Добавлен: 29.10.2018
Просмотров: 48198
Скачиваний: 190

Гл а в а 8
.
Многопроцессорные системы
С первых дней своего существования компьютерная промышленность постоянно стре-
милась к достижению все большей и большей вычислительной мощности. Компьютер
ENIAC мог выполнять 300 операций в секунду, с легкостью тысячекратно обставляя
любой предшествующий ему калькулятор, но людей и это не устраивало. Быстродей-
ствие современных машин в миллионы раз превышает возможности ENIAC, но есть
потребности в еще большей мощности. Астрономы пытаются постичь суть Вселенной,
биологи хотят разобраться в геноме человека, а авиаконструкторы заинтересованы
в создании надежных и более экономичных самолетов, и всем им нужна более высо-
кая скорость работы центральных процессоров. Какими бы мощными ни становились
компьютеры, их мощности все равно не хватает.
В прошлом проблема всегда решалась за счет повышения тактовой частоты. К со-
жалению, этому повышению уже начинает препятствовать ряд фундаментальных
ограничений. В соответствии с положениями специальной теории относительности
Эйнштейна электрический сигнал не может распространяться быстрее скорости света,
равной в вакууме примерно 30 см/нс, а в медном проводнике или в оптическом кабеле
скорость распространения сигнала равняется примерно 20 см/нс. Из этого следует,
что на компьютере с тактовой частотой 10 ГГц сигнал не может преодолеть за один
такт суммарное расстояние, превышающее 2 см. Для компьютера с тактовой часто-
той 100 ГГц максимальная суммарная длина пути равна 2 мм. Компьютер с тактовой
частотой 1 ТГц (1000 ГГц) должен быть меньше 100 мкм (0,1 мм), чтобы сигнал мог
добраться с одного его конца до другого за один такт.
Уменьшить компьютеры до таких размеров, может быть, и возможно, но тогда пре-
пятствием станет другая фундаментальная проблема: отвод тепла. Чем быстрее ком-
пьютер, тем больше тепла он выделяет, а чем он меньше, тем труднее от этого тепла
избавиться. Уже сейчас на мощных x86-системах системы охлаждения, установленные
на процессоре, больше самого процессора. В конечном счете переход с частоты 1 МГц
к частоте 1 ГГц потребовал последовательного совершенствования технологии произ-
водства микросхем. А переход с частоты 1 ГГц на частоту 1 ТГц потребует, скорее всего,
совершенно иных подходов.
Один из подходов к увеличению скорости состоит в широкомасштабном применении
параллельных вычислительных систем. Эти системы содержат множество централь-
ных процессоров, каждый из которых работает на обычной частоте (какое бы значе-
ние она ни имела в данное время), но по сравнению с отдельно взятым процессором
все вместе они обладают куда более высокой вычислительной мощностью. Сейчас
уже продаются системы, состоящие из десятков тысяч центральных процессоров.
А в лабораториях уже созданы системы с 1 млн центральных процессоров (Furber et
al., 2013). Хотя существуют и другие потенциальные подходы к увеличению скорости
работы компьютеров, например биологические компьютеры, в данной главе внимание

Многопроцессорные системы
577
будет сосредоточено на системах, состоящих из множества обычных центральных
процессоров.
Компьютеры с высокой степенью параллельности вычислений часто используются
для высокопроизводительных численных расчетов. Задачи прогнозирования погоды,
моделирования воздушных потоков, обтекающих крыло самолета, моделирования
процессов мировой экономики или раскрытия механизмов взаимодействия лекар-
ственных средств с рецепторами мозга требуют больших вычислительных мощностей.
Для решения этих задач требуется одновременная продолжительная работа множества
центральных процессоров. Многопроцессорные системы, рассматриваемые в данной
главе, широко используются для решения этих и сходных с ними задач в науке, про-
мышленности, а также других областях человеческой деятельности.
Еще одна имеющая отношение к изучаемому вопросу область развития — это невероят-
но бурный рост сети Интернет. Эта сеть первоначально была разработана как прототип
высокоустойчивой системы управления войсками, затем завоевала популярность в на-
учной компьютерной среде и давно уже приобрела множество новых пользователей.
Одно из применений Интернета состоит в объединении в едином рабочем простран-
стве нескольких тысяч компьютеров по всему миру для решения широкомасштабных
научных задач. В известном смысле система, состоящая из тысячи компьютеров,
рассредоточенных по всему миру, не отличается от системы, состоящей из тысячи
компьютеров, находящихся в одном помещении, хотя задержки по времени и другие
технические характеристики у этих двух систем различаются. Эти системы также будут
рассмотрены в данной главе.
Нетрудно будет поставить в одной комнате миллион не связанных между собой
компьютеров при условии, что вам хватит на это средств, а комната будет достаточно
большой. Разместить миллион компьютеров по всем миру еще легче, поскольку при
этом не нужно искать для них подходящую комнату. Проблемы начинаются, когда
нужно организовать обмен данными между компьютерами для совместной работы при
решении единой задачи. Поэтому был проделан большой объем работы по разработке
технологии соединения компьютеров, а различные технологии соединения привели
к качественно отличающимся друг от друга типам систем и различным организациям
программного обеспечения.
Весь обмен данными между электронными (или оптическими) компонентами в ко-
нечном итоге сводится к обмену сообщениями — четко определенными битовыми
строками. Разница заключается в используемых масштабах времени, расстояния
и логической организации. На одном полюсе находится многопроцессорная система
с общим пространством памяти, где от двух до тысячи центральных процессоров об-
мениваются данными через общую память. В этой модели каждый центральный про-
цессор имеет равный доступ ко всей физической памяти и может читать и записывать
отдельные слова, используя команды LOAD и STORE. Доступ к слову памяти обычно
занимает 1–10 нс. Как вскоре будет показано, сейчас уже нет ничего необычного в по-
мещении на один кристалл центрального процессора более одного вычислительного
ядра с предоставлением ядрам совместного доступа к основной памяти (а иногда даже
и к совместным блокам кэш-памяти). Иными словами, модель мультикомпьютеров
может быть реализована с использованием физически отдельных центральных про-
цессоров, нескольких ядер на одном центральном процессоре или комбинации из вы-
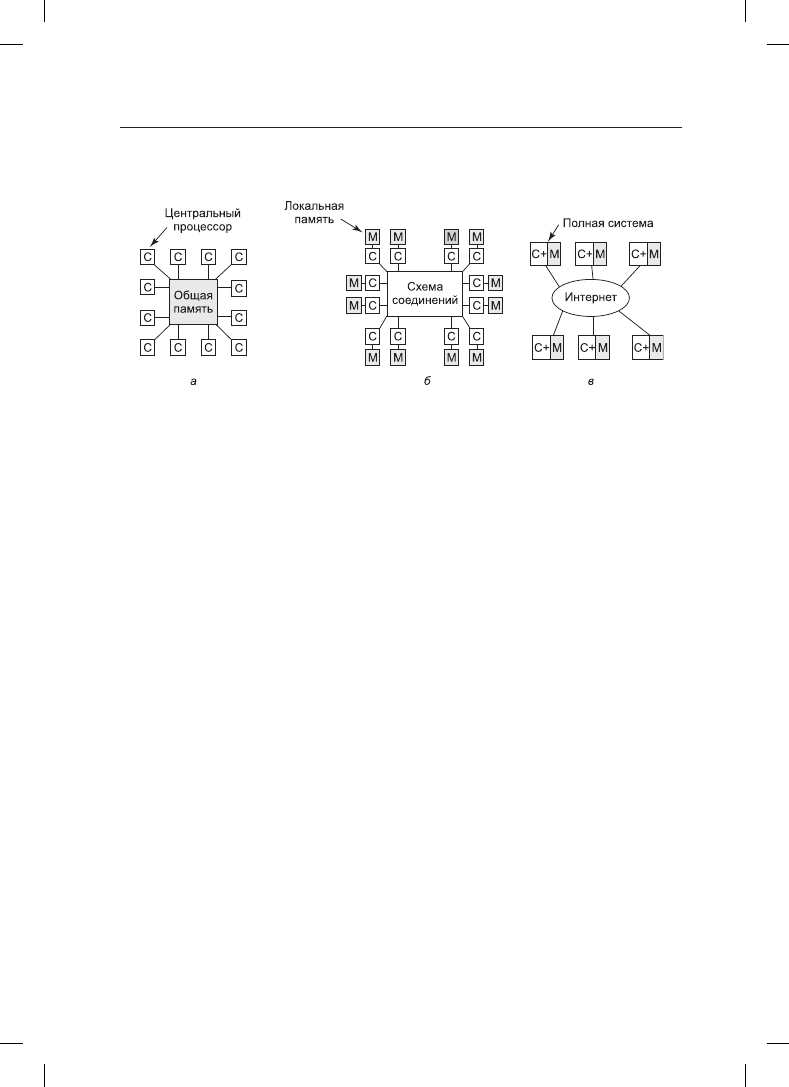
шеперечисленного. При кажущейся простоте эта модель (рис. 8.1, а) реализуется не
так-то просто и обычно включает в себя передачу большого количества защищенных
578
Глава 8. Многопроцессорные системы
сообщений, на чем мы кратко остановимся в дальнейшем. Но эта передача сообщений
невидима для программистов.
Рис. 8.1. Мультипроцессорная система: а — с общей памятью; б — с передачей сообщений;
в — глобальная распределенная система
Следом идет система (рис. 8.1, б), в которой несколько пар «процессор — память»
соединены друг с другом высокоскоростной схемой. Эта разновидность называется
мультипроцессорной системой с передачей сообщений. Каждый модуль памяти явля-
ется локальным по отношению к одному центральному процессору, и доступ к нему
можно получить только через этот центральный процессор. Центральные процессоры
связываются друг с другом путем отправки сообщений через схему соединений. При
наличии качественной схемы соединений короткие сообщения могут быть отправлены
за 10–50 мс, что намного превышает время доступа к памяти в системе, показанной на
рис. 8.1, а. В этой конструкции не используется общая глобальная память. Мульти-
процессорные компьютеры (то есть системы с передачей сообщений) намного проще
в создании, чем мультипроцессоры (системы с общей памятью), но они труднее в про-
граммировании. Поэтому у каждой разновидности есть свои поклонники.
Третья модель (рис. 8.1, в) объединяет полноценные компьютерные системы по гло-
бальной сети, такой как Интернет, с целью формирования распределенной системы
(distributed system). У каждой из этих систем имеется собственная оперативная память,
и системы связываются друг с другом путем отправки сообщений. Единственное ре-
альное отличие друг от друга систем, показанных на рис. 8.1, б и в, заключается в том,
что в последней из них используются полноценные компьютеры, а время передачи
сообщений часто составляет 10–100 мс. Столь длительные задержки вынуждают ис-
пользовать эти так называемые слабосвязанные (loosely coupled) системы несколько
по-другому, нежели сильносвязанные (tightly coupled) системы (см. рис. 8.1, б). Время
задержки у этих трех разновидностей систем различается практически на три порядка.
Такая же разница между одним днем и тремя годами.
Эта глава состоит из трех основных разделов, каждый из которых соответствует трем
моделям, показанным на рис. 8.1. Для каждой модели, рассматриваемой в данной главе,
сначала дается небольшое введение в соответствующее аппаратное обеспечение. Ос-
новной упор делается на программное обеспечение, особенно на вопросы, касающиеся
операционной системы для рассматриваемой разновидности системы. Будет показано,
что у каждой разновидности имеются свои особенности, требующие применения раз-
личных подходов.

8.1. Мультипроцессоры
579
8.1. Мультипроцессоры
Мультипроцессор с общей памятью
(shared-memory multiprocessor), далее просто
мультипроцессор, — компьютерная система, в которой два и более центральных про-
цессора имеют полный доступ к общей оперативной памяти. Программа, запущенная
на любом из центральных процессоров, видит обычное виртуальное пространство
(имеющее, как правило, страничную организацию). Единственное необычное свойство,
присущее этот системе, заключается в том, что центральный процессор может записать
какое-нибудь значение в слово памяти, а затем считать это слово и получить другое
значение (потому что другой центральный процессор его уже изменил). При должной
организации это свойство формирует основу для межпроцессорного обмена данными:
один центральный процессор записывает какие-нибудь данные в память, а другой их
считывает из памяти.
Большей частью мультипроцессорные операционные системы мало чем отличаются от
обычных. Они обрабатывают системные вызовы, осуществляют управление памятью,
предоставляют файловую систему и управляют устройствами ввода-вывода. Тем не
менее есть ряд областей, где они обладают уникальными особенностями. Эти области
включают синхронизацию процессов, управление ресурсами и планирование. Далее мы
сначала дадим краткий обзор мультипроцессорного аппаратного обеспечения, а затем
перейдем к вопросам, касающимся операционных систем.
8.1.1. Мультипроцессорное аппаратное обеспечение
Хотя у всех мультипроцессоров имеется свойство, позволяющее каждому центральному
процессору обращаться ко всему пространству памяти, у некоторых мультипроцессоров
есть еще одно свойство: каждое слово памяти может быть считано так же быстро, как
и любое другое слово памяти. Такие машины называются UMA-мультипроцессорами
(Uniform Memory Access — однородный доступ к памяти). В противоположность
им NUMA-мультипроцессоры (Nonuniform Memory Access — неоднородный доступ
к памяти) этим свойством не обладают. Далее станет ясно, почему существует такое
различие. Сначала будут рассмотрены UMA-мультипроцессоры, а затем NUMA-
мультипроцессоры.
UMA-мультипроцессоры с шинной архитектурой
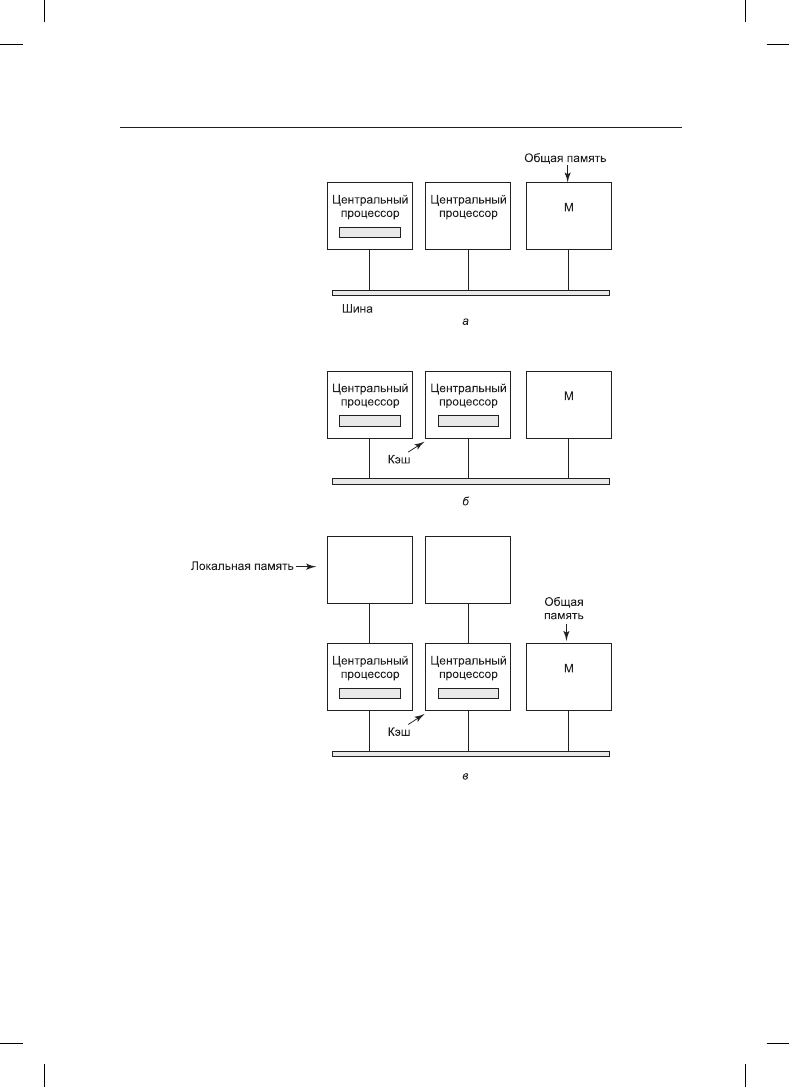
Простейшие мультипроцессоры (рис. 8.2, а) основаны на использовании общей шины.
Два и более центральных процессора и один и более модулей памяти используют для
обмена данными одну и ту же шину. Когда центральному процессору нужно считать
слово памяти, он сначала проводит проверку занятости шины. Если шина не занята,
центральный процессор выставляет на ней адрес нужного ему слова, подает несколько
управляющих сигналов и ждет, пока память не выставит нужное слово на шину.
Если шина занята, то центральный процессор, которому нужно считать слово или за-
писать его в память, просто ждет, пока шина освободится. Именно в этом и заключается
проблема такой архитектуры. При наличии двух или трех центральных процессоров
спор за шину будет вполне управляемым, чего нельзя сказать о 32 или 64 процессорах.
Система будет полностью ограничена пропускной способностью шины, а основная
масса центральных процессоров будет простаивать большую часть времени.
580
Глава 8. Многопроцессорные системы
Рис. 8.2. Мультипроцессоры с общей шиной: а — без кэш-памяти; б — с кэш-памятью;
в —с кэш-памятью и собственной памятью процессора
Решение этой проблемы показано на рис. 8.2, б и заключается в добавлении к каждо-
му центральному процессору кэш-памяти. Эта память может располагаться внутри
микросхемы центрального процессора, соседствовать с этой микросхемой, находиться
на общей плате или быть представлена комбинацией из трех перечисленных вариан-
тов. Поскольку многие операции чтения теперь могут быть удовлетворены за счет
локальной кэш-памяти, существенно сократится объем данных, передаваемых по
шине, и система сможет поддерживать большее количество центральных процессоров.