Файл: 1. Введение в теорию баз данных Вопрос Основные понятия.docx
Добавлен: 05.12.2023
Просмотров: 545
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Прежде всего, в разы возрастет нагрузка на системы-источники данных, так как одна и та же информация будет многократно передаваться по запросам в ЦХД, ОСД, зоны временного хранения и системы управления метаданными и НСИ. Очевидное решение – создать собственное хранилище данных при шине для кеширования запросов.
Во-вторых, регламент сбора информации, ранее централизованный в ETL, теперь рассеян по приложениям, запрашивающим данных. Рано или поздно возникнут рассогласования в регламентах сбора данных для ЦХД, ОСД, систем ведения НСИ и метаданных. Данные, собранные по разным методикам, в разные отрезки времени, обработанные по разным алгоритмам, будут несогласованны друг с другом. Тем самым будет разрушена основная цель создания ЦХД как единого источника согласованных непротиворечивых данных.
В случае замены SRD на интеграционную шину последствия не столь драматичны. Но для того, чтобы ЦХД могло отвечать на запросы витрин данных, направленных через шину, оно должно быть преобразовано в сервис. Это значит, что хранилище должно соответствовать наиболее распространенному стилю web – сервисов, и поддерживать протоколы HTTP/ HTTPS и SOAP и XML – формат сообщений. Такой подход работает для коротких сообщений, но в витрины необходимо передавать большой объем данных, что может быть решено с помощью передачи двоичных объектов. Необходимая реструктуризация данных не может быть возложена на шину, и должна выполняться либо в ЦХД, либо в витрине. Эта функция может быть решена с помощью сервиса-посредника, принимающего данные, и передающего их в витрины данных после реструктуризации. То есть, мы возвращаемся к идее средства SRD с шинным интерфейсом.
Таким образом, интеграционная шина может быть использована в архитектуре КХД как транспортная среда между источниками данных и ETL и между SRD и витринами данных в тех случаях, когда компоненты КХД территориально разнесены и находятся за межсетевыми экранами в соответствии со строгими требованиями к защите информации. В этом случае для обеспечения взаимодействия достаточно, чтобы был разрешен обмен по протоколам HTTP/ HTTPS. Вся логика сбора и преобразования информации должна быть по-прежнему сосредоточена в ETL и SRD.
Рекомендованная архитектура КХД.
Архитектура корпоративного хранилища данных (КХД) должна удовлетворять многим функциональным и нефункциональным требованиям, которые зависят от конкретных задач
, решаемых КХД. Как нет универсального банка, авиакомпании, или нефтяного концерна, так нет и единого решения КХД, пригодного на все случаи жизни. Но основные принципы, которым должно следовать КХД, все же можно сформулировать.
Прежде всего, это качество данных, которое можно понимать, как полные, точные и воспроизводимые данные, доставленные в срок туда, где они нужны. Качество данных трудно измерить напрямую, но о нем можно судить по принимаемым решениям. То есть, качество данных требует инвестиций, но и само способно приносить прибыль.
Во-вторых, это защищенность и надежность хранения данных. Ценность информации, накопленной в КХД, может быть сравнима с рыночной стоимостью компании. Несанкционированный доступ к КХД чреват серьезными последствиями, поэтому должны быть приняты меры, адекватные ценности данных.
В-третьих, данные должны быть доступны сотрудникам в объеме, необходимом и достаточном для выполнения своих функциональных обязанностей.
В-четвертых, сотрудники должны иметь единое понимание данных, то есть должно быть установлено единое смысловое пространство.
В-пятых, необходимо, по возможности, устранить конфликты в кодировках данных в системах источниках.
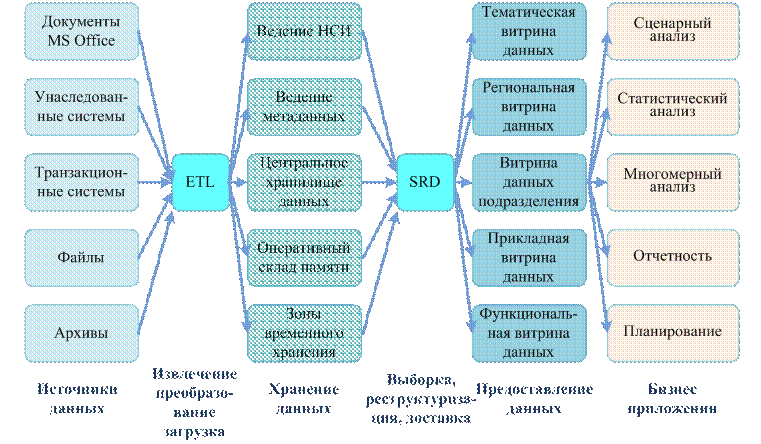
Рис. 50. Рекомендованная архитектура КХД
Предлагаемая архитектура следует проверенным принципам модульного конструирования «непотопляемых отсеков». Стратегия «Разделяй и властвуй» применима не только в политике. Разделяя архитектуру на модули, мы одновременно концентрируем в них определенную функциональность, получая власть над неуправляемой ИТ стихией. Средства ETL обеспечивают полный, надежный, точный сбор информации из источников данных благодаря сосредоточенной в ETL логике сбора, обработки и преобразования данных и взаимодействию с системами ведения метаданных и НСИ.
Система ведения метаданных является главным «хранителем мудрости», к которому можно обратиться за советом. Система ведения метаданных поддерживает актуальность бизнес-метаданных, технических, операционных и проектных метаданных.
Система ведения НСИ является третейским судьей при разрешении конфликтов кодировок данных.
Центральное хранилище данных (ЦХД) несет только нагрузку по надежному защищенному хранению данных. В зависимости от поставленных задач, надежность программно-технического комплекса (ПТК) ЦХД может достигать 99,999%, то есть обеспечивать бесперебойную работу с простоем не более 5 мин в год. ПТК ЦХД может обеспечивать защиту данных от несанкционированного доступа, саботажа и стихийных бедствий. Структура данных в ЦХД оптимизирована исключительно с целью обеспечения эффективного хранения данных.
Средства выборки, реструктуризации и доставки данных (SRD) в такой архитектуре являются единственным пользователем ЦХД, беря на себя всю работу по заполнению витрин данных и, тем самым, снижая нагрузку на ЦХД по обслуживанию запросов пользователей.
Витрины данных содержат данные в структурах и форматах, оптимальных для решения задач пользователей данной витрины. В настоящее время, когда даже ноутбук может быть оснащен терабайтным диском, проблемы, связанные с многократным повторением данных в витринах, не имеют значения. Главное преимущество этой архитектуры – предоставление доступа для удобной работы пользователей с необходимым объемом данных, возможность быстрого восстановления содержимого витрин из ЦХД при сбое витрины, обеспечение работы пользователей при отсутствии связи с ЦХД.
Достоинство этой архитектуры заключается в возможности раздельного проектирования, создания, эксплуатации и доработки отдельных компонентов без радикальной перестройки всей системы. Это означает, что начало работ по созданию КХД не требует сверхусилий или сверхинвестиций. Достаточно начать с ограниченного по своим возможностям программно-технического комплекса, и следуя предложенным принципам, создать работающий и действительно полезный для пользователей прототип. Далее необходимо выявить узкие места и развивать соответствующие компоненты.
Применение этой архитектуры вместе с тройной стратегией интеграции данных, метаданных и НСИ, позволяет сократить сроки и бюджет проекта внедрения КХД и развивать его в соответствии с изменяющимися требованиями бизнеса.
Вопрос 6. Фрактальные методы в архивации.[21]
История фрактального сжатия.
Рождение фрактальной геометрии обычно связывают с выходом в 1977 году книги Б. Мандельброта «Фрактальная геометрия природы». Одна из основных идей книги заключалась в том, что средствами традиционной геометрии (то есть используя линии и поверхности), чрезвычайно сложно представить природные объекты. Фрактальная геометрия задает их очень просто.
В 1981 году Джон Хатчинсон опубликовал статью «Фракталы и самоподобие», в которой была представлена теория построения фракталов с помощью системы итерируемых функций (IFS, Iterated Function System). Четыре года спустя появилась статья Майкла Барнсли и Стефана Демко, в которой приводилась уже достаточно стройная теория IFS. В 1987 году Барнсли основал Iterated Systems, компанию, основной деятельностью которой является создание новых алгоритмов и ПО с использованием фракталов. Всего через год, в 1988 году, он выпустил фундаментальный труд «Фракталы повсюду». Помимо описания IFS, в ней был получен результат, известный сейчас как Collage Theorem, который лежит в основе математического обоснования идеи фрактальной компрессии.
Если построение изображений с помощью фрактальной математики можно назвать прямой задачей, то построение по изображению IFS – это обратная задача. Довольно долго она считалась неразрешимой, однако Барнсли, используя Collage Theorem, построил соответствующий алгоритм. (В 1990 и 1991 годах эта идея была защищена патентами.) Если коэффициенты занимают меньше места, чем исходное изображение, то алгоритм является алгоритмом архивации.
Первая статья об успехах Барнсли в области компрессии появилась в журнале BYTE в январе 1988 года. В ней не описывалось решение обратной задачи, но приводилось несколько изображений, сжатых с коэффициентом 1:10000, что было совершенно ошеломительно. Но практически сразу было отмечено, что несмотря на броские названия («Темный лес», «Побережье Монтере», «Поле подсолнухов») изображения в действительности имели искусственную природу. Это, вызвало массу скептических замечаний, подогреваемых еще и заявлением Барнсли о том, что «среднее изображение требует для сжатия порядка 100 часов работы на мощной двухпроцессорной рабочей станции, причем с участием человека».
Отношение к новому методу изменилось в 1992 году, когда Арнауд Джеквин, один из сотрудников Барнсли, при защите диссертации описал практический алгоритм и опубликовал его. Этот алгоритм был крайне медленным и не претендовал на компрессию в 10000 раз (полноцветное 24-разрядное изображение с его помощью могло быть сжато без существенных потерь с коэффициентом 1:8 - 1:50); но его несомненным достоинством было то, что вмешательство человека удалось полностью исключить. Сегодня все известные программы фрактальной компрессии базируются на алгоритме Джеквина. В 1993 году вышел первый коммерческий продукт компании Iterated Systems. Ему было посвящено достаточно много публикаций, но о коммерческом успехе речь не шла, продукт был достаточно «сырой», компания не предпринимала никаких рекламных шагов, и приобрести программу было тяжело.
В 1994 году Ювал Фишер были предоставил во всеобщее пользование исходные тексты исследовательской программы, в которой использовалось разложение изображения в квадродерево и были реализованы алгоритмы оптимизации поиска. Позднее появилось еще несколько исследовательских проектов, которые в качестве начального варианта программы использовали программу Фишера. В июле 1995 года в Тронхейме (Швеция) состоялась первая школа-конференция, посвященная фрактальной компрессии.
Идея метода.
Фрактальная архивация основана на том, что мы представляем изображение в более компактной форме - с помощью коэффициентов системы итерируемых функций (Iterated Function System - далее по тексту как IFS). Прежде, чем рассматривать сам процесс архивации, разберем, как IFS строит изображение, т.е. процесс декомпрессии.
Строго говоря, IFS представляет собой набор трехмерных аффинных преобразований, в нашем случае переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (х_координата, у_координата, яркость).
Наиболее наглядно этот процесс продемонстрировал Барнсли в своей книге «Fractal Image Compression». Там введено понятие Фотокопировальной Машины, состоящей из экрана, на котором изображена исходная картинка, и системы линз, проецирующих изображение на другой экран: (рис. 51):
· линзы могут проецировать часть изображения произвольной формы в любое другое место нового изображения;
· области, в которые проецируются изображения, не пересекаются;
· линза может менять яркость и уменьшать контрастность;
· линза может зеркально отражать и поворачивать свой фрагмент изображения;
· линза должна масштабировать (причем только уменьшая) свой фрагмент изображения.
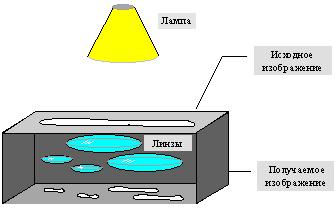
Рис. 51. Машина Барнсли
Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется «неподвижной точкой» или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Таким образом, интуитивно понятно, что система итерируемых функций задает фрактал (нестрого - самоподобный математический объект).
Наиболее известны два изображения, полученных с помощью IFS: «треугольник Серпинского» (рис. 52) и «папоротник Барнсли» рис. 53.