Файл: Интеллектуальная обработка информации. Искусственный интеллект. Основные вехи развития ии. Примеры практических задач.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.12.2023
Просмотров: 49
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
-
Интеллектуальная обработка информации. Искусственный интеллект. Основные вехи развития ИИ. Примеры практических задач.
Интеллектуальная обработка информации — это автоматизированное решение (слабо)формализованных задач. Но автоматизированное не равно автоматическое!
Искусственный интеллект – комплекс технологических решений, позволяющий имитировать когнитивные функции человека (включая самообучение и поиск решений без заранее заданного алгоритма) и получать при выполнении конкретных задач результаты, сопоставимые как минимум с результатами интеллектуальной деятельности человека.
Основные вехи развития искусственного интеллекта:
-
1943-1949 – Формализованное понятие ИИ/ИНС, первые аппаратные реализации -
1958 – решение задач классификация с помощью однослойного перцептрона -
1960 – реализация задач предсказания и адаптивного управления на термисторах -
1969 – обнаружение ограниченности перцептрона, спад интереса к ИНС -
1976-1982 – «период забвения», Al Winter -
1982 – обучение без учителя (нейронная сеть Кохонена), развитие метода обратного распространения ошибки, взрывной рост интереса к ИНС -
2007 – проявление методов глубокого обучение -
2010 – первый opensource framework (torch)
Примеры практических задач ТИОИ:
-
Анализ мультимедиа-контента, оценка психофизического состояния человека (распознавание речи и тональности, определение дикторов, выявление признаков сгенерированного контента и пр.) -
Генерация мультимедиаконтента (замена диктора, генерация/модификация видеоряда и пр.) -
Семантический анализ текстов на естественном языке -
Прогнозирование распространения информации в СМИ и социально-ориентированных ресурсах сети Интернет, анализ и прогнозирование поведенческих данных людей, обнаружение аномалий
-
Тест Тьюринга. Сильный и слабый ИИ: «китайская комната». Этическая проблема ИИ.
Тест Тьюринга: Пусть А - компьютер. В - человек, С - тоже человек, который общается с А и В посредством только письменных сообщений. С знает, что один из них компьютер, а второй человек, но не знает, кто есть кто. Задача обоих (А и В) - убедить С, что всё наоборот, при этом А и В друг с другом не взаимодействуют.
Тест Тьюринга считался пройденным, если компьютеру (А) удалось бы вводить собеседника (человека) С в заблуждение на протяжении хотя бы 30% суммарного времени. Тест Тьюринга был пройден «Женей Густманом» с результатом 33%.
Сильный ИИ – теория, утверждающая возможность существования ИИ, обладающего когнитивными способностями, т.е. способного ощущать себя как личность.
Слабый ИИ – теория, утверждающая отсутствие когнитивных способностей у ИИ.
«Китайская комната»: человек находится в изолированной комнате и не знает ни одного китайского иероглифа. Перед ним находятся таблички с иероглифами и книга с точными и полными инструкциями по манипуляции иероглифами. Наблюдатель, знающий китайские иероглифы, передает в комнату иероглифы с вопросами и ожидает получить ответ. Человек ничего не понимает, но следует инструкциям и выдает адекватные ответы. Наблюдатель уверен, что внутри китаец. Таким образом, человек проходит тест Тьюринга, но от этого не начинает понимать китайский язык.
Практическая польза ТИОИ:
-
Построение модели без формализованного описания; -
Устойчивость к шумам входных данных и адаптация к изменениям – обобщения модели на несколько случаев; -
Быстродействие за счет возможности аппаратного ускорения – однотипные вычисления (ИНС); -
Забота об операторе: ручная обработка специфических материалов может привести к профессиональной деформации
Этическая проблема ТИОИ – темная сторона:
-
Дать или не дать кредит? Сколько будет стоить страховка? -
Продолжит ли человек работать по специальности и после учебы? Стоит ли его оставить или отчислить? -
Выживет ли человек после операции? Стоит ли пытаться его спасти? -
Станет ли подсудимый рецидивистом? -
Полезен ли данный человек для общества?
-
База знаний, онтологии, примеры баз знаний. Форматы записи онтологий. Шаги по построению системы знаний.
База знаний – база данных, содержащая правила вывода и информацию о человеческом опыта и знаниях в некоторой предметной области. В самообучающихся системах база знаний также содержит информацию, являющуюся результатом решения предыдущих задач.
Онтология – иерархический способ представления в базе знаний набора понятий и их отношений. Таким образом, знания — это совокупность онтологий.
Примеры баз знаний – симптомы, по которым ставится диагноз; параметры, по которым выдаётся кредит или нет (возраст, стаж работы, зарплата)
Язык описания онтологий — формальный язык, используемый для кодирования онтологии. Существует несколько подобных языков (список неполон):
-
OWL — Web Ontology Language, стандарт W3C, язык для семантических утверждений, разработанный как расширение RDF и RDFS; -
KIF (KnowledgeInterchangeFormat — формат обмена знаниями) — основанный на S-выражениях синтаксис для логики; -
Common Logic (CL) — преемник KIF (стандартизован — ISO/IEC 24707:2007). -
CycL — онтологический язык, использующийся в проекте Cyc. Основан на исчислении предикатов с некоторыми расширениями более высокого порядка. -
DAML -
OIL -
Agent Communications Language
Шаги по построению систем знаний:
-
Извлечений знаний -
Структурированное описание знаний в формализованном виде -
Дедупликация и снятие противоречий -
Хранение знаний в базе знаний -
Форматирование выводов
-
Типы знаний, факты и правила. Виды знаний. Данные, модели представления знаний и инженерия знаний.
Типы знаний:
-
Факты (фактические знания) – знания типа «А эквивалентно А» -
Правила (знания для принятия решения) – знания типа «из А следует В» -
Метазнания (знания о знаниях) – знания, касающиеся способов использования знаний, и знания, касающиеся свойств знаний
Виды знаний:
-
Общедоступные знания – это факты, определения, теории, которые обычно изложены в учебниках и справочниках по данной области -
Эвристические знания – индивидуальные знания эксперта, которые основываются на его собственном опыте, накопленном в результате многолетней практики, и в значительной степени состоят из эмпирических правил. Эвристики не всегда в полной мере осознаются их обладателями, зато позволяют находить перспективные подходы к задачам и эффективно работать при зашумленных или неполных данных
Данные – совокупность фактов и идей, представленных в формализованном виде.
Модель представления знаний – задания знаний для хранения, удобного доступа и взаимодействия с ними, который подходит под задачу интеллектуальной системы.
Инженерия знаний – раздел (дисциплина) инженерии, направленный на внедрение знаний в компьютерные системы для решения сложных задач, обычно требующих богатого человеческого опыта.
Существуют 4 модели представления знаний:
-
Продукционная -
Формально логическая -
Фреймовая -
Семантическая сеть
В основе продукционной модели представления знаний находится следующая конструкция продукции (правила): IF <условие> THEN <действие>.
Условия можно сочетать с помощью логических функций AND, OR. Условия и действия составленных правил формируются из атрибутов и значений.
Продукционная модель представления знаний нашла широкое применение в АСУТП (автоматизированная система управления технологическом процессом).
Порядок работы продукционной модели:
-
В базе данных продукционной системы хранятся правила, истинность которых установлена заранее при решении определенной задачи -
Правило срабатывает, если при сопоставлении фактов, содержащихся в базе данных с условием правила, которое подвергается проверке, имеет место совпадение -
Результат работы правила заносится в базу данных
Формально логическая модель:
-
В основе лежит предикат первого порядка -
Существует конечное непустое множество объектов предметной области Р -
На множестве Р с помощью функций интерпретаторов установлены связи между объектами -
На основе этих связей строятся все закономерности и правила предметной области
Если представление предметной области не правильное, то есть связи между объектами настроены не верно или не в полной мере, то правильная работоспособность системы будет под угрозой!
Разница между формальной логический и продукционной моделями состоит в том, что в продукционной модели не определены никакие связи между хранимыми объектами предметной области, она оперирует условиями.
Фреймовая модель:
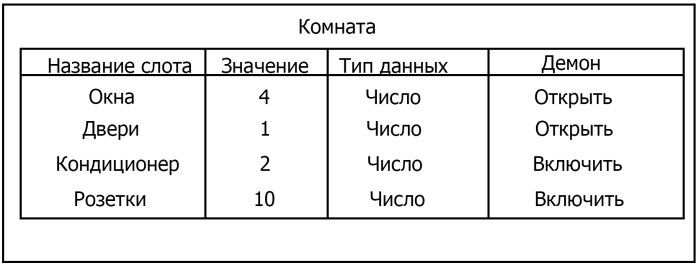
Фрейм – это образ, рамка, шаблон, которая описывает объект предметной области, с помощью слотов.
Слот – это артибут объекта. Слот имеет имя, значение, тип хранимых данных, демон.
Демон – процедура автоматически выполняющаяся при определенных условиях.
Имя фрейма должно быть уникальным в пределах одной фреймовой модели. Имя слота должно быть уникальным в пределах одного фрейма.
Слот может хранит другой фрейм, тогда фреймовая модель вырождается в сеть фреймов
Пример фреймовой модели:
Семантическая сеть – модель представления знаний, имеет вид ориентированного графа. Вершины графа соответствуют объектам предметной области, а дуги задают отношения между ними. Объектами могут быть: понятия, события, свойства, процессы.
Классификация семантических сетей:
-
Однородные сети обладают только одним типом отношений (стрелок). -
В неоднородных сетях количество типов отношений больше одного. Примером таких сетей может быть семантическая сеть Википедии.
Еще одна классификация семантических сетей:
-
Сети с бинарными отношениями между понятиями – дуга связывает равно две вершины -
Сети с N-арными отношениями между понятиями – дуга связывает N вершин. Такая семантическая сеть описывается гиперграфом.
-
Определение машинного обучения, признаки, модель, гипотеза. Регрессия и классификация.
Пусть компьютерной программе поставлена задача обучаться: выполнять задание T (task) на примерах E (experience) с измеряемым параметром качества P (perfomance). Машинное обучение реализуется, если качество Р выполнения задания Т растет с увеличением опыта Е.
Количество признаков обычно обозначают через n, а количество примеров для обучения через m. Признак — это критерий, по которому будет строиться гипотеза.
Гипотеза — это прогнозируемая итоговая модель.
Регрессия и классификация — это два метода, которые используются при разработке алгоритмов машинного обучения. И алгоритмы регрессионного машинного обучения, и алгоритмы классификационного машинного обучения относятся к сфере машинного обучения с учителем.
Ключевое различие между классификацией и регрессией состоит в том, что классификация предсказывает дискретную метку, а регрессия предсказывает непрерывное количество или значение.

-
Масштабирование и обезразмеривание признаков. Понятие признаков и размерности признакового пространства.