Добавлен: 07.12.2023
Просмотров: 204
Скачиваний: 17
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
МИНИСТЕРСТВО СВЯЗИ И МАССОВЫХ КОММУНИКАЦИЙ РОССИЙСКОЙ ФЕДЕРАЦИИ
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ «САНКТ-ПЕТЕРБУГРСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ им. проф. М.А. БОНЧ-БРУЕВИЧА»
ИНСТИТУТ НЕПРЕРЫВНОГО ОБРАЗОВАНИЯ
Курсовая работа
По дисциплине технологии обработки информации
Фамилия: Петров
Имя: Андрей
Отчество: Вячеславович
№ зачетной книжки: 1910642
Группа №: ИБ-06с
Вариант 2
Проверил: _____________
Санкт-Петербург
2023
Оглавление
ВВЕДЕНИЕ 3
Задание 1: Понижение размерности данных 4
Задание 2: Кластеризация данных 7
Задание 3: Обработка графической информации 10
ВВЕДЕНИЕ
Курсовая работа предполагает выполнение трех заданий.
Первое задание относится к изучению технологий понижения размерности анализируемых данных, позволяющих существенно снизить объем обрабатываемой информации.
Для выполнения задания No1 следует изучить литературу, посвященную методу главных компонент, например [1-5] и ознакомиться с доступными библиотеками программ, реализующими данный метод.
Второе задание связано с использованием технологий, позволяющих
оценить возможности качественной кластеризации исследуемого набора данных. Современными эффективными алгоритмами, позволяющими решить подобную задачу, являются алгоритмы t-SNE и UMAP. Для выполнения задания No2 следует изучить особенности реализации данных алгоритмов, например, с использованием материалов ресурсов [6 – 10].
Третье задание позволить приобрести практические навыки в работе с
графической информацией на базе перспективной технологии SVG. Данная
технология тесно сопряжена с языком разметки HTML.
Первое и второе задание может выполняться в любой программной
среде, с использованием любых языков программирования и библиотек. Тем
не менее, рекомендуется использовать среду RStudio и язык программирования R, широко используемых IT-специалистами.
Задание 1: Понижение размерности данных
Исследовать эффективность методов PCA и SVD для понижения размерности данных.
В качестве исходных данных для анализа следует самостоятельно вы-
брать изображение в формате jpg. Размер изображения должен быть не менее
400 х 400 пикселей.
В ходе исследования необходимо проделать следующее:
- выбрать и обосновать количество главных компонент, достаточ-
ное для качественной визуализации;
- оценить выигрыш сжатого изображения по объему, по сравнению
с оригиналом;
- оценить количество «утраченной» информации;
- выяснить зависит ли достаточное число компонент для качествен-
ной визуализации от характера изображения (если да, то оценить
эту зависимость).
Рассмотрим использование метода главных компонент для понижения
размерности изображения и оценим потери визуально. Возьмем небольшой
jpg файл и посмотрим, какое число главных компонент будет достаточным для
представления изображения в допустимом качестве.
Будем вычислять главные компоненты используя сингулярное
разложение матриц, которое выполняется с помощью функции svd,
включенной в базовое программное обеспечение языка R. Эта функция
вычисляет три матрицы S, U и V сингулярного разложения. Их мы будем
использовать как основу и выбирать из них разное число главных компонент
k, формируя сжатые изображения. Качество получаемых изображений будем
оценивать чисто визуально.
Решение задачи выполним в среде RStudio, листинг кода представлен
на рисунке 1.

Рис.1 – Листинг кода программы для понижения размерности
Матрицы S, U и V будем использовать как основу и выбирать из них
разное число главных компонент k. Сформируем различные матрицы Xk,
формирование проведем в цикле для числа компонент k = 50, 150, 300 и 600.
Сначала сформируем усеченные матрицы Uk, Vk и Sk (строки 23-25). Затем в
строке 26 выполним умножение сформированных матриц для формирования
сжатых изображений.
Результатом работы этой программы будет четыре
изображения, отличающихся по качеству (рис. 2):
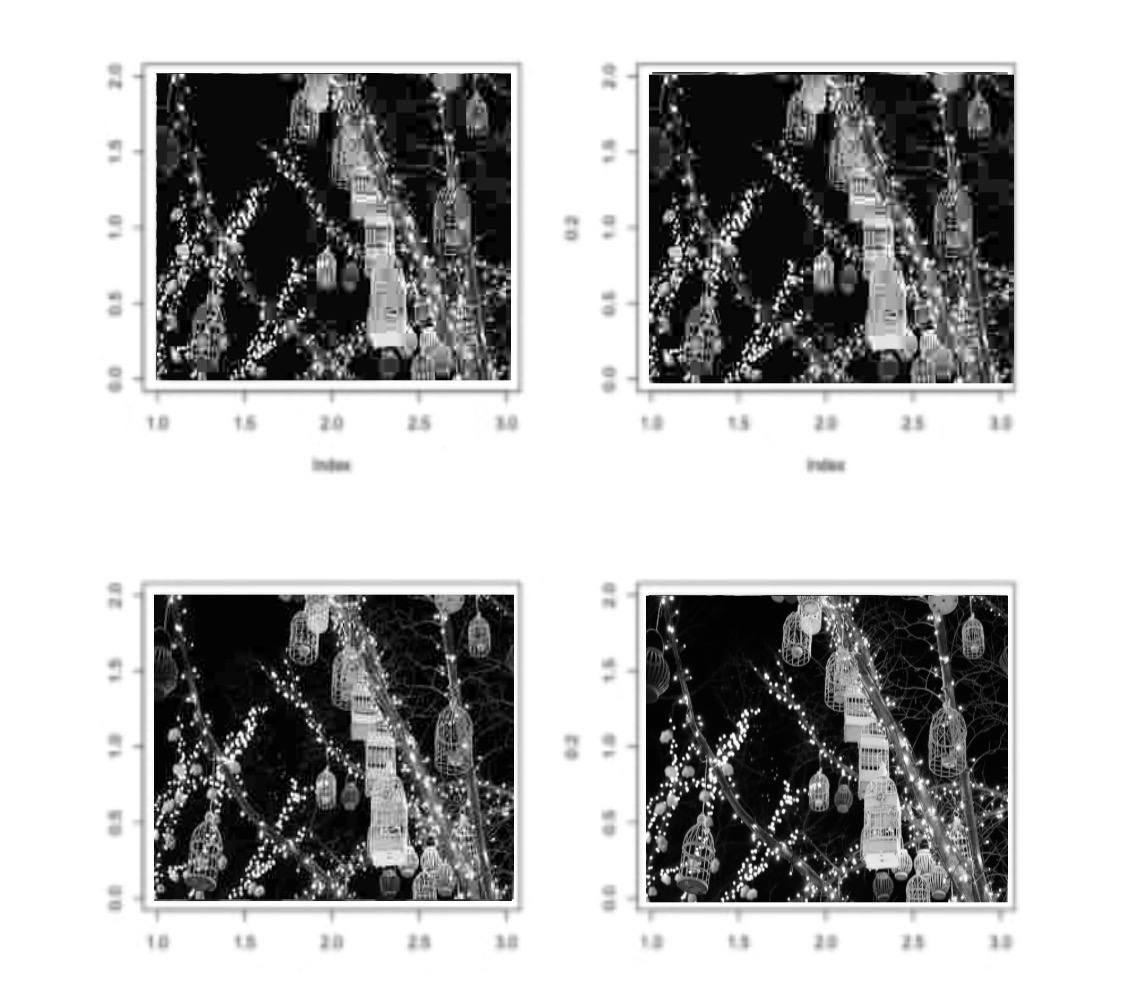
Рис.2 – Изображения для k = 50, 150, 300 и 600
Полагаем, что допустимым качеством обладает изображение для k =
300 сингулярных значений. Посмотрим, какой выигрыш мы можем получить
используя его вместо оригинала (рис.3).
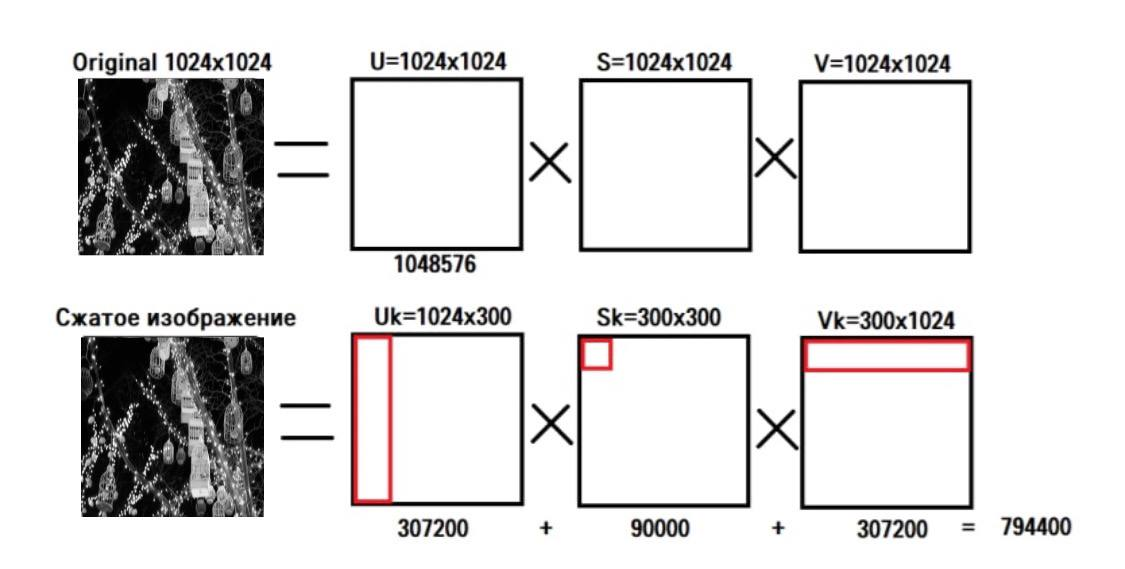
Рис.3 – Сравнение изображений
На рис. 3 приведено такое сравнение, где показано, что вместо 1048576
пикселей нам потребуется всего 794400, то есть выигрыш составляет 1.4 раза
c сохранением всех мелких деталей.
Для оценки количества информации, которое мы потеряем, заменив
оригинальное изображение на сжатое, можно поступить следующим образом.
Если суммарное количество значений всех главных компонент принять
за 100% информационного наполнения оригинала, то сумма значений k
главных компонент сжатого изображения определит его информационное
наполнение.
Разность вычисленных таким образом величин и даст оценку
«потерянной».
Задание 2: Кластеризация данных
Исследовать возможности классификации данных с использованием
алгоритмов t-SNE и UMAP.
Исходные данные для анализа загрузить из ресурса Wine Quality
(http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality /) репози-
тария [10]. Варианты заданий (номер варианта определяется последней циф-
рой номера зачетки) приведены в табл. 2.
Таблица 2
Варианты задания
| Вариант | Обучающая выборка |
| Четная цифра | winequality-red.csv |
| Нечетная цифра | winequality-white.csv |
Анализируемые данные включают 11 объективных параметров различ-
ных сортов вина:
- фиксированная кислотность;
- летучая кислотность;
- лимонная кислота;
- остаточный сахар;
- хлориды;
- свободный диоксид серы;
- общий диоксид серы;
- плотность;
- pH;
- сульфаты;
- спирт.
Последний, 12-ый параметр является субъективной оценкой качества,
проставляемой экспертом и имеет несколько градаций.
Основная задача исследования состоит в определении качества субъективной оценки экспертов и формированию обоснованной кластеризации вин.
Исследование должно содержать:
- описание исследуемого набора данных,
- подготовку данных для анализа,
- план и решаемые задачи,
- выбор используемых функций и описание их параметров,
- результаты исследования,
- аргументированные выводы.
Программный код должен быть снабжен подробным комментарием.
Загружаем необходимые библиотеки и читаем исследуемый файл из рабочего директория. Затем подготавливаем загруженные данные для анализа:
- удаляем неинформативные столбцы;
- преобразуем данные в форму data.table;
- удаляем строки с пропущенными значениями атрибутов.
Рассмотрим использование алгоритма t-SNE для анализа набора данных и сравним его возможности с UMAP.

Использование алгоритма UMAP:

Вывод: использование UMAP позволяет точнее и быстрее решить поставленную задачу. UMAP был разработан не слишком давно и постоянно совершенствуется, однако уже сейчас можно сказать, что по качеству работы он не уступает другим алгоритмам и возможно, наконец, решит основную проблему современных моделей уменьшения размерности — медленность обучения.
Задание 3: Обработка графической информации
Визуализировать отрывок сказки К.И.Чуковского «Муха-цокотуха» с
использованием технологии SVG, соответствующий номеру фрагмента. Но-
мер своего фрагмента определяется последней цифрой номера зачетной
книжки:
Вдруг какой-то старичок
Паучок
Нашу Муху в уголок
Поволок –
Хочет бедную убить,
Цокотуху погубить!
"Дорогие гости, помогите!
Паука-злодея зарубите!
И кормила я вас,
И поила я вас,
Не покиньте меня
В мой последний час!"
Как минимум, созданный фрагмент должен включать анимацию дей-
ствия «героев» с использованием технологии SVG, а также звуковое сопро-
вождение соответствующего фрагмента сказки (его можно вырезать, напри-
мер из https://deti-online.com/audioskazki/skazki-chukovskogo-mp3/muha-
cokotuha/). Звуковое сопровождение должно быть синхронизировано с визу-
альной анимацией.
Сказка детская, поэтому постарайтесь, чтобы реализованный вами сце-
нарий как можно точнее соответствовал текстовому фрагменту, был динами-
чен и красочен.
Результирующий (исполнительный) файл должен иметь расширение
svg. Не забудьте приложить все дополнительные файлы (аудио и, возможно
jpg, png, gif и внешние svg и т.п.) и проверить работоспособность вашего про-
дукта на разных браузерах.
Создание анимационного фрагмента выполним в любом SVG редакторе. В результате получается 3 основные сцены: тараканы, букашки, муха именинница.

Рис.4 – Сцена «Паук приходит»

Рис.5 – Сцена «Гости уходят»

Рис.6 – Сцена «Муха просит о помощи»

Рис.7 – Сцена «Муху гости покидаю»

Рис.8 – Сцена «Муху паук в углу уволок»
Код:
version = "1.1"
xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink"
xmlns:html="http://www.w3.org/1999/xhtml">
]]>
attributeName="x"
from = "50 "
to = "200"
dur="5s"
repeatCount = "2"
begin = "0s"
values="50; 200; 110; 50"
keyTimes="0; 0.5; 0.8; 1"
fill = "freeze"/>
xlink:href="#people"
attributeName="y"
from="50"
to="50"
dur="5s"
repeatCount = "2"
begin="0s"
values="50; 150; 20;150; 70; 150; 110; 50"
keyTimes="0; 0.15; 0.3; 0.45; 0.6; 0.75; 0.9; 1"
fill="freeze"
/>
attributeName="x"
dur = "5s"
repeatCount = "2"
begin = "0s"
values="500; 350; 460; 650"
keyTimes="0; 0.5; 0.8; 1"
fill = "freeze"/>
xlink:href="#people1"
attributeName="y"
dur="5s"
repeatCount = "2"
begin="0s"
values="50; 150; 20;150; 70; 150; 110; 50"
keyTimes="0; 0.15; 0.3; 0.45; 0.6; 0.75; 0.9; 1"
fill="freeze"
/>
attributeName="x"
dur="5s"
repeatCount = "2"
begin = "0s"
values="1100; 1250; 1160; 1250"
keyTimes="0; 0.5; 0.8; 1"
fill = "freeze"/>
xlink:href="#people2"
attributeName="y"
dur="5s"
repeatCount = "2"
begin="0s"
values="50; 150; 20;150; 70; 150; 110; 50"
keyTimes="0; 0.15; 0.3; 0.45; 0.6; 0.75; 0.9; 1"
fill="freeze"
/>
attributeName="x"
dur = "10s"
begin = "0s"
values="100; 300; 500; 800"
keyTimes="0; 0.5; 0.8; 1"
fill = "freeze"/>