Файл: Интеллектуальная обработка информации. Искусственный интеллект. Основные вехи развития ии. Примеры практических задач.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.12.2023
Просмотров: 51
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Что такое признаки (features) и для чего они нужны?
Признак, он же «фича» (от англ feature) – это переменная (столбец в таблице), которая описывает отдельную характеристику объекта. Признаки являются краеугольным камнем задач машинного обучения в целом: именно на их основании мы строим предсказания в моделях.
Признаки могут быть следующих видов:
Бинарные, которые принимают только два значения. Например, [true, false], [0,1], [“да”, “нет”].
Категориальные (или же номинальные). Они имеют конечное количество уровней, например, признак «день недели» имеет 7 уровней: понедельник, вторник и т. д. до воскресенья.
Упорядоченные. В некоторой степени похожи на категориальные признаки. Разница между ними в том, что данном случае существует четкое упорядочивание категорий. Например, «классы в школе» от 1 до 11. Сюда же можно отнести «время суток», которое имеет 24 уровня и является упорядоченным.
Числовые (количественные). Это значения в диапазоне от минус бесконечности до плюс бесконечности, которые нельзя отнести к предыдущим трем типам признаков.
Про масштабирование/обезразмеравание см. в следующем вопросе (выделено (одно гребаное предложение)).
-
Линейная регрессия и многомерная линейная регрессия, матричное представление. Функция потерь для линейной регрессия.
Пусть компьютерной программе поставлена задача обучаться: выполнять задание T (task) на примерах E (experience) с измеряемым параметром качества P (perfomance). Машинное обучение реализуется, если качество Р выполнения задания Т растет с увеличением опыта Е.
Количество признаков обычно обозначают через n, а количество примеров для обучения через m. Признак – это критерий, по которому будет строиться гипотеза.
Гипотеза – это прогнозируемая итоговая модель.
Регрессия и классификация — это два метода, которые используются при разработке алгоритмов машинного обучения. И алгоритмы регрессионного машинного обучения, и алгоритмы классификационного машинного обучения относятся к сфере машинного обучения с учителем.
Ключевое различие между классификацией и регрессией состоит в том, что классификация предсказывает дискретную метку, а регрессия предсказывает непрерывное количество или значение.
Одномерная линейная регрессия – аппроксимация эмпирической зависимости y(x) прямой
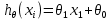 По факту это прямая y=kx+b.
По факту это прямая y=kx+b. Многомерная линейная регрессия – это линейная регрессия в n-мерном пространстве (объекты и признаки являются n-мерными векторами).
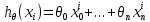 – классическое уравнение линейной регрессии в виде уравнения.
– классическое уравнение линейной регрессии в виде уравнения.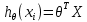 – уравнение линейной регрессии в матричном виде.
– уравнение линейной регрессии в матричном виде.Размерность Х (признакового пространства) - (n+1*m).
Размерность θ (пространства параметров) - (n+1*1).
Так как на практике все признаки имеют различные размерности, для этого применяется масштабирование/обезразмеривание.
Цель нормализации – уместить все примерно в интервале
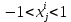
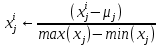 – средняя нормализация, где
– средняя нормализация, где 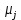 – среднее значение j-ого признака в обучающей выборке.
– среднее значение j-ого признака в обучающей выборке.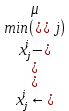 – min/max нормализация с обезразмериванием (0,1).
– min/max нормализация с обезразмериванием (0,1).Для линейной регрессии функция потерь определяется следующим образом:
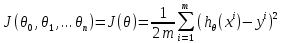
-
Минимизация функции потерь. Метод градиентного спуска и аналитическое решение для линейной регрессии.
Метод градиентного спуска заключается в одновременном рассчете всех частных производных
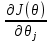 при фиксированных значениях
при фиксированных значениях 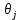 на величину
на величину 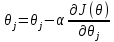 .
.Аналитическое решение: по свойству минимума функции все частные производные равны нулю. Другими словами:
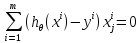 . Можно показать, что это эквивалентно:
. Можно показать, что это эквивалентно: 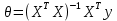 .
.-
Регуляризация. Влияние регуляризации на процесс обучения.
Если модель слишком хорошо описывает данные обучающей выборки – это тоже плохо. Так как признаки высших порядков имеют смысл возмущения, то чем выше порядок признака, тем меньше должен быть его вклад. Регуляризация – введение штрафов для высоких степеней признаков.
С регуляризацией функция потерь будет записана в виде:

- Логистическая регрессия, сигмоидальная функция и граница принятия решения. Функция потерь для логистической регрессии. Многоклассовая классификация. Оценка качества классификации: точность, полнота и F-мера. Confusion matrix.
В отличие от обычной регрессии, в методе логистической регрессии не производится предсказание значения числовой переменной исходя из выборки исходных значений. Вместо этого, значением функции является вероятность того, что данное исходное значение принадлежит к определенному классу.
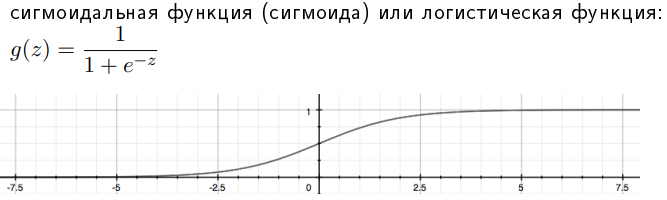





Всю имеющуюся выборку делят на:
1. Обучающую – 60-80% (минимизируется функция потерь)
2. Кросс-валидационную – 10-20% (подбираются гиперпараметры модели так, чтобы ошибка была минимальна)
3. Тестовую (контрольную) – 10-20% (оценивается ошибка для каждого набора параметров модели+гиперпатраметров)
Смещение — это ошибка, возникающая в результате ошибочного предположения в алгоритме обучения. В результате большого смещения алгоритм может пропустить связь между признаками и выводом (недообучение).
Дисперсия — это ошибка чувствительности к малым отклонениям в тренировочном наборе. При высокой дисперсии алгоритм может как-то трактовать случайный шум в тренировочном наборе, а не желаемый результат (переобучение).
- Обучающая, контрольная и кросс-валидационная выборки. Переобучение и недообучение, смещение и дисперсия. Визуализация процесса обучения, кривые обучения, выбор оптимальных параметров и диагностика процесса обучения.
Всю имеющуюся выборку делят на:
-
Обучающую – 60-80% (минимизируется функция потерь) -
Кросс-валидационную – 10-20% (подбираются гиперпараметры модели так, чтобы ошибка была минимальна) -
Тестовую (контрольную) – 10-20% (оценивается ошибка для каждого набора параметров модели+гиперпатраметров)
Смещение — это ошибка, возникающая в результате ошибочного предположения в алгоритме обучения. В результате большого смещения алгоритм может пропустить связь между признаками и выводом (недообучение).
Дисперсия — это ошибка чувствительности к малым отклонениям в тренировочном наборе. При высокой дисперсии алгоритм может как-то трактовать случайный шум в тренировочном наборе, а не желаемый результат (переобучение).
-
Биологический и формальный нейроны. Достоинства искусственных нейронных сетей. Входные, выходные и промежуточные нейроны. Прямое распространение в ИНС.
Биологический нейрон – нервная клетка, которая обрабатывает информацию в нервных сетях. Состоит из тела, дендритов (принимают) и аксонов (передают сигнал), ядра (содержит информацию о наследственных свойствах) и плазмы. На окончаниях аксонов находятся синапсы, через которые передает электрический импульс. Сообщения передаются посредством частотно-импульсной модуляции.
Искусственный нейрон – упрощенная модель биологического нейрона, представляет собой взвешенный сумматор с нелинейной функцией активацией.
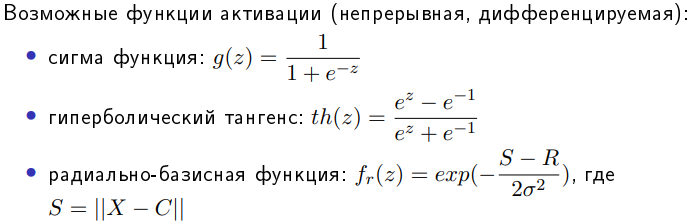
Использование нейросетей может существенно облегчить работу человека, потому что они:
-
активно обучаются и могут находить оптимальные решения вместо человека; -
хорошо работают в связке «человек — нейронная сеть», увеличивают угол обзора для принятия решения и страхуют от серьёзных ошибок.
Самыми распространенными применениями нейронных сетей является:
-
Классификация — распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд. -
Предсказание — возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке. -
Распознавание — в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Многослойный перцептрон — нейронная сеть, состоящая из слоев, каждый из которых состоит из элементов — нейронов (точнее их моделей). Эти элементы бывают трех типов: сенсорные (входные, S), ассоциативные (обучаемые «скрытые» слои, A) и реагирующие (выходные, R). Многослойным этот тип перцептронов называется не потому, что состоит из нескольких слоев, ведь входной и выходной слои можно вообще не оформлять в коде, а потому, что содержит несколько (обычно, не более двух — трех) обучаемых (A) слоев.
Модель нейрона (будем называть его просто нейрон) — это элемент сети, который имеет несколько входов, каждый из которых имеет вес. Нейрон, получая сигнал, помножает сигналы на веса и суммирует получившиеся величины, после чего передает результат к другому нейрону или на выход сети. Здесь тоже многослойный перцептрон имеет отличия. Его функция — сигмоид, она выдает значения на промежутке от 0 до 1. К сигмоидам относится несколько функций, мы будем иметь ввиду логистическую функцию. Несколько слоев, которые могут обучаться (точнее, подстраиваться) позволяют аппроксимировать очень сложные нелинейные функции, то есть их область применения шире, нежели однослойных.
Сети прямого распространения — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Функция активации используется для имитации работы биологического нейроона. Она применяется ко всем отдельным нейронам и на выходе получают выходное значение всего нейрона. После чего это значение сравнивается с пороговым значением и если значение функции превышает его, то это значение проходит дальше в следующие слои, иначе это воспринимается как шум (хотя в ИНС вроде как все значения проходят дальше в последующие слои).
-
Обучение с подкреплением. Генеративно-состязательные нейронные сети. Генератор и дискриминатор. Особенности обучения генеративно-состязательных сетей. Примеры генеративно-состязательных сетей.
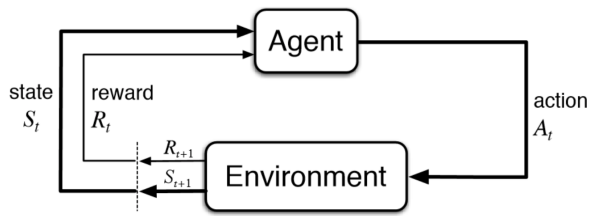
Обучение с подкреплением (англ. reinforcement learning) — один из способов машинного обучения, в ходе которого испытуемая система (агент) обучается, взаимодействуя с некоторой средой.
GAN – генеративно-состязательная нейросеть (Generative adversarial network, GAN) – один из алгоритмов классического машинного обучения, обучения без учителя. Суть идеи в комбинации двух нейросетей, при которой одновременно работает два алгоритма “генератор” и “дискриминатор”. Задача генератора – генерировать образы заданной категории. Задача дискриминатора – пытаться распознать созданный образ.
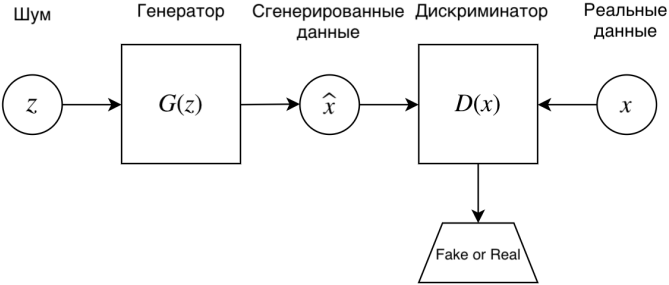
Задача GAN сгенерировать модель, обладающую максимальным правдоподобием.