Файл: Введение анализ проблемы и ее современного состояния.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 01.12.2023
Просмотров: 43
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
1. 3. Анализ существующих программных решений
Тематическое моделирование также применяется для анализа программных артефактов [20; 59]. Два самых популярных приложения охватывают около половины всех работ в этой области [20]. Первое из них — восстановление прослеживаемости (traceability link recovery), предназначенное для автоматического выявления связей между парами разнородных программных артефактов, таких как документы с исходным кодом и документы с требованиями [60]. Возможность ответить на вопрос «Какой файл (какие файлы) с исходным кодом реализует требование (функционал) X?» важна как для разработчиков, так и для заказчика. Близкой является задача локализации ошибок (bug localization), при которой ищется связь между баг-репортами и исходным кодом. Второе приложение — локализация функционала (concept location/feature location), предназначенная для идентификации кусков исходного кода, связанных с реализацией данного функционала программной системы [61]. Здесь, в отличие от восстановления прослеживаемости, от модели требуется построить связи между однородными программными артефактами (т.е. между исходными кодами, 22 лежащими в одном и том же репозитории). Эта задача в первую очередь актуальна для разработчиков, желающих отладить или улучшить данную функцию. Также стоит отметить: кластеризацию и визуализацию кода (Source Code Comprehension) для помощи в понимании и ориентировании в неструктурированном массиве текстов, основой которого служат идентификаторы переменных и комментарии; автоматическую разметку программных артефактов (software artifact labeling), предназначенную для характеризации большого документа коротким множеством ключевых слов [62]; прогнозирование возможных дефектов (Software Defects Prediction) посредством анализа исходников или логов выполнения; помощь в устранении дефектов посредством статистической отладки и анализа причин (Statistical Debugging и Root Cause Analysis), включающую в себя интеллектуальную фильтрацию логов исполнения. К прочим применениям можно отнести анализ истории изменений (Software History Comprehension), маршрутизацию задач к наиболее подходящему разработчику (Developer Recommendation/Bug Triaging), помощь в рефакторинге, приоритизацию исполнения тестовых кейсов, измерение дополнительных мер качества и так далее [20; 59]. 1.4.2 Разведочный информационный поиск Разведочный поиск включает в себя большой класс задач, связанных с систематизацией информации, суммаризацией текстов, переработкой знаний. Разведочный поиск — это итерационный процесс, в котором пользователь несколько раз переформулирует свой запрос с целью разобраться в новой для себя предметной области. Тематические модели оказываются наиболее актуальными для обработки длинных или сложных поисковых запросов, которые трудно или невозможно сформулировать в виде короткого списка ключевых слов (в том числе и для поиска документов, семантически близких к данному). В недавних работах [11; 63] показано, что аддитивно регуляризованные тематические модели по
качеству поиска превосходят как асессоров, так и конкурирующие модели.
2. Концептуальные положения и формулирование требований к программному решению по реализации тематического моделирования
2.1. Формальная постановка задачи и структура ее решения
В предыдущей главе было описано, для каких целей исследователи применяют тематические модели. Математический аппарат тематического моделирования всё чаще используется для того, чтобы сделать какие-либо выводы, рассмотрев темы сами по себе. Строго говоря, это не является использованием тематического моделирования по прямому назначению., поскольку изначально тематическое моделирование было всего лишь промежуточным шагом для последующей машинной обработки.
Главным приложением семантической индексации был информационный поиск:
- показ пользователю документа, наиболее релевантного его запросу, либо поиск документов, похожих на данный. В ранних работах, посвящённых тематическому моделированию, вопрос содержательной интерпретации тем не ставился.
Главными критериями качества были либо основанные на правдоподобии метрики (такие как перплексия на обучающей или проверочной выборке), либо метрики, основанные на внешней задаче (точность нахождения документа в информационном поиске; качество классификации документа по его тематическому векторному представлению.
Как правило, исследователи изучали несколько наиболее частотных токенов
из каждой темы (.верхние 10 токенов., 10 top-tokens), но это было лишь способом убедиться в общей адекватности модели; никаких строго сформулированных требований к семантической состоятельности тем в этот процесс не закладывалось.
Первая работа, в которой был поднят вопрос изучения внутренней структуры тематических моделей [1], появилась лишь в 2009 году. В ней приглашённые эксперты различными способами оценивали 10 верхних слов каждой темы, а также соответствие документа и тем, которые приписывает ему модель.
Одним из важных результатов этой работы оказалось то, что перплексия отрицательно коррелирует с оценками экспертов. В частности, обнаружилось что Correlated Topic Model [77], традиционно считавшаяся лучшей моделью с точки зрения перплексии, предсказаний и правдоподобия, показывает наихудшую интерпретируемость по сравнению с остальными моделями.
Это поставило перед сообществом новую задачу: найти критерии для
автоматического оценивания интерпретируемости тем без участия экспертов.
2.2. Постановка задачи тематического моделирования
постановку задачи представляет контекстная диаграмма IDEF0 (рис.4). На вход подаются тексты отзывов, на выходе – оценки тональности по каждой аспектной категории.
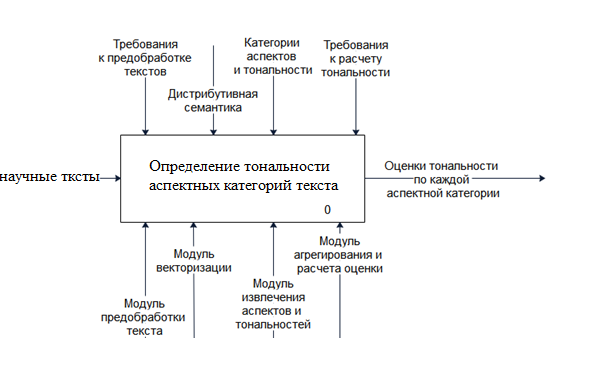
Рисунок 2.1 Постановка задачи
2.2.1. Структура решения задачи
Декомпозиция контекстной диаграммы определяет подзадачи системы (рис. 3). Всего выделены четыре подзадачи из верхнего уровня: предварительная обработка текстов, создание векторного представления слов, извлечения аспектов и тональностей и расчет оценок тональностей.
В первой подзадаче на вход поступают научные тексты , проводится их предварительная обработка путем удаления стоп-слов, удаления знаков пунктуации и приведение в нормальную форму. В качестве управления выступают требования к предобработке текста, в качестве механизма – модуль предобработки.
Создание векторного представления слов создает представление слов, полученных с предыдущей задачи, выход подзадачи является входом для задачи извлечения аспектов и тональностей, выполняет задачу соответствующий модуль ПО, в качестве управления используется дистрибутивная семантика.
На последнем этапе полученные множества аспектов и тональностей объединяются, и вычисляется оценки тональности по каждому отзыву, а затем общие оценки тональности для каждой категории на уровне вуза. В управлении находятся требования к расчету тональности, в механизмах – методы статистики.
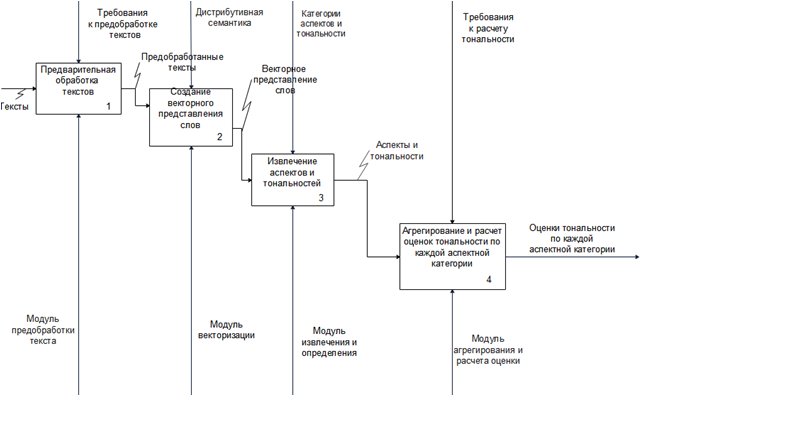
Рисунок 2.2.– Структура решения задачи
3.2. Концептуальные положения реализации тематического моделирования
Предлагаемое программное решение для достижения цели должно выполнять ряд последовательных задач (рис. 3):
-
осуществление сбора данных; -
выполнение предобработки данных; -
извлечение аспектных терминов и определение тональностей; -
агрегирование извлеченных аспектных терминов и тональностей; -
производить расчет оценки тональности по каждой категории; -
выдавать полученный результат в удобном виде.
Сбор данных должен производиться путем парсинга с сайтов в сети Интернет, затем собранные данные должны быть предобработаны, путем использования методов предобработки: удаления стоп-слов, удаление знаков пунктуации, представления в нормальной форме. После чего и представлены в виде векторного представления слов для последующей обработки методами машинного обучения, планируется использование нейронной сети в качестве модели. На выходе этапа «Извлечение аспектных терминов и определение тональности» будет множество аспектных терминов и множество соответствующих им тональностей, которые на этапе «Агрегирование аспектов и тональностей» объединяются в пары аспектная категория – тональность. Расчет общей оценки по аспектным категориям проводится с использованием соответствующего разработанного метода. На последнем этапе данные представляются пользователю в удобном визуальном представлении. В качестве модели выступает рекуррентная нейронная сеть, принцип – принцип работы нейросети. Ограничения основаны на типах входных данных и на основе имеющегося аппаратного обеспечения.
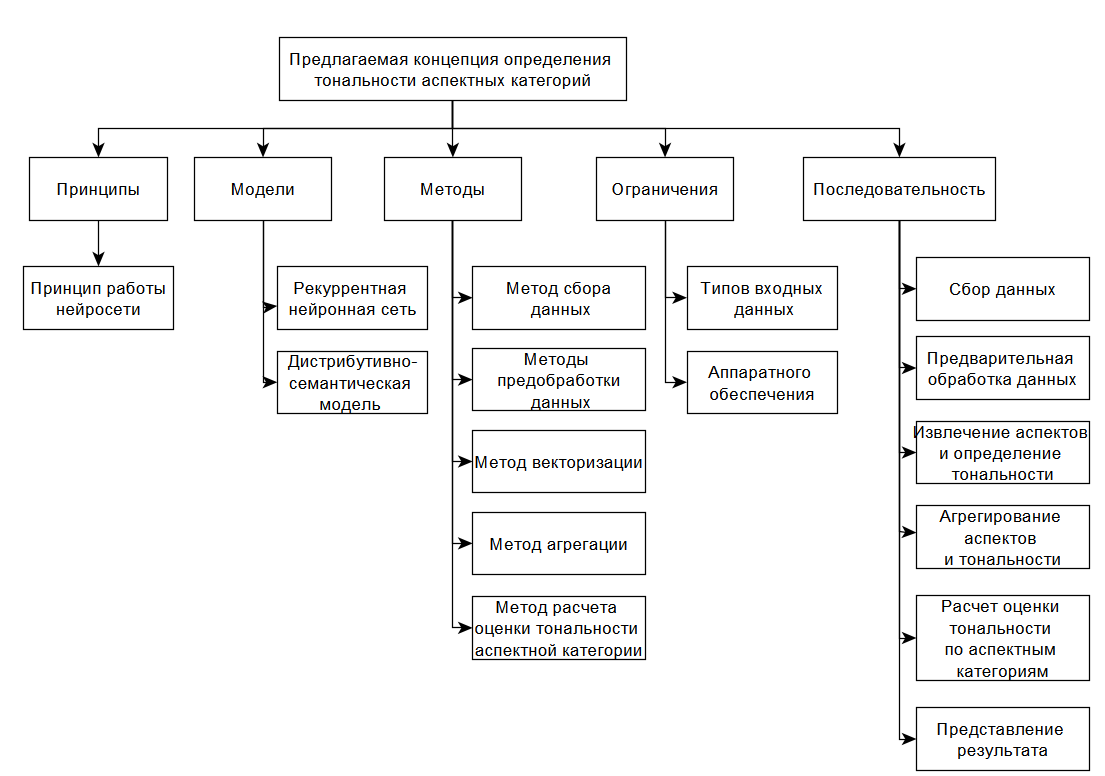
Рисунок 1.3. - Концепция определения тональности аспектных категорий
3.4. Требования к программному обеспечению Требования к программному обеспечению. Функциональные требования к программному обеспечению
Функциональные требования определяют поведение системы, описывая действия, которые система способна выполнять. Исходя из целей программного обеспечения, должны поддерживаться следующие функциональные требования (рис. 6):
-
Проведение анализа:
-
Предобработка текстов; -
Извлечение аспектов и тональностей; -
Агрегирование аспектов и тональностей; -
Расчет оценки тональности по аспектным категориям;
-
Предоставление выбора текста; -
Представление возможности просмотра выбранного текста по аспектным категориям; -
Импорт и экспорт данных.
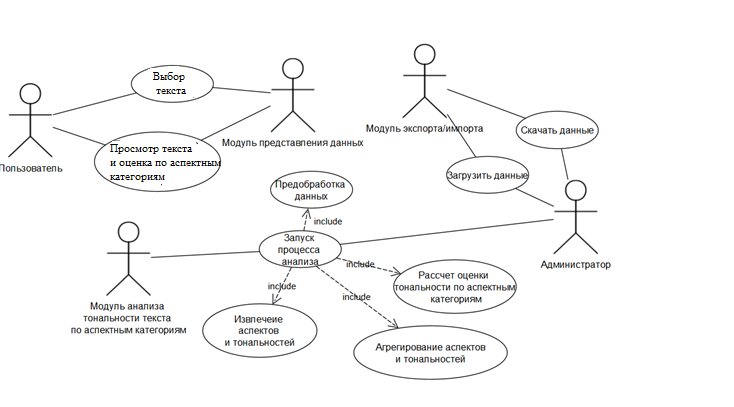
Рисунок 3.4. - Диаграмма вариантов использования
В существующих вариантах использования программного обеспечения есть несколько акторов. За исключением модулей являющихся частью системы, выделено два актора: пользователь и администратор. У пользователя есть только два варианта использования программного обеспечения: выбор интересующего вуза и просмотр отзывов и оценок тональности по аспектным категориям. У администратора доступны варианты использования: загрузка и выгрузка данных, запуск процесса анализа, направленного на получения оценок тональности по аспектным категориям. Процесс анализа включает в себя несколько вариантов: предобработка данных, извлечение аспектов и тональностей, агрегирования и расчета оценок тональностей.
Для каждого варианта использования администратором или пользователем составлена диаграмма последовательности (рис. 7-9).
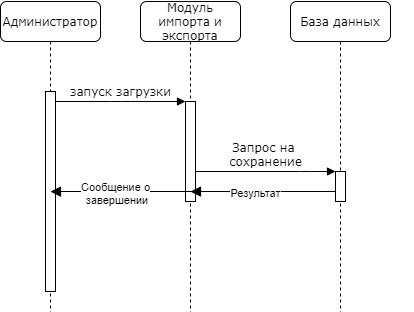
Рисунок 3.5. - Диаграмма последовательности загрузки данных
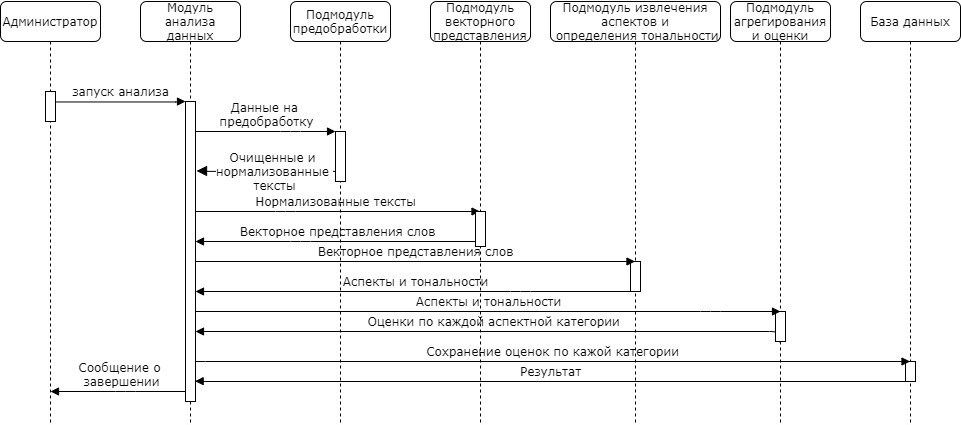
Рисунок 3.6. - Диаграмма последовательности проведения анализа для определения оценок тональностей по аспектным категориям