Добавлен: 29.10.2018
Просмотров: 48195
Скачиваний: 190

8.1. Мультипроцессоры
581
Как правило, кэширование реализуется не пословно, а блоками по 32 или 64 байта. При
обращении к слову в кэш обратившегося центрального процессора извлекается целый
блок, называемый строкой кэша (cache line), или кэш-строкой.
Каждый блок кэш-памяти маркируется как предназначенный только для чтения
(в этом случае он может в одно и то же время присутствовать в нескольких кэшах)
или как предназначенный для чтения и записи (в этом случае он, возможно, не при-
сутствует ни в каких других кэшах). Если центральный процессор пытается записать
слово, находящееся в одном или нескольких удаленных кэшах, аппаратура шины обна-
руживает запись и выставляет на шину сигнал, информирующий все остальные кэши
о записи. Если другие кэши имеют неизмененные копии, в точности соответствующие
содержимому блока в памяти, они могут просто забраковать эти копии и позволить
процессору, осуществляющему запись, извлечь имевшийся в кэше блок из памяти
перед его изменением. Если какие-нибудь другие кэши имели измененную копию, они
должны были либо записать его обратно в память перед осуществлением новой записи,
либо передать его по шине непосредственно тому процессору, который осуществлял
запись. Этот свод правил называется протоколом поддержки когерентности кэшей
(cache-coherence protocol), и это всего лишь один из многих протоколов.
Еще одна возможная архитектура представлена на рис. 8.2, в. Здесь у каждого про-
цессора имеется не только кэш, но и локальная собственная память, к которой он
имеет доступ по специальной собственной шине. Для оптимального использования
этой архитектуры компилятор должен помещать весь текст программы, все строки,
константы и другие данные, предназначенные только для чтения, стеки и локальные
переменные в локальные модули памяти. Тогда общая память используется только
для модифицируемых общих переменных. В большинстве случаев такое рачительное
размещение приведет к существенному сокращению объема данных, передаваемых по
шине, но потребует активного содействия со стороны компилятора.
UMA-мультипроцессоры, использующие
координатные коммутаторы
Даже при самом удачном кэшировании использование одной шины сводит масштаб
UMA-мультипроцессора всего лишь к 16 или 32 центральным процессорам. Чтобы
преодолеть этот барьер, нужен другой тип сети обмена данными. Простейшая схема
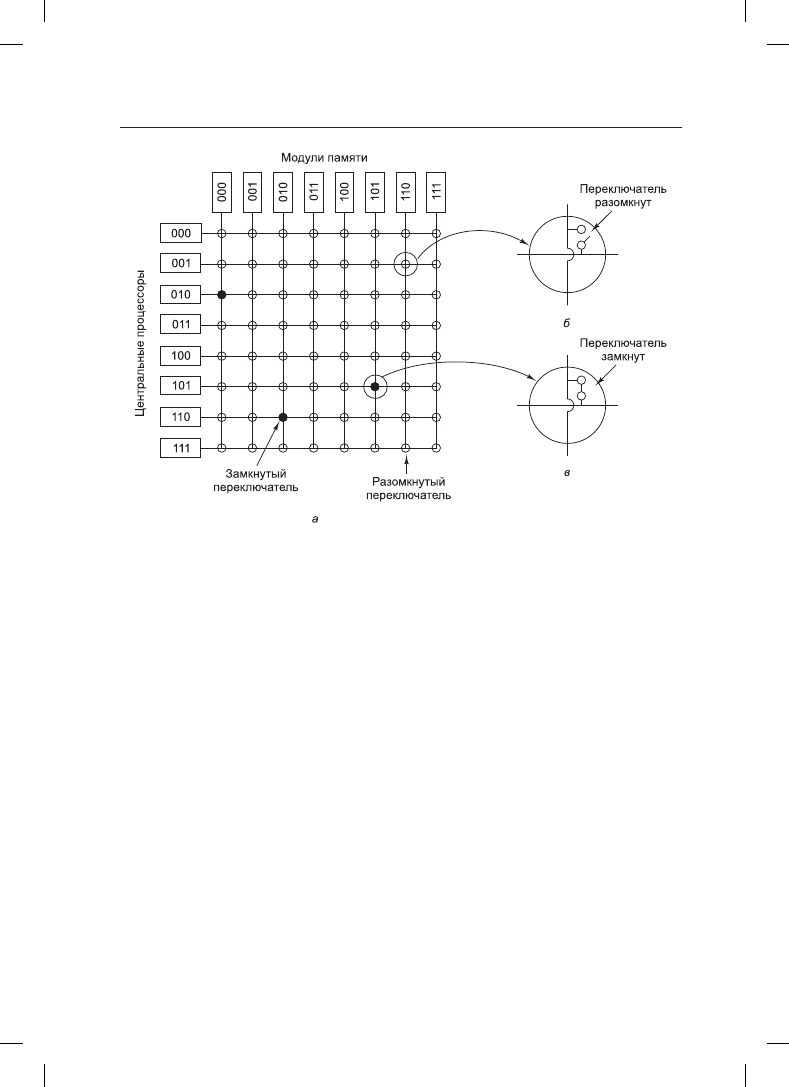
подключения n центральных процессоров к k модулям памяти — это координатный
коммутатор
(crossbar switch) (рис. 8.3). Координатный коммутатор десятилетиями ис-
пользовался для коммутации телефонных переговоров, чтобы произвольным образом
соединить группу входных линий с набором выходных линий.
В каждом пересечении горизонтальной (входной) и вертикальной (выходной) линий
стоит элемент коммутации, небольшой выключатель, который может пропускать или
не пропускать электрический сигнал, то есть быть включенным или выключенным
в зависимости от того, должны или не должны соединяться горизонтальная и верти-
кальная линии. На рис. 8.3, а изображены три одновременно включенных элемента,
позволяющие соединяться следующим парам «центральный процессор — модуль
памяти»: (001, 000), (101, 101) и (110, 010). Можно составить и множество других
комбинаций. Фактически число комбинаций равно количеству различных способов
расстановки восьми ладей на шахматной доске, при которых ни одна из этих фигур не
находилась бы под ударом другой.
582
Глава 8. Многопроцессорные системы
Рис. 8.3. Координатный коммутатор: а — три одновременно включенных элемента;
б — открытый элемент коммутации; в — закрытый элемент коммутации
У координатного коммутатора есть одно великолепное свойство: он представляет собой
неблокирующуюся сеть
(nonblocking network), то есть такую, где ни одному центрально-
му процессору никогда не будет отказано в необходимом ему подключении по причине
занятости какого-то элемента коммутации или линии (если предположить, что свободен
сам требуемый модуль памяти). Но это прекрасное свойство имеется не у всех внутрен-
них соединений. Кроме того, не нужно заниматься долгосрочным планированием. Даже
если уже установлены семь произвольных подключений, всегда будет возможность под-
ключить оставшийся центральный процессор к оставшемуся модулю памяти.
Конечно, не исключена конкуренция за подключение к памяти, возникающая, когда
два центральных процессора в одно и то же время требуют доступа к одному и тому
же модулю памяти. И все-таки по сравнению с моделью, показанной на рис. 8.2, за счет
разбиения памяти на n модулей конкуренция снижается в n раз.
Одним из отрицательных свойств координатного коммутатора является то, что коли-
чество элементов коммутации равно n
2
. При тысяче центральных процессоров и тыся-
че модулей памяти понадобится 1 млн элементов. Создать такой большой координатный
коммутатор просто нереально. Тем не менее архитектура, использующая координатный
коммутатор, вполне приемлема для средних по размеру вычислительных систем.
Мультипроцессоры UMA, использующие
многоступенчатые схемы коммутации
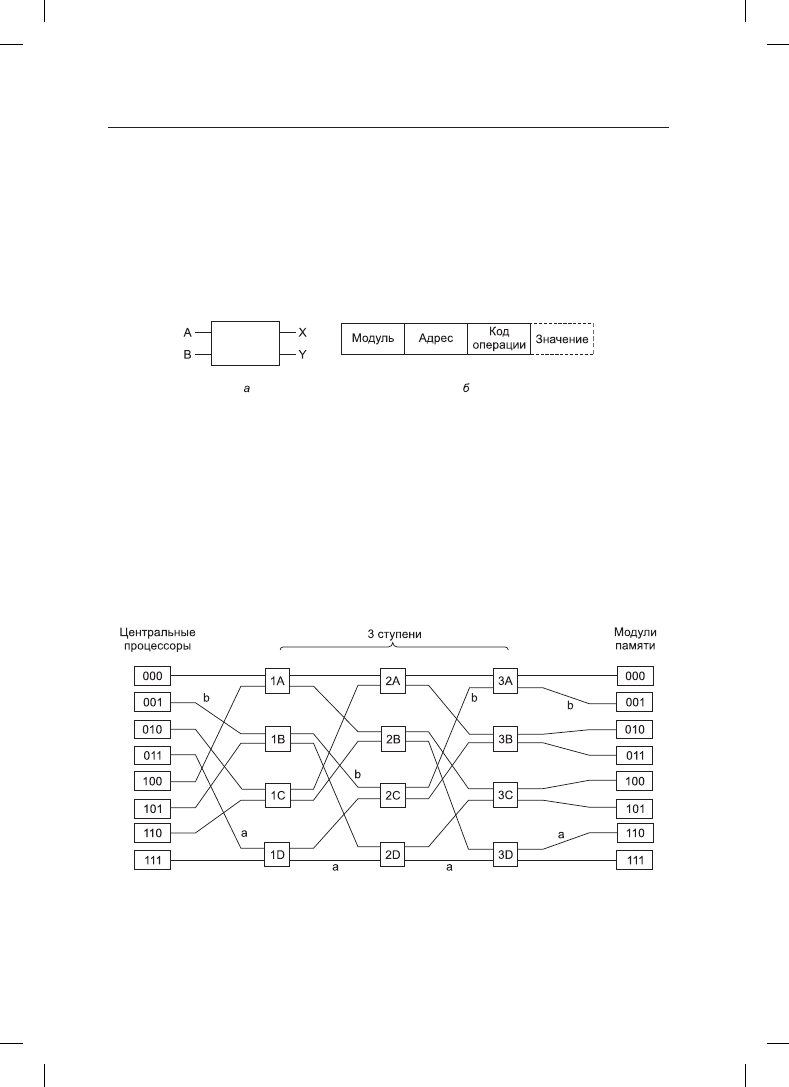
На рис. 8.4, а показана совершенно другая мультипроцессорная архитектура, построен-
ная на простых коммутаторах 2 × 2. У такого коммутатора есть два входа и два выхода.
8.1. Мультипроцессоры
583
Сообщения, поступающие по любой входной линии, могут быть скоммутированы на
любую выходную линию. Для решения наших задач сообщения будут содержать до
четырех частей (рис. 8.4, б). В поле
Module
(Модуль) сообщается, какой модуль па-
мяти следует использовать. В поле
Address
(Адрес) указывается адрес в этом модуле.
В поле
Opcode
(Код операции) предоставляется операция, например READ или WRITE.
И наконец, необязательное поле
Value
(Значение) может содержать операнд, например
32-разрядное слово, которое нужно записать с помощью операции WRITE. Коммута-
тор проверяет содержимое поля
Module
и использует его для определения того, куда
должно быть послано сообщение — на линию
X
или на линию
Y
.
Рис. 8.4. Коммутатор 2
× 2: а — с двумя входными, A и B, и двумя выходными, X и Y, линиями;
б — формат сообщения
С помощью коммутатора 2 × 2 можно построить самые разные большие многоступен-
чатые коммутаторные сети
(multistage switching networks), рассмотренные в Adams et
al. (1987), Garofalakis and Stergiou (2013), Kumar and Reddy (1987). Одна из возможных
схем, упрощенная сеть омега (omega network), относящаяся к эконом-классу, пока-
зана на рис. 8.5. Здесь с помощью 12 коммутаторов восемь центральных процессоров
подключаются к восьми модулям памяти. В общем, для n центральных процессоров
и n модулей памяти понадобится log
2
n ступеней с n/2 коммутаторами на каждую
ступень, а всего (n/2) log
2
n коммутаторов, что значительно лучше, чем n
2
элементов
коммутации, особенно для больших n.
Рис. 8.5. Схема коммутации омега
Схему электрической разводки в сети омега часто называют идеальным тасованием
(perfect shuffle), поскольку перемешивание сигналов на каждой ступени походит на
колоду карт, поделенную на две части, а затем перемешиваемую путем заведения одних

584
Глава 8. Многопроцессорные системы
карт за другие. Чтобы разобраться с работой сети омега, предположим, что центрально-
му процессору 011 понадобилось прочитать слово из модуля памяти 110. Центральный
процессор посылает сообщение READ коммутатору 1D, в котором в поле
Module
со-
держится значение 110. Коммутатор берет первый (то есть самый левый) бит из 110
и использует его для маршрутизации. Если значение равно 0, сообщение направляется
на верхний выход, а если 1, сообщение направляется на нижний выход. Поскольку бит
содержит 1, сообщение направляется через нижний выход на коммутатор 2D.
Все коммутаторы второй ступени, включая 2D, используют для маршрутизации второй
бит. В данном случае он также равен 1, поэтому теперь сообщение направляется через
нижний выход к коммутатору 3D. Там уже тестируется третий бит, который равен 0.
Следовательно, сообщение направляется через верхний выход и попадает, как и тре-
бовалось, к модулю памяти 110. Путь, по которому проходит это сообщение, помечен
на рис. 8.5 буквой a.
По мере прохождения сообщения по схеме коммутации самые левые биты номера мо-
дуля утрачивают свое значение. Ими можно воспользоваться снова, записывая в них
номер входящей линии, чтобы ответ смог отыскать обратный путь. Для пути a входные
линии имеют номера 0 (верхний вход 1D), 1 (нижний вход 2D) и 1 (нижний вход 3D).
Ответ будет направлен назад с помощью значения 011, только на этот раз чтение из
него будет производиться справа налево.
В это же время центральному процессору 001 требуется записать слово в модуль памя-
ти 001. Здесь происходит аналогичный процесс: сообщение направляется по верхнему,
опять по верхнему и по нижнему выходам, этот путь помечен буквой b. Когда сообще-
ние дойдет до адресата, его поле
Module
будет содержать значение 001, представляющее
пройденный им путь. Поскольку рассмотренные запросы не используют одни и те же
коммутаторы, линии и модули памяти, они могут выполняться параллельно.
Теперь посмотрим, что произойдет, если центральный процессор 000 одновременно
с этим захочет обратиться к модулю памяти 000. Его запрос вступит в конфликт с за-
просом центрального процессора 001 на коммутаторе 3A. Одному из них придется
подождать. В отличие от координатного коммутатора, сеть омега представляет собой
блокирующуюся сеть
(blocking network). Не все наборы запросов могут обрабаты-
ваться одновременно. При использовании линий или коммутаторов могут возникать
конфликты как между запросами к памяти, так и между ответами от памяти.
Возникает потребность в равномерном распределении обращений к модулям памяти.
Одна из распространенных технологий предусматривает использование младших раз-
рядов в качестве номера модуля. Рассмотрим, к примеру, байт-ориентированное адрес-
ное пространство компьютера, который в основном обращается к целым 32-разрядным
словам. Два младших разряда обычно имеют значение 00, но следующие три бита будут
распределены равномерно. За счет использования этих трех битов в качестве номера
модуля последовательные слова будут находиться в последовательных модулях. Си-
стема памяти, в которой следующие друг за другом слова находятся в разных модулях,
называется чередующейся (interleaved). Чередующиеся системы памяти позволяют
добиться максимального распараллеливания, потому что большинство обращений к па-
мяти осуществляется к следующим друг за другом адресам. Для более эффективного
распространения потока данных можно также разработать неблокирующиеся схемы
коммутации, предлагающие несколько путей от каждого центрального процессора
к каждому модулю памяти.

8.1. Мультипроцессоры
585
Мультипроцессоры NUMA
Число центральных процессоров для мультипроцессоров UMA с общей шиной огра-
ничено, как правило, несколькими десятками, а мультипроцессоры с координатной
или многоступенчатой коммутацией нуждаются в большом количестве дорогостоящей
аппаратуры, и количество центральных процессоров в них ненамного больше. Чтобы
задействовать более сотни центральных процессоров, нужно чем-то пожертвовать.
Обычно в жертву приносится идея одинакового времени доступа ко всем модулям па-
мяти. Эта уступка приводит к вышеупомянутой концепции мультипроцессоров NUMA.
Подобно своим родственникам UMA, они предоставляют единое адресное простран-
ство для всех центральных процессоров, но в отличие от них, доступ к локальным мо-
дулям памяти осуществляется быстрее, чем доступ к удаленным модулям. Поэтому все
программы, написанные для UMA, будут без изменений работать на NUMA-машинах,
но их производительность будет хуже, чем на UMA-машинах.
NUMA-машины обладают тремя ключевыми характеристиками, которые присущи им
всем и которые в совокупности отличают их от других мультипроцессоров:
1. В области видимости всех центральных процессоров находится единое адресное
пространство.
2. Доступ к удаленной памяти осуществляется с помощью команд LOAD и STORE.
3. Доступ к удаленной памяти осуществляется медленнее, чем доступ к локальной.
Когда время доступа к удаленной памяти не скрыто (по причине отсутствия кэши-
рования), система называется NC-NUMA (No Cache-coherent NUMA — NUMA без
согласованного кэширования). При наличии согласованной кэш-памяти система назы-
вается CC-NUMA (Cache-Coherent NUMA — NUMA с согласованным кэшированием).
В настоящее время самым популярным подходом при создании больших мультипро-
цессоров CC-NUMA является мультипроцессор на основе каталогов (directory-based
multiprocessor). Идея заключается в ведении базы данных, сообщающей, где находится
каждая кэш-строка и каково ее состояние. При обращении к кэш-строке запрашива-
ется база данных, чтобы определить, где она находится и какая информация в ней
содержится — неизмененная или измененная. Поскольку эта база данных должна за-
прашиваться при выполнении каждой команды, обращающейся к памяти, она должна
поддерживаться исключительно быстродействующей специализированной аппарату-
рой, откликающейся за доли такта шины.
Чтобы конкретизировать идею мультипроцессора, основанного на каталогах, рассмо-
трим простой (гипотетический) пример — систему, состоящую из 256 узлов, каждый
узел которой состоит из одного центрального процессора и 16 Мбайт оперативной
памяти, с которой этот процессор связан по локальной шине. Общий объем памяти
составляет 2
32
байт, которые поделены на 2
26
кэш-строк по 64 байт каждая. Память
статически распределена по узлам, где диапазон адресов 0–16 M выделен узлу 0,
16 M–32 M — узлу 1 и т. д. Узлы связаны схемой соединений, показанной на рис. 8.6, а.
Каждый узел содержит также записи каталога для 2
18
64-байтовых кэш-строк, вклю-
чающих в себя 2
24
байт памяти. Предположим на время, что строка может храниться
не более чем в одном кэше.
Чтобы понять, как работает каталог, проследим за командой LOAD из центрального
процессора 20, которая ссылается на кэш-строку. Сначала центральный процессор,
выдающий команду, передает ее своему блоку управления памятью (MMU), который