Файл: Определение типа личности пользователей социальных сетей с помощью применения технологий больших данных с целью монетизации Аннотация.docx
ВУЗ: Не указан
Категория: Не указан
Дисциплина: Не указана
Добавлен: 09.12.2023
Просмотров: 34
Скачиваний: 1
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
Краснов А.В.
студент 2 курса факультета информационных технологий
Московский политехнический университет
Россия, Москва
Определение типа личности пользователей социальных сетей с помощью применения технологий больших данных с целью монетизации
Аннотация. Результаты психологических исследований показывают, что личность связана с различиями в характеристики дружбы и что некоторые черты личности коррелируют с лингвистическим поведением. В данной работе исследуется влияние, которое личность может оказывать на формирование социальных сетей. Для этого выводятся отношения родства из взаимодействий в социальных сетях, изучается личность на основе использования языка, чтобы обнаружить эмоциональную стабильность отношений родства, и измеряется семантическое сходство на уровне личности, чтобы понять логику, лежащую в основе развития распознавания подгрупп индивидуальности. А именно, проводятся обширные эксперименты, используя общедоступный набор данных, содержащий информацию о различных типов личности.
Ключевые слова: Большие данные, социальные сети, анализ текста, классификация типов личности, лингвистический анализ.
A.V. Krasnov.
2nd year student of the Faculty of Information Technologies
Moscow Polytechnic University
Russia, Moscow
Annotation. The results of psychological research show that personality is related to differences in friendship characteristics and that some personality traits correlate with linguistic behavior. This paper investigates the influence that personality can have on the formation of social networks. This is done by deriving relatedness relationships from social network interactions, examining personality based on language use to discover the emotional stability of relatedness relationships, and measuring semantic similarity at the personality type level. at the personality type level to understand the logic underlying the development of personality type recognition. Namely, extensive experiments are conducted using a publicly available dataset containing information about different personality types.
Keywords: Big Data, social media, text analysis, personality type classification, linguistic analysis.
ВВЕДЕНИЕ
С практической точки зрения, исследование привлекательности и личности представляет интерес не только для психологии, но и для коммерческого применения
, в том числе в службах психического здоровья для понимания психологических аспектов и последствий психических заболеваний для отдельных пациентов и социальных систем. Сочетание привлекательности и личностных качеств позволяет понять, как индивиды со схожими чертами характера и качествами развивают свою близость, и определить, что привлекает одного человека к другому
Социальная сеть (от англ. social networks) — это интернет-площадка, позволяющая зарегистрированным пользователям рассказывать информацию, делиться своими фотографиями, вести посты и коммуницировать между собой, устанавливая социальные взаимоотношения и связи. Контент на таких интернет - площадках, генерируется самими пользователями, в зависимости от предпочтений и подборок групп.
Актуальность исследования заключается в совершенствовании методов определение типа личности пользователей социальных сетей с помощью применения технологий больших данных.
Объектом исследования послужили теоретические и практические разработки в применении различных моделей определения типов личностей.
Предмет исследования — теоретические и методологические аспекты применения статистических методов в анализе типов личности.
В результате исследования должны быть проанализированы данные определения типов личности, а также модели их распознания. Полученные модели должны применяться для использования в социальных сетях с последующей монетизацией.
Определения типа личности, традиционно применяется маркетологами для последующего таргетированного предложения специально для конкретного человека.
В большинстве исследований личности используются опросники (и/или письменные эссе) для оценки личных поведенческих предпочтений. Такой подход по своей сути препятствует проявлению индивидуальных черт и затрудняет отслеживание использования языка и взаимодействия между испытуемыми. Чтобы эффективно провести анализ использования языка между людьми на основе их типов личности, необходимо чтобы данные были предварительно аннотированы. Следует отметить, что аннотированные вручную наборы данных являются дорогостоящими и труднодоступными. Чтобы преодолеть ограничение, связанное с небольшим размером аннотированных образцов данных и закрытого словарного запаса, было решено использовать данные, собранные из социальных сетей.
ОСНОВНАЯ ЧАСТЬ
Для данного исследования был подготовлен набор данных, состоящий из твитов людей
, которые публично причисляли себя к одному из 16 типов личности MBTI. типов. В частности, используя собранные твиты, содержащие любой из 16 типов личности MBTI плюс термины "MBTI", "Бриггс" и/или "Майерс". По соображениям конфиденциальности и этических соображений, было принято решение избегать отображения персонально идентифицируемой информации, особенно имен и псевдонимов. Следовательно, в датасетах нужно было произвольно заменить такую информацию, чтобы обеспечить анонимность и конфиденциальность данных. Таким образом было подготовлено два набора данных.
Набор данных А. Для обработки данных мы удалили твиты, написанные не на русском языке. Мы исключили ретвиты и все твиты, содержащие более одного типа личности, и удалили лишние твиты. Мы использовали Botometer1 веб-инструмент, который использует машинное обучение для классификации аккаунтов в Twitter как ботов или людей. таких характеристик, как друзья, структура социальной сети, временная активность, язык и настроение. Botometer выдает общий балл ботов наряду с несколько других оценок, которые позволяют оценить вероятность того, что аккаунт является ботом. Оценки ботов выставляются по шкале от 0 до 5, где ноль - наиболее человекоподобным, а пять - наиболее похожим на бот. Мы поэтому произвольно удалили всех пользователей, для которых общая оценка ботов выше 2,5. Мы считаем, что аккаунты с оценкой 2,5 находятся в середине шкалы, и эти аккаунты находятся на относительно нейтральной территории. Может быть трудно классифицировать бота с оценкой 2,5 как человека или бота. По этой причине мы считаем ботом любой аккаунт, у которого общий балл бота больше или равный 2,5. Это делается для того, чтобы обеспечить надежный сбор данных. Для того чтобы тщательно изучить использование языка использование и то, как оно варьируется в зависимости от типа личности, мы отбросили все твиты, принадлежащие одному и тому же пользователю, в которых типы личности MBTI разные. В целом, мы извлекли 758 426 твитов, для того же количества пользователей.
Набор данных B. Поскольку алгоритм родства полагается в значительной степени на упоминания между пользователями, были извлечены самые последние твиты (до 200) для каждого идентифицированного пользователя из набора данных A. В частности, было получено в общей сложности 25 253 604 твитов, в среднем 33 твита на пользователя. Считается, что в этих твитах пользователи с большей вероятностью используют спонтанный язык в различных контекстах для самовыражения, чем когда они отчитываются или рассказывают о своем типе личности MBTI в одном твите. Среднее количество слов в наборе данных A составляет 27 на пользователя, в то время как в наборе данных B - 4 843 на пользователя. Поэтому было взято все твиты в наборе данных B для каждого пользователя и помечено с помощью MBTI тип личности. Аннотация набора данных B облегчает извлечение поведенческих моделей, связанных с каждым типом личности MBTI, для разработки модели, которая может предсказать личность.
Возьмем набор пользователей, которые публично самоидентифицировались с типом личности MBTI по набору данных А, и проверяем, существуют ли между ними связи. Для этого мы рассматриваем упоминания в наборе данных B, чтобы найти твиты, которые связывают этих пользователей друг с другом. связывают этих пользователей друг с другом. Получается всего 3 481 737 твитов, содержащих упоминания, т.е. то есть 13,8% от всего набора данных В. Мы особенно заинтересованы в отслеживании и изучении социальных упоминания. Алгоритм привлекательности, а также HAR-поиск, использует упоминания для эффективного понимания их последствий в социальных взаимодействиях, включая настроения и контекст, в котором упоминания были пометки в потоках обсуждения, чтобы вывести отношения родства. После каждого тестирования проводилось изменение обучающей и тестовой выборок, и формировалась новая оценка изменения, которая служила для расчета новой цели.
Данная техника обучения называется «метод последовательных приближений». Отношения привлекательности в основном можно наблюдать по ряду характеристик, включая взаимное взаимопонимание, взаимные и общие интересы, симпатию, гармоничное общение и согласие между людьми. В данной работе был использован HAR-поиск для получения оценки родства между пользователями из онлайн-дискуссий. В частности, HAR-поиск учитывает упоминания и поток обсуждений, чтобы уловить мельчайшие детали и контексты взаимодействий на основе их временной последовательности. HAR-поиск извлекает релевантные сигналы близости из взаимодействий, основываясь на их настроения и контекста, а затем моделирует эти сигналы в виде последовательностей. Модели цепей Маркова затем используются для количественной оценки этих последовательностей, чтобы для получения оценок привлекательности. Эти показатели обозначают степень родства между парой пользователей. Обоснованием для использования HAR-поиска является то, что он облегчает создание матрицы вероятностей марковского перехода для построения графа родства и отслеживания эволюцию привлекательности между людьми с течением времени, чтобы предсказать отношения родства, возникающие в результате влияния определенных лиц в онлайн-сообществе. Одним из дополнительных преимуществ ценностей HAR-поиска является его способность отслеживать временную эволюцию отношений родства. HAR-поиск исследует эволюцию отношений между индивидуумами через их показатель привлекательности путем изучая, остается ли этот показатель постоянным, увеличивается или уменьшается в любой момент времени.
Для измерения эмоциональной стабильности в отношениях близости между двумя различными типами личности, исследуется использование языка в их дискуссиях. использование языка в их дискуссионных взаимодействиях и используем систему лингвистического исследования и подсчета слов (LIWC) систему анализа текста для извлечения психолингвистических особенностей. LIWC — это широко используемая, психометрически проверенная система для психологического анализа языка и классификации слов. анализа языка и классификации слов. На сайте Словарь LIWC включает категории слов, которые имеют предварительно обозначенные значения, созданные психологами. Категории LIWC также были независимой оценке на предмет их корреляции с психологическими концепциями.
Корреляции Пирсона между признаками LIWC (негативные эмоции), извлеченными на основе использования языка, для выявления эмоциональной стабильности между двумя различными типами личности. выявления эмоциональной стабильности в родстве между двумя различными типами личности. Все корреляции значимы при p < 0,01.
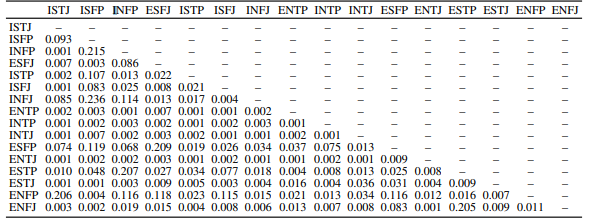
Рисунок 1 – Корреляция между признаками
INFP, ENFJ и INFJ имеют уровень удовлетворенности в 73% в паре друг с другом. Эти типы склонны придают большое значение отношениям и наиболее склонны из всех типов посвятить себя здоровым отношениям и открытому общению.
Применяя самоидентифицированные типы пользователей социальных сетей типы и изучая их спонтанный язык, были извлечены лингвистические паттерны, используя пять различных классификаторов для предсказания 16 типов личности MBTI. Полученные результаты очень обнадеживают и показывают, что наши классификаторы могут эффективно предсказывать личность с высокой точностью. В частности, большинство лучших результатов были достигнуты в классификаторе BERT. BERT предсказал личность, не только учитывая самоотчеты о типах и классов, но также улавливая контекст, в котором текстовый корпус, связанный с каждым классом типа, был выражен. Чтобы проверить эффективность используемых классификаторов, рассмотрены самоидентифицированные типы как в качестве базовых истин. Основное преимущество использования самоидентифицированных типов в качестве базовых истин является их способность действовать в качестве немедленной проверки. Но также стоит признать, что личность человека может развиваться и меняться с течением времени