA (probabilistic LSA) и латентное размещение Дирихле LDA (Latent Dirichlet Allocation). Далее приведен краткий анализ некоторых методов. Векторная модель текстов — это способ представления коллекции документов в виде векторов из общего для всей коллекции векторного пространства. Данная модель используется для решения множества задач быстрого анализа документов, а также для составления таблиц поиска, классификации и кластеризации, и выступает как основа для множества других алгоритмов [2]. В данной модели, документ рассматривается как неупорядоченное множество термов — слов и дополнительных элементов, из которых состоит текст, исключая знаки препинания. Для каждого документа строится матрица терм-документ, где строка — это уникальное слово, а столбец — документ. Значением ячейки данной матрицы является вес данного слова в документе, способ вычисления которого может изменяться в зависимости от алгоритма. Данная модель достаточно популярна для решения задач сравнения текстов между собой, однако в изначальном варианте работает недостаточно быстро для больших объемов документов, а также занимает достаточно много памяти. Развитием данного метода является латентно-семантический анализ [2]. Латентно семантический анализ (ЛСА, LSA) — это статистический метод обработки текстовой информации на естественном языке, позволяющий определить взаимосвязь между коллекциями документов и терминами, в них встречающимися. В основе данного метода лежит принцип факторного анализа, в частности выявление латентных связей изучаемых явлений и объектов. При классификации и кластеризации документов, данный метод позволяет извлечь контекстно-зависимые значения лексических единиц [2]. Основной алгоритм данного метода можно разделить на четыре шага: предобработку, нахождение весов слов любым методом, например, с помощью алгоритма tf-idf, построение весовой матрицы, разложение матрицы методом сингулярного разложения (англ. singular value decomposition, SVD). Результатом работы алгоритма будет являться матрица, визуализация которой позволит отразить общую семантическую близость документов друг к другу. Основными достоинствами данного метода можно считать высокое качество определения тематик в случае, если корпус текстов достаточно большой, а также возможность нахождения неочевидных семантических зависимостей между словами. К недостаткам данного алгоритма относятся высокая вычислительная сложность и низкая скорость работы, требующая повторного вычисления всех метрик для всего корпуса в случае добавления нового документа, а также высокие требования к корпусу, который должен состоять из множества разнообразных по тематикам текстов. Вероятностный латентно-семантический анализ — это статистический метод анализа корреляций двух типов данных. В общем смысле, данный метод является развитием латентно-семантического анализа, однако в отличие от своего предшественника, который по своей сути являлся алгоритмом построения векторного представления с последующим снижением его размерности, вероятностной латентно-семантический анализ основан на смешанном разложении и использовании вероятностной модели, что позволяет более качественно определять возможные тематики документов [4]. К достоинствам данной модели относительно алгебраических можно отнести возможность нахождения вероятности отношения каждого документа к каждой из представленных тем, с последующей группировкой, что является достаточно трудоемкой задачей для алгоритма LSA. Недостатками данной модели являются те же недостатки, присущие и LSA, к которым относится необходимость перестройки всех модели в случае добавления нового документа, а также линейная зависимость количества параметров от количества документов. Латентное размещение Дирихле — применяемая в информационном поиске порождающая модель, позволяющая объяснить результаты наблюдений с помощью неявных (латентных) групп. Данная модель является расширением модели pLSA, и устраняет основные ее недостатки путем использования распределения Дирихле в качестве априори распределения, в результате чего набор тематик получается более конкретный и четкий [1]. Данная модель позволяет уйти от недостатков pLSA, таких как «переобучаемость» и отсутствие закономерности при генерации документов из набора полученных тем, что значительно улучшает итоговую выборку [2].
Скрытое размещение Дирихле (Latent Dirichlet Allocation, LDA) — генеративная графическая вероятностная модель, предложенная Дэвидом Блеем и соавторами в 2003 году [9]. Процесс генерации документа похож на генеративный процесс в PLSI. Каждый документ генерируется независимо: 1. Случайно выбрать для документа его распределение по темам θd
2. Для каждого слова в документе: a. Случайно выбрать тему из распределения θd, полученного на 1- м шаге b. Случайно выбрать слово из распределения слов в выбранной теме φt Схема модели скрытого размещения Дирихле изображена на рис. 1.
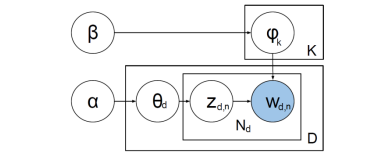
Рис. 1. Графическое представление модели скрытого размещения Дирихле.
Имеется набор из D документов. Каждый документ состоит из Nd слов, wdn соответствует наблюдаемым переменным — словам в документе. Это единственные наблюдаемые переменные в модели, остальные переменные — скрытые. Переменная zdn принимает значение темы, выбранной на шаге 2а для слова wdn. Для каждого документа d переменная θd представляет собой распределение тем в этом документе. В классической модели LDA количество тем фиксировано изначально и задаётся в явном виде параметром K. φk — распределение слов в теме k. Можно подобрать оптимальное значение K, варьируя его и измеряя способность модели предсказывать неизвестные данные, например, документы из тестовой выборки. Однако для того чтобы определять оптимальное количество тем в документе автоматически, были предложены более совершенные способы. Из Байесовской теории вероятностей известно, что распределение Дирихле является сопряжённым априорным к мультиномиальному распределению, которое обычно используется для моделирования текстов. Знание сопряжённых семейств распределений существенно упрощает вычисление апостериорных вероятностей при оценке параметров модели.
Предложеные подходы, позволяющие восстановить оптимальные значения гиперпараметров модели по обучающей выборке [10, 24]. На практике, как правило, используются значения, наиболее характерные для конкретных данных. К примеру, значение параметра, близкое к нулю, позволяет после оценивания параметров модели получить мультиномиальное распределение, в котором в котором большая часть плотности вероятности сосредоточена на небольшом наборе значений. Это хорошо соотносится со степенным распределением, которое часто наблюдается в текстах на естественном языке. В результате рассмотрения некоторых основных методов тематического моделирования можно прийти к выводу, что методы, основанные на вероятностных моделях наилучшим образом пригодны для решения поставленной задачи, однако требуют высоких вычислительных затрат при реализации в исходном виде. Метод LDA является наиболее сложным, и при этом позволяет достичь наилучших результатов, и избежать основных недостатков обычного pLSA.