Добавлен: 29.10.2018
Просмотров: 48194
Скачиваний: 190
586
Глава 8. Многопроцессорные системы
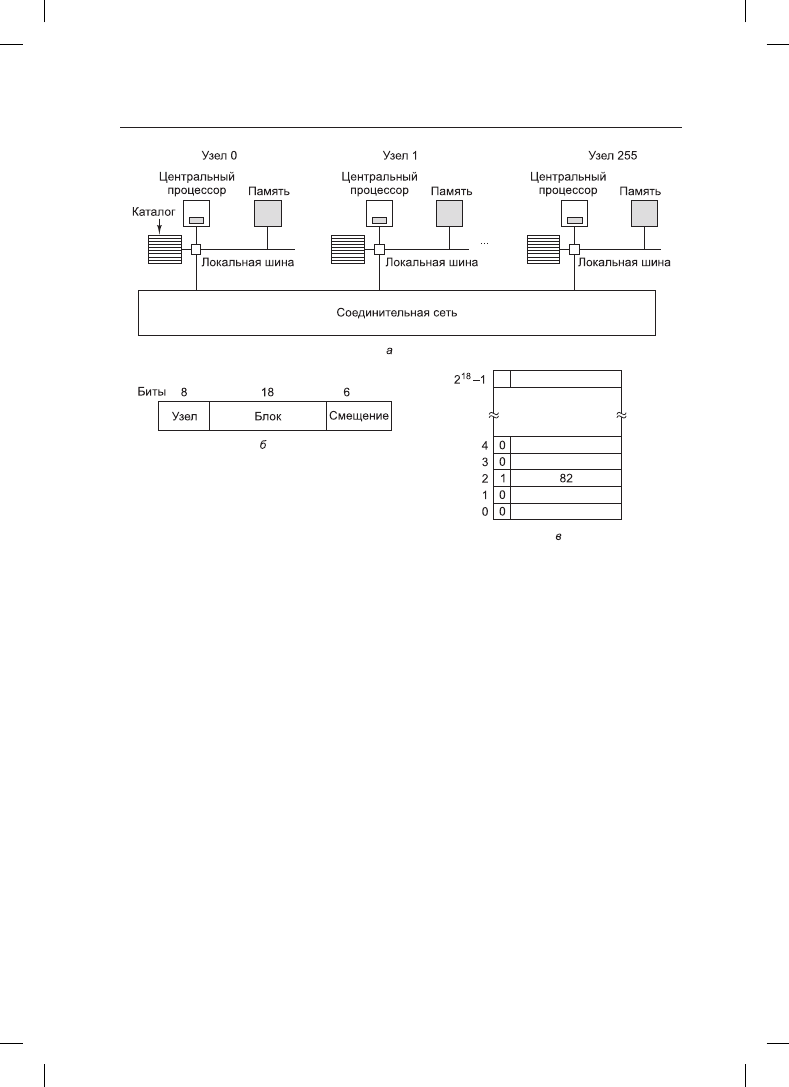
Рис. 8.6. а — мультипроцессор на основе каталогов, содержащий 256 узлов; б — разделение
32-разрядного адреса памяти на поля; в — каталог в узле 36
осуществляет преобразование команды в физический адрес, например 0x24000108.
MMU разбивает этот адрес на три части, показанные на рис. 8.6, б. В десятичной форме
эти три части представляют собой узел 36, строку 4 и смещение 8. Блок управления па-
мятью видит, что слово памяти, на которое делается ссылка, из узла 36, а не из узла 20,
поэтому он отправляет сообщение с запросом через схему соединений к узлу 36, вы-
ясняя, находится ли эта строка 4 в кэше, и если да, то где именно.
Когда запрос по схеме соединений поступает к узлу 36, он направляется к аппарату-
ре каталога. Эта аппаратура обращается по индексу в свою таблицу, состоящую из
2
18
запи сей, по одной для каждой своей кэш-строки, и извлекает запись 4. На рис. 8.6, в
показано, что строки в кэше нет, поэтому аппаратура извлекает строку 4 из локальной
оперативной памяти, отправляет ее обратно узлу 20 и обновляет запись каталога 4,
показывая, что теперь строка находится в кэше на узле 20.
Рассмотрим второй запрос, на этот раз касающийся строки 2 узла 36. На рис. 8.6, в
показано, что эта строка присутствует в кэше на узле 82. В этот момент аппаратура
может обновить запись каталога, чтобы она сообщала, что строка теперь находится на
узле 20, а затем отправить сообщение узлу 82, предписывая ему передать строку узлу
20 и аннулировать свой кэш. Заметьте, что даже так называемый мультипроцессор
с общей памятью не обходится без передачи на внутреннем уровне большого количе-
ства сообщений.
В качестве небольшого отступления подсчитаем, сколько памяти уходит на каталоги.
У каждого узла имеется 16 Мбайт оперативной памяти и 2
18
записей длиной 9 бит для

8.1. Мультипроцессоры
587
ведения учета этой памяти. Итак, на каталог уходит около 9 · 2
18
бит на 16 Мбайт, или
около 1,76 %, что вполне приемлемо (если не обращать внимания на то, что это должна
быть высокоскоростная память, что, разумеется, повышает ее стоимость). Даже если
использовать кэш-строки длиной 32 байта, издержки составят только 4 %. При кэш-
строках длиной 128 байт они будут меньше 1 %.
Несомненная ограниченность такой схемы состоит в том, что строка может быть кэ-
ширована только в одном узле. Чтобы кэшировать строки на нескольких узлах, нужны
какие-то способы их обнаружения, для того чтобы, к примеру, аннулировать или обно-
вить их при записи. Поэтому на многих многоядерных процессорах запись каталога со-
стоит из битового вектора, по одному биту на ядро. Значение 1 свидетельствует о том,
что строка кэша присутствует в ядре, а значение 0 свидетельствует об ее отсутствии.
Более того, в каждой записи каталога обычно содержится несколько дополнительных
битов. В результате этого расходы памяти на каталог существенно возрастают.
Многоядерные микропроцессоры
По мере совершенствования технологии производства микросхем транзисторы стано-
вились все меньше и меньше, и появилась возможность размещать их на микросхемах
все в большем и большем количестве. Это эмпирическое наблюдение часто называют
законом Мура
в честь одного из основателей компании Intel Гордона Мура (Gordon
Moore), который первым отметил эту особенность. В 1974 году процессор Intel 8080
содержал чуть более 2 тысяч транзисторов, а центральные процессоры Xeon Nehalem-
EX содержат более 2 млрд транзисторов.
Возникает резонный вопрос: как распорядиться всеми этими транзисторами? В раз-
деле главы 1, посвященном процессорам, в качестве одной из возможностей рассма-
тривалось увеличение емкости кэш-памяти, размещенной на кристалле процессора.
Это весьма ценная возможность, и уже повсеместно используются процессоры, име-
ющие в своем составе кэш-память объемом 4–32 Мбайт. Но существует мнение, что
увеличение размера кэш-памяти может поднять максимальную производительность
всего лишь с 99 до 99,5 %, а это не сможет существенно увеличить производительность
работы приложения.
Другая возможность заключается в размещении на одной и той же микросхеме (тех-
нически на одном и том же кристалле) двух и более полноценных центральных про-
цессоров, обычно называемых ядрами (cores). Сейчас уже никого не удивишь двухъ-
ядерными, четырехъядерными и восьмиядерными процессорами, размещенными на
одном кристалле, и можно даже купить процессоры, имеющие несколько сотен ядер.
Несомненно, на подходе процессоры с еще большим количеством ядер. По-прежнему
актуален вопрос относительно кэш-памяти. Например, у процессора Intel Xeon 2651
имеюся 12 физических многопотоковых ядер, благодаря которым создаются 24 вир-
туальных ядра. Каждое из 12 физических ядер имеет 32-килобайтный кэш уровня L1,
предназначенный для инструкций и 32-килобайтный кэш L1 для данных. У каждого
из них также имеется 256-килобайтный кэш уровня L2. И наконец, 12 ядер совместно
используют 30-мегабайтный кэш уровня L3.
Наряду с тем, что центральные процессоры могут иметь, а могут и не иметь общие мо-
дули кэш-памяти (см. рис. 1.8), оперативную память они всегда используют совместно,
и эта память обладает согласованностью в том смысле, что у каждого слова памяти
всегда имеется однозначное значение. Для поддержки согласованности специальная

588
Глава 8. Многопроцессорные системы
схема обеспечивает режим работы, при котором изменение одним из центральных про-
цессоров слова, присутствующего в двух или более кэшах, приводит к автоматическому
и атомарному удалению его из всех кэшей. Этот процесс известен как отслеживание
(snooping).
В результате такой конструкции многоядерные микросхемы становятся миниатюрны-
ми мультипроцессорами. На практике многоядерные микросхемы иногда называют
мультипроцессорами на уровне микросхемы (Chip-level MultiProcessors (CMP)).
С точки зрения программирования CMP практически не отличаются от мультипро-
цессоров с общей шиной или мультипроцессоров, использующих схемы коммутации.
Но некоторые различия все же имеются. Прежде всего у мультипроцессоров с общей
шиной у каждого центрального процессора имеется собственный кэш, показанный на
рис. 8.2, б, и это совпадает с конструкцией AMD, показанной на рис. 1.8, б. А конструк-
ция с общей кэш-памятью, использующаяся компанией Intel во многих ее процессорах
и показанная на рис. 1.8, а, в других мультипроцессорах не встречается. Общая кэш-
память второго или третьего уровня (L2 или L3) может нанести вред производитель-
ности. Если одному из ядер требуется большой объем кэш-памяти, а другим — нет, то
эта конструкция позволяет осуществить захват кэш-памяти, чтобы забрать требуемый
объем. Общая кэш-память допускает, чтобы «ненасытное» ядро снизило производи-
тельность других ядер.
Другой областью, в которой CMP отличается от своих более крупных собратьев, явля-
ется отказоустойчивость. Из-за тесных связей всех центральных процессоров отказы
в совместно используемых компонентах могут сразу нарушить работу нескольких
центральных процессоров, что менее вероятно для традиционных мультипроцессоров.
В дополнение к симметричным многоядерным микропроцессорам, у которых все ядра
одинаковы, существует еще одна распространенная категория многоядерных микро-
процессоров — система на кристалле (system on a chip). У этих микросхем имеется
один или несколько основных центральных процессоров, но также имеются и ядра спе-
циального назначения, такие как видео- и аудиодекодеры, криптопроцессоры, сетевые
интерфейсы и т. д., составляющие полную компьютерную систему на одном кристалле.
Многоядерные микропроцессоры
Понятие «мультиядро» означает просто «более одного ядра», но когда количество ядер
становится больше количества пальцев на руках, мы используем другой термин —
многоядерные микропроцессоры
(Manycore chips), которые являются мультиядрами,
содержащими десятки, сотни или даже тысячи ядер. Хотя порога, при переходе кото-
рого мультиядерные процессоры становятся многоядерными, не существует, простым
отличительным признаком возможного обладания многоядерным процессором может
послужить то, что вас больше уже не беспокоит потеря одного или двух ядер.
Дополнительные карты таких ускорителей, как разработанные компанией Intel Xeon
Phi, имеют свыше 60 x86-ядер. Другие производители уже преодолели барьер в сто ядер
различного типа. Возможно, они уже на пути к достижению планки в 1000 ядер общего
назначения. Трудно даже представить, что можно сделать с тысячей ядер, еще труднее
понять, как составлять для них программы.
Еще одна проблема, связанная с реально большим количеством ядер, заключается
в том, что оборудование, необходимое для сохранения согласованности их кэшей,
становится очень сложным и весьма дорогостоящим. Многие инженеры беспокоятся

8.1. Мультипроцессоры
589
о том, что согласованность кэшей не сможет масштабироваться на многие сотни ядер.
Некоторые даже становятся сторонниками того, что все мы вообще должны отказать-
ся от этой затеи. Они опасаются, что стоимость протоколирования согласованности
в оборудовании будет столь высока, что все эти великолепные новые ядра не помогут
существенно поднять производительность, потому что процессор будет слишком за-
нят поддержанием кэшей в согласованном состоянии. Хуже того, в связи с этим нужно
будет потратить слишком много памяти на быстродействующий каталог. Эта проблема
известна под именем барьера согласованности (coherency wall).
Рассмотрим, к примеру, наше показанное ранее решение поддерживать согласован-
ность кэша на основе каталога. Если в каждой записи каталога содержится битовый
вектор для указания того, какие ядра содержат конкретную строку кэша, длина записи
каталога для центрального процессора с 1024 ядрами будет как минимум 128 байтов,
что приведет к абсурдной ситуации, когда запись каталога окажется больше отслежи-
ваемой с ее помощью записи строки кэша. Наверное, это не соответствует желаемому
результату.
Некоторые специалисты соглашаются с тем, что единственной моделью программи-
рования, доказавшей возможность масштабирования на очень большое количество
процессоров, является модель, использующая передачу сообщений и распределен-
ную память, и именно этого нам следует ожидать и в будущих многоядерных микро-
процессорах. В экспериментальных процессорах наподобие 48-ядерного процессора
компании Intel, который называется SCC, от согласованности кэшей уже отказались
и предоставили вместо этого аппаратную поддержку быстрой передачи сообщений. Но
есть и другие процессоры, в которых согласованность по-прежнему предоставляется
даже при большом количестве ядер. Возможна также гибридная модель. Например,
микропроцессор с 1024 ядрами может быть поделен на 64 островка, каждый из которых
имеет 16 ядер с согласованными кэшами при отказе от согласовенности кэшей между
этими островками.
Наличие тысяч процессоров больше не в диковинку. Сегодня наиболее распространен-
ными многоядерными микропроцессорами являются графические процессоры (GPU),
которые можно найти практически в любой компьютерной системе, не являющейся
встроенной и имеющей монитор. Графический процессор имеет выделенную память
и буквально тысячи крошечных ядер. По сравнению с процессорами общего назначе-
ния транзисторный бюджет графических процессоров тратится в основном на схемы,
производящие вычисления, и в меньшей степени на кэши и логику управления. Они
хороши для множества небольших параллельных вычислений, подобных построению
многоугольников в графических приложениях. Для обычных задач они мало подходят.
Их также трудно программировать. Хотя графические процессоры могут пригодиться
для операционных систем (например, при шифровании или обработке сетевого тра-
фика), вряд ли на них будет работать основная часть самой операционной системы.
Графическими процессорами (GPU) все чаще обрабатываются и другие вычисли-
тельные задачи, особенно требующие больших вычислительных мощностей, что
нередко встречается в научных вычислениях. Термин, используемый для обработки
задач общего назначения (general purpose, GP) на графических процессорах (GPU),
как можно было догадаться, обозначается аббревиатурой GPGPU. К сожалению,
эффективное программирование графических процессоров является весьма сложной
задачей и требует применения специальных языков программирования, таких как
OpenGL
или CUDA, право собственности на которые принадлежит компании NVIDIA.

590
Глава 8. Многопроцессорные системы
Существенной разницей между программированием графических процессоров и про-
цессоров общего назначения является то, что графические процессоры по сути явля-
ются машинами, работающими по принципу «одна инструкция, множество данных»,
а это означает, что большое количество ядер выполняет одну и ту же инструкцию над
различными участками данных. Эта модель программирования хороша для паралле-
лизма данных, но не всегда удобна для других стилей программирования (таких, как
параллелизм задач).
Гетерогенные мультиядра
В некоторых микросхемах на одном кристалле объединяются графический процессор
и несколько ядер общего назначения. Аналогично этому многие однокристальные си-
стемы в дополнение к одному или нескольким процессорам специального назначения
содержат ядра общего назначения. Системы, объединяющие несколько разнородных
процессоров на одном кристалле, имеют общее название гетерогенных мультиядер-
ных процессоров. В качестве примера таких процессоров может послужить линейка
сетевых процессоров IXP, изначально представленная компанией Intel в 2000 году
и регулярно обновляемая с использованием самых передовых технологий. Сетевые
процессоры обычно содержат одно управляющее ядро общего назначения (например,
ARM-процессор, на котором запущена Linux) и многие десятки узкоспециализиро-
ванных потоковых процессоров, хорошо проявляющих себя в обработке сетевых па-
кетов и больше ни в чем другом. Они широко используются в сетевом оборудовании,
таком как маршрутизаторы и брандмауэры. Для маршрутизации сетевых пакетов вам,
вероятно, не пригодятся большие объемы вычислений с плавающей точкой, поэтому
в большинстве моделей потоковых процессоров вообще отсутствует блок таких вы-
числений. В то же время высокоскоростной сетевой обмен данными сильно зависит
от быстрого доступа к памяти (для чтения данных пакета), и у потоковых процессоров
имеется специальное оборудование для осуществления такого доступа.
Понятно, что в предыдущих примерах имелись в виду гетерогенные системы. Потоко-
вые процессоры и управляющие процессоры в IXP совершенно разные по строению,
с разными наборами инструкций. То же самое можно сказать о ядрах графических
процессоров и ядрах общего назначения. Но гетерогенность можно внедрять и при под-
держке одинакового набора инструкций. Например, у центрального процессора может
иметься небольшое количество «больших» ядер с большими конвейерами и, возможно,
высокими тактовыми частотами и большое количество «малых» ядер, которые просто
имеют меньшую мощность и, возможно, работают на более низких тактовых частотах.
Мощные ядра нужны для запуска кода, требующего быстрой последовательной обра-
ботки, а малые ядра пригодятся для задач, которые могут быть эффективно выполне-
ны в параллельном режиме. Примером гетерогенной архитектуры, соответствующей
данному направлению, может послужить семейство ARM-процессоров big.LITTLE.
Программирование при наличии нескольких ядер
Как это не раз случалось в прошлом, аппаратное обеспечение намного опережает
программное. Располагая многоядерными микропроцессорами, мы не имеем возмож-
ности создавать для них приложения. Использующиеся в настоящее время языки
программирования плохо приспособлены для написания хорошо распараллеленных
программ, а хорошие компиляторы и отладчики в этой области встречаются довольно
редко. Опыт параллельного программирования есть лишь у немногих программистов,