Файл: 1. Введение в теорию баз данных Вопрос Основные понятия.docx
Добавлен: 05.12.2023
Просмотров: 544
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
· выделение,
· освобождение,
· защита областей физического носителя,
· способы адресации и пересылки.
Эффективность в этом случае связывается с процессами обмена между устройствами оперативной и внешней памяти, искусственно вводимой для обеспечения функциональной эффективности отдельных операций (например, поиска по ключам) избыточностью данных,
Рассмотрим разновидности и типологию «компьютерных» логических структур данных с точки зрения особенности их организации.
Заметим, что мы не будем рассматривать простейшие типы, к которым относятся стандартные типы – целые и вещественные числа, логические переменные, символы. Их состав и структура определяется в основном набором встроенныхбазовых типов данных и операций, свойственных конкретному типу ЭВМ.
Итак, структура в первую очередь определяет алгоритм выборки отдельных элементов данных, но в то же время необходимо отметить, что она отражает и особенности «технологии» организации и обработки информации, свойственные человеку в его повседневной деятельности.
Физически понятию структура соответствует запись данных.
Запись - это упорядоченная в соответствии с характером взаимосвязей совокупность полей (элементов) данных, размещаемых в памяти в соответствии с их типом.
Память, отводимая для хранения значения элемента данных (поле данных), должна выбираться в соответствии с диапазоном значений, которые может иметь этот элемент. Поскольку для выполнения операции присвоения значения элементу данных (установление соответствующих битов в «0» или «1») необходимо сначала выделить память, для чего используются две схемы– статическая и динамическая. Для первой характерно выделение памяти до того, как реально появляются значения (обычно на этапе трансляции программы); для второй – в тот момент, когда программа во время исполнения получает конкретное значение. Кроме того, характер данных (тип данных) определяет способ представления и, соответственно, некоторое множество стандартных операций (примитивов). Поле представляет собой минимальную адресуемую (идентифицируемую) часть памяти - единицу данных, на которую можно ссылаться при обращении к данным.
Итак, структура данных - это способ отображения значений в памяти:
· размер области
· порядок ее выделения (который и определит характер процедуры адресации/выборки).
Зачастую именно успешность структурирования данных определяет сложность процедур их обработки.
Классификация структур данных должна проводиться с двух точек зрения.
1) с точки зрения порядка их размещения/выборки:
по характеру взаимосвязи элементов структуры виды структур можно разделить на
· линейные
· нелинейные.
2) с точки зрения однородности и «элементарности» типов данных, отражающих понятийную структуру ПрО.
по характеру информации, представляемой структурой:
· однородные структуры, где все элементы находятся на одном понятийном уровне и имеют один тип данных,
· неоднородные (композиционные), где элементы относятся к нескольким понятийным уровням или имеют разную природу.
Линейные структуры.
К линейным структурам относятся массивы и последовательности, таблицы.
Порядок следования (и, соответственно, выборки) элементов таких структур имеет линейный характер и соответствует порядку расположения элементов в памяти: один за другим без каких-либо промежутков.
Адрес элемента соответствует его положению и определяется индексом - порядковым номером элемента в последовательности размещения. К элементу имеется прямой доступ, если известен его индекс.
Особенностью линейной структуры является то, что при последовательной организации (размещении) она допускает возможность прямого доступа к произвольному элементу. Это возможно потому, что условие однородности (однотипности) предполагает, что все элементы занимают расположенные строго последовательно области одинакового размера, что и позволяет достаточно просто вычислять значение физического адреса элемента по значению его индекса.
Массив представляет собой совокупность однотипных элементов, причем число элементов массива известно до его размещения, что позволяет строить гибкие многомерные системы адресации.
Последовательность, так же, как и массив, представляет собой совокупность однотипных элементов. Однако число элементов до размещения неизвестно.
Хотя, каждая конкретная последовательность имеет конечную длину, до начала обработки (и, соответственно, размещения) необходимо считать длину последовательности бесконечной.
Принципиальность такого предположения выражается в том, что необходимо предусматривать
специальную процедуру использования памяти (выделения/освобождения),
алгоритм обработки последовательности по частям (в ряде случаем, когда это требуется).
Этот тип данных превалирует в операциях ввода/вывода с устройствами внешней памяти.
Последовательный доступ позволяет организовать «потоковые» операции: однородность позволяет рассматривать пересылаемые данные как непрерывный поток.
Поток не может быть прерван по контекстно определяемому условию.
Например, при пересылке текста - по значению кода «перевод строки», и это не заставляет программу анализировать значение каждого очередного элемента. И, кроме того, последовательный доступ - это простота управления памятью и устройством ввода-вывода.
Но мы, не рассматриваем очереди и стеки. Они отличаются тем, что для них устанавливаются особые схемы добавления (размещения в памяти) новых элементов и их выборки.
Очередь: порядок размещения/выборки определяется правилом «первым размещен – первым выбран».
Стек - «первым размещен – последним выбран». Выборка элемента влечет его удаление из последовательности.)
Таблица - это последовательности, обычно представляемые строками - совокупностями разнотипных элементов. Таблица -это множество записей, каждая из которых представляет набор поименованных полей.
Однако с точки зрения размещения элементов таблица может быть представлена как одномерный массив (или, в случае БД - последовательность) с однородными композиционными элементами, каждый из которых представляет собой совокупность разнотипных элементов.
Это позволяет свести ввод/вывод таких типов структур к последовательным элементарным операциям.
Разнотипность элементов позволяет ввести отличную от перечислительной схему идентификации записей, определив одно из полей как ключ записи. Обычно ключ содержит значение, используемое в процедурах упорядочения и поиска записей.
Нелинейные структуры.
В качестве примеров нелинейных структур рассмотрим списки, деревья и сети.
Порядок следования (и, соответственно, выборки) элементов таких структур может не соответствовать порядку расположения элементов в памяти.
Списки представляют собой пример линейного упорядочения,
Деревья - двумерного,
Сети - произвольного.
Соответственно различаются методы и средства, обеспечивающие последовательность выборки элементов данных. Обычно для обеспечения возможности прямого доступа к произвольному элементу необходимо использовать вспомогательные структуры типа инвертированных списков.
Список представляет собой совокупность однотипных элементов. Порядок выборки элементов может отличаться от порядка следования в памяти, определенного при размещении. Наиболее очевидный способ установления однонаправленного порядка выборки элементов - это сопоставить каждому элементу списка ссылку, указывающую на следующий элемент. Соответственно, для организации двунаправленного списка, допускающего также выборку в обратном порядке, каждый элемент должен иметь ссылку на предыдущий.
Такая организация уже не допускает возможности прямого доступа, например, по номеру элемента.
Число элементов списка, как и в случае последовательностей, может быть неизвестно до размещения, и до начала обработки (и, соответственно, размещения) необходимо считать длину списка бесконечной, что ведет к необходимости предусматривать специальную процедуру выделения/освобождения памяти.
Таким образом, с точки зрения физической реализации элемент списка должен быть составным, включающим собственно информативные данных, несущий смысловое значение, и дополнительные данные (ссылки), определяющие порядок доступа к информативным элементам.
Понятие списка достаточно универсально. В общем случае ссылки могут указывать ответвления к другим спискам - подспискам.
В зависимости от способа построения списка и предполагаемых путей доступа к элементам различают следующие виды ссылок:
· перекрестные,
· боковые,
· иерархические,
· множественные,
Они позволяют изменять «естественный» последовательный порядок прохода по элементам списка.
Деревья.
Дерево (рис. 15) представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел - корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемым исходным узлом для данного узла. Каждый элемент имеет только один исходный. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне, которые называются
порожденными. Элементы, расположенные в конце ветви, т. е. не имеющие порожденных, называются листьями.
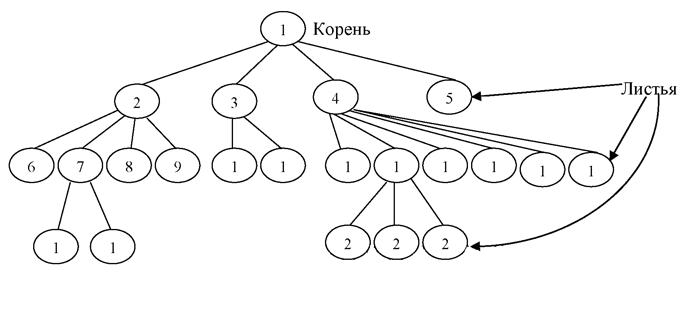
Рис. 15. Пример структуры дерева
Существует несколько способов представления структуры дерева.
Например, дерево может быть определено как иерархия узлов с попарными связями, в которой:
1. Самый верхний уровень иерархии имеет один узел, называемый корнем.
2. Все узлы, кроме корня, связываются с одним и только одним узлом на более высоком уровне по отношению к ним самим.
Такое определение в части организации связей совпадает со списком, и, в частности, список представляет вырожденный случай дерева, в котором каждая вершина имеет не более одного поддерева. Заметим, что деревья мы рассматриваем как средство и для логического, и для физического представления данных.
В логическом описании данных они используются для определения связей между элементами структуры. При определении физической организации данных - для определения набора указателей, реализующих связи между ними.
Использование ссылок для организации доступа к отдельным элементам структуры не позволяет сократить процедуру поиска, в основу которой положен последовательный перебор. Процедура поиска будет эффективнее, если будет предварительно установлен некоторый порядок перехода к следующему элементу дерева. Такой порядок в ряде случаев определяется в отношении метода обхода и регулярности итераций, определяемой длиной пути и кратностью деления вершины.
Выделяют три метода обхода: сверху вниз, слева направо, снизу вверх. Регулярность обхода дерева может быть связана с упорядоченными деревьями, к которым относятся сбалансированные (рис. 16) и двоичные деревья (рис. 17).
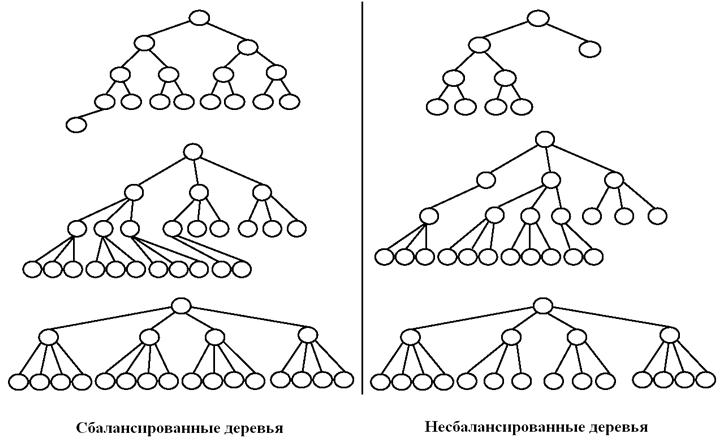
Рис. 16. Примеры сбалансированных и несбалансированных деревьев