Файл: Интеллектуальная обработка информации. Искусственный интеллект. Основные вехи развития ии. Примеры практических задач.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 06.12.2023
Просмотров: 50
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Алгоритм (само)обучение GAN:


Сложности при работе с GAN:
-
Несходимость (non-convergance) -
Схлопывание мод распределения (mode collapse): генератор коллапсирует, т.е. выдает ограниченное количество разных образцов -
Исчезающий градиент (diminished gradient): дискриминатор мочит генератора -
Высокая чувствительность к гиперпараметрам
Советы при работе с GAN:
-
Нормализация данных [-1;1] -
Замена функции ошибки для G с min(log(1-D)) на max(logD) -
Batch normalization или layer normalization в G и D* -
Метки для данных, если они имеются, т.е. обучать дискриминатор еще и классифицировать образцы
Примеры GAN:
-
StackGan – порождающая состязательная сеть для генерации фотореалистичных изображений (256*256), исходя из текстового описания. -
LAPGAN – генеративная параметрическая модель, представленная пирамидой лапласианов с каскадом сверточных нейронных сетей внутри, которая генерирует изображения постепенно от исходного изображения с низким разрешением к изображению с высоким. -
PassGAN – генеративно-состязательная сеть для генерации паролей. Обучается на утекших выборках (RockYou, LinkedIn и др.)
- Сверочные нейронные сети. Разновидности слоев сверочных ИНС. Обучаемые параметры сверочных ИHC. Понятие свертки (convolution) и подвыборки (pooling). Ядро свертки, шаг (stride), выравнивание (padding).
Сonvolutional neural network (CNN, ConvNet), или Сверточная нейронная сеть — класс глубоких нейронных сетей, часто применяемый в анализе визуальных образов. Сверточные нейронные сети являются разновидностью многослойного перспептрона с использованием операций свёртки. Они нашли применение в распознавании изображений и видео, рекомендательных системах, классификации изображений, NLP (natural language processing) и анализе временных рядов.
СНС состоит из разных видов слоев: сверточные (convolutional) слои, субдискретизирующие (subsampling, подвыборка) слои и слои «обычной» нейронной сети – персептрона, в соответствии с рисунком 1.
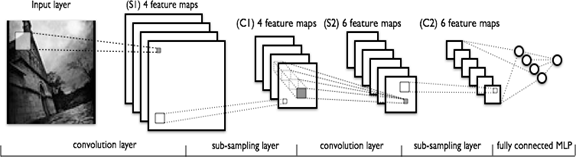
Первые два типа слоев (convolutional, subsampling), чередуясь между собой
, формируют входной вектор признаков для многослойного персептрона.
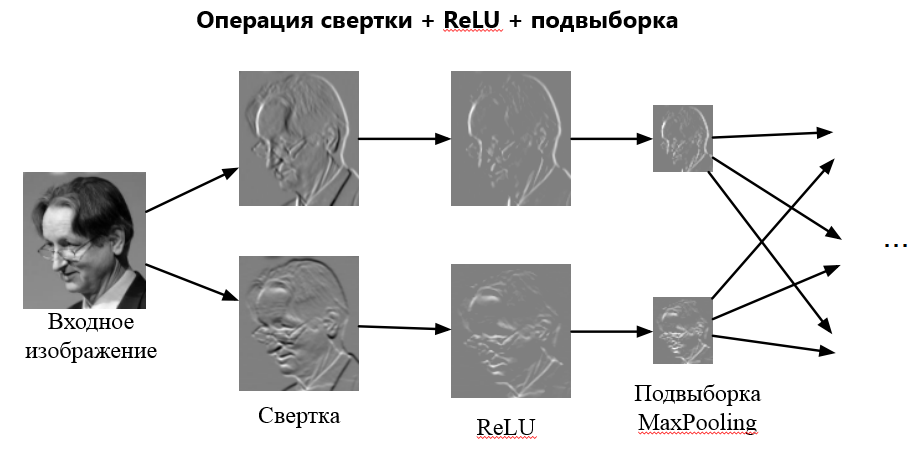
Сверточный слой представляет из себя набор карт (другое название – карты признаков, в обиходе это обычные матрицы), у каждой карты есть синаптическое ядро (в разных источниках его называют по-разному: сканирующее ядро или фильтр).
Количество карт определяется требованиями к задаче, если взять большое количество карт, то повысится качество распознавания, но увеличится вычислительная сложность. Исходя из анализа научных статей, в большинстве случаев предлагается брать соотношение один к двум, то есть каждая карта предыдущего слоя (например, у первого сверточного слоя, предыдущим является входной) связана с двумя картами сверточного слоя, в соответствии с рисунком 3. Количество карт – 6.
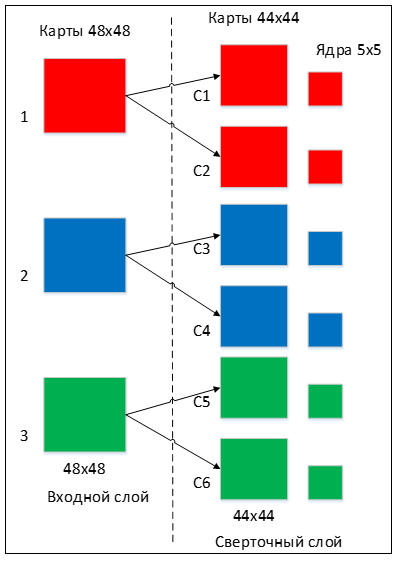
Размер у всех карт сверточного слоя – одинаковы и вычисляются по формуле:

Ядро представляет из себя фильтр или окно, которое скользит по всей области предыдущей карты и находит определенные признаки объектов. Например, если сеть обучали на множестве лиц, то одно из ядер могло бы в процессе обучения выдавать наибольший сигнал в области глаза, рта, брови или носа, другое ядро могло бы выявлять другие признаки. Размер ядра обычно берут в пределах от 3х3 до 7х7. Если размер ядра маленький, то оно не сможет выделить какие-либо признаки, если слишком большое, то увеличивается количество связей между нейронами. Также размер ядра выбирается таким, чтобы размер карт сверточного слоя был четным, это позволяет не терять информацию при уменьшении размерности в подвыборочном слое, описанном ниже.
Ядро представляет собой систему разделяемых весов или синапсов, это одна из главных особенностей сверточной нейросети. В обычной многослойной сети очень много связей между нейронами, то есть синапсов, что весьма замедляет процесс детектирования. В сверточной сети – наоборот, общие веса позволяет сократить число связей и позволить находить один и тот же признак по всей области изображения.
В сверточных нейронных сетях применяется ещё один слой, называемый слоем Pooling. Суть этого слоя заключается в уменьшении размерности карты признаков.
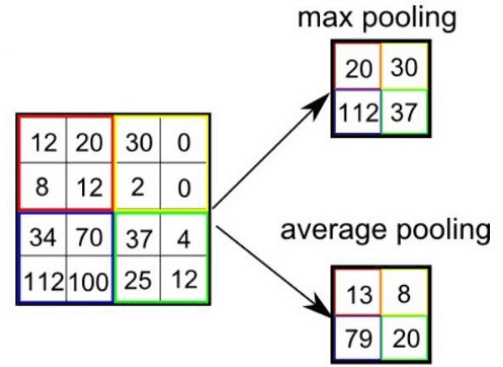
Pooling имеет две разновидности: max-pooling и average-pooling. В большинстве случаев применяется max-pooling. Операция Pooling схожа с операцией свертки:
-
Скользящее окно, обычно это окно (2,2), двигается по карте признаков. -
Из выбранного шаблона выбирается максимальное (max-pooling) или среднее (average-pooling) значение. -
Формируется уменьшенная в размере карта признаков
На рисунке ниже показано, как из матрицы (4,4) получается выходная карта (2,2) после операции max-pooling и average-pooling.
Зачем нужно уменьшать размерность с помощью Pooling? На это есть несколько причин:
-
Для поддержания иерархичности. Архитектура сверточных нейронных сетей похожа на воронку, где все начинается с большой картины с последующим углублением в отдельные детали. Человеческий мозг устроен также: сначала он видит на улице кошку, а затем начинает разглядывать ее цвет, пятна, уши, глаза и т.д. Это является основой Deep learning — обучение на представлениях. -
Уменьшение размерности приводит к уменьшению количества обучаемых коэффициентов, поэтому это ещё и выигрыш в вычислительных ресурсах.
Сверточные нейронные сети смогли завовоевать свою популярность благодаря соответствию иерархичности представлений, поскольку изучаются локальные шаблоны. У CNN есть несколько свойств:
-
Полученные представления являются инвариантными по отношению к переносу. На изображении кошка может находиться в любом доступном месте, а сверточная сеть не запоминает её положения, CNN лишь знает о её представлениях (ушах, глазах и т.д.) -
Модель CNN является пространственно-иерархической. На первых слоях изучаются локальные шаблоны, а последующие изучают шаблоны, полученные из первых слоев.
Можно заметить, что применение операции свертки уменьшает изображение. Также пиксели, которые находятся на границе изображения участвуют в меньшем количестве сверток, чем внутренние. В связи с этим в сверточных слоях используется дополнение изображения (англ. padding). Выходы с предыдущего слоя дополняются пикселями так, чтобы после свертки сохранился размер изображения. Такие свертки называют одинаковыми (англ. same convolution), а свертки без дополнения изображения называются правильными (англ. valid convolution). Среди способов, которыми можно заполнить новые пиксели, можно выделить следующие:
-
zero shift: 00[ABC]00; -
border extension: AA[ABC]CC; -
mirror shift: BA[ABC]CB; -
cyclic shift: BC[ABC]AB.
Еще одним параметром сверточного слоя является сдвиг (англ. stride). Хоть обычно свертка применяется подряд для каждого пикселя, иногда используется сдвиг, отличный от единицы — скалярное произведение считается не со всеми возможными положениями ядра, а только с положениями, кратными некоторому сдвигу s. Тогда, если если вход имел размерность w×h, а ядро свертки имело размерность kx×ky и использовался сдвиг s, то выход будет иметь размерность ⌊(w-kx)/s + 1⌋×⌊(h-ky)/s + 1⌋.
-
Рекуррентные нейронные сети. Область применения и основные архитектуры. Процесс обучения рекуррентных ИHC (понятие backpropagation through time). Примеры использования рекуррентных нейронных сетей.
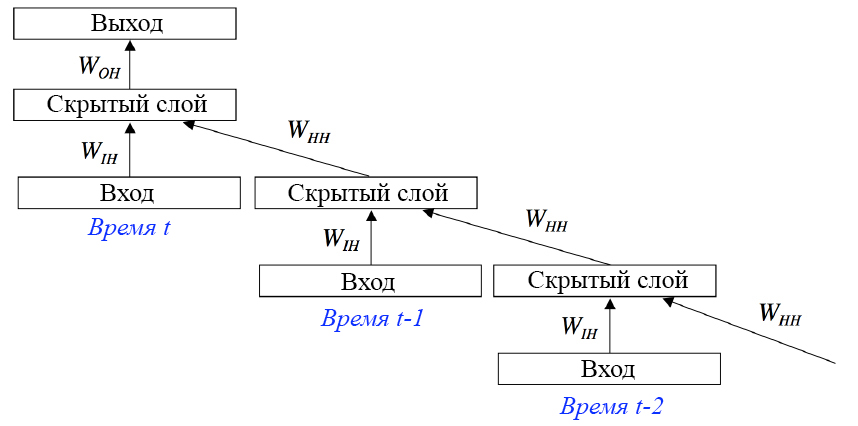
Рекуррентные нейронные сети — сети с циклами, которые хорошо подходят для обработки последовательностей.
Очень часто их применяют для:
-
обработки естественного человеческого языка, -
анализа написанного текста, -
машинного перевода текста, -
генерации текста, -
генерации чисел, -
и др.
При работе с текстами они способны оценивать его грамматическую и семантическую корректность. Рекуррентные нейронные сети способны проанализировать какой-либо текст, а потом на основе этого анализа составить читабельный и похожий на проанализированный текст. Например, можно взять текст А. С. Пушкина, проанализировать его, а потом попробовать сгенерировать похожий текст. Рекуррентные нейронные сети способны будут сделать текст с похожим стилем.
Обучение RNN аналогично обучению обычной нейронной сети. Мы также используем алгоритм обратного распространения ошибки (англ. Backpropagation), но с небольшим изменением. Поскольку одни и те же параметры используются на всех временных этапах в сети, градиент на каждом выходе зависит не только от расчетов текущего шага, но и от предыдущих временных шагов. Например, чтобы вычислить градиент для четвертого элемента последовательности, нам нужно было бы «распространить ошибку» на 3 шага и суммировать градиенты. Этот алгоритм называется «алгоритмом обратного распространения ошибки сквозь время» (англ. Backpropagation Through Time, BPTT).
Используются, когда важно соблюдать последовательность, когда важен порядок поступающих объектов.
-
Обработка текста на естественном языке:
-
Анализ текста; -
Автоматический перевод;
-
Обработка аудио:
-
Автоматическое распознавание речи;
-
Обработка видео:
-
Прогнозирование следующего кадра на основе предыдущих; -
Распознавание эмоций;
-
Обработка изображений:
-
Прогнозирование следующего пикселя на основе окружения; -
Генерация описания изображении
| Один к одному | 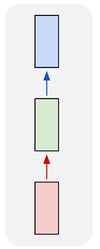 | Архитектура по сути является обычной нейронной сетью. Такой тип нейросети применим, когда на вход поступает единичная информация и на выходе также получается единичная информация. Например, такой подход актуален при кодировании и раскодировании информации. |
| Один ко многим | 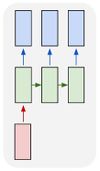 | Один вход ко многим выходам может применяться, например, для генерации аудиозаписи. На вход подаем жанр музыки, который хотим получить, на выходе получаем последовательность аудиозаписи. |
| Многие к одному | 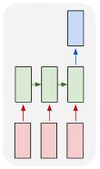 | Много входов и один выход может применяться, если мы хотим оценить тональность рецензии. На вход подаем слова рецензии, на выходе получаем оценку ее тональности: позитивная рецензия или негативная. |
| Многие ко многим | 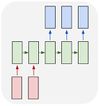 | Данную архитектуру можно использовать для перевода текста с одного языка на другой. |
| Многие ко многим | 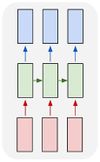 | Такой вариант подойдет для определения для классификации каждого слова в предложении в зависимости от контекста. |
Основные архитектуры:
-
Полностью рекуррентная сеть -
Рекурсивная сеть -
Нейронная сеть Хопфилда -
Двунаправленная ассоциативная память (BAM) -
Сеть Элмана -
Сеть Джордана -
Эхо-сети -
Нейронный компрессор истории -
Сети долго-краткосрочной памяти -
Управляемые рекуррентные блоки -
Двунаправленные рекуррентные сети -
Seq-2-seq сети