Добавлен: 29.10.2018
Просмотров: 48090
Скачиваний: 190

10.3. Процессы в системе Linux
811
Нажатие на клавишу
Del
не является единственным способом послать сигнал. Си-
стемный вызов kill позволяет процессу послать сигнал другому родственному про-
цессу. Выбор названия для данного системного вызова (kill — убить, уничтожить) не
особенно удачен, так как чаще всего сигналы посылаются процессами для того, чтобы
быть перехваченными. А вот неперехваченный сигнал, конечно же, убьет получателя.
Во многих приложениях реального времени бывает необходимо прервать процесс через
определенный интервал времени, чтобы что-то сделать, например передать повторно
потерянный пакет по ненадежной линии связи. Для обработки данной ситуации име-
ется системный вызов alarm (будильник). Параметр этого системного вызова задает
временной интервал в секундах, по истечении которого процессу посылается сигнал
SIGALRM. У процесса в каждый момент времени может быть только один будильник.
Например, если делается системный вызов alarm с параметром 10 с, а через 3 с снова
делается вызов alarm с параметром 20 с, то будет сгенерирован только один сигнал —
через 20 с после второго вызова. Первый сигнал будет отменен вторым обращением
к вызову alarm. Если параметр системного вызова alarm равен нулю, то такое обращение
отменяет любой невыполненный сигнал alarm. Если сигнал alarm не перехватывает-
ся, то выполняется действие по умолчанию — и процесс уничтожается. Технически
возможно игнорирование данного сигнала, но смысла это не имеет. Зачем программе
просить отправить сигнал чуть позже, а затем его игнорировать?
Иногда случается так, что процессу нечем заняться, пока не придет сигнал. Напри-
мер, рассмотрим обучающую программу, проверяющую скорость чтения и понимание
текста. Она отображает на экране некий текст, а затем делает системный вызов alarm,
чтобы система послала ей сигнал через 30 с. Пока студент читает текст, программе
делать нечего. Она может находиться (ничего не делая) в коротком цикле, но будет
напрасно расходовать время центрального процессора, которое может понадобиться
фоновому процессу или другому пользователю. Лучшее решение заключается в ис-
пользовании системного вызова pause, который дает указание операционной системе
Linux приостановить работу процесса до появления следующего сигнала. И горе той
программе, которая останавливается без выставления сигнала будильника.
10.3.3. Реализация процессов и потоков в Linux
Процесс в Linux подобен айсбергу: то, что вы видите, представляет собой всего лишь
выступающую над водой его часть, но не менее важная часть скрыта под водой. У каж-
дого процесса есть пользовательская часть, в которой работает программа пользова-
теля. Однако когда один из потоков делает системный вызов, то происходит эмули-
рованное прерывание с переключением в режим ядра. После этого поток начинает
работу в контексте ядра с другой картой памяти и полным доступом ко всем ресурсам
машины. Это все тот же самый поток, но теперь обладающий большей властью, а также
со своим стеком ядра и счетчиком команд в режиме ядра. Это важно, так как системный
вызов может блокироваться на полпути: например, в ожидании завершения дисковой
операции. При этом счетчик команд и регистры будут сохранены таким образом, чтобы
позднее поток можно было перезапустить в режиме ядра.
Ядро Linux внутренним образом представляет процессы как задачи (tasks) при помощи
структуры задач task_struct. В отличие от подходов других операционных систем (ко-
торые делают различия между процессом, легковесным процессом и потоком), Linux
использует структуру задач для представления любого контекста исполнения. Поэтому

812
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
процесс с одним потоком представляется одной структурой задач, а многопоточный
процесс будет иметь по одной структуре задач для каждого из потоков пользователь-
ского уровня. Наконец, само ядро является многопоточным и имеет потоки уровня
ядра, которые не связаны ни с какими пользовательскими процессами и выполняют
код ядра. Мы вернемся к обработке многопоточных процессов (и потоков вообще)
далее в этом же разделе.
Для каждого процесса в памяти всегда находится его дескриптор типа task_struct. Он
содержит важную информацию, необходимую ядру для управления всеми процессами
(в том числе параметры планирования, списки дескрипторов открытых файлов и т. д.).
Дескриптор процесса (вместе с памятью стека режима ядра для процесса) создается
при создании процесса.
Для совместимости с другими системами UNIX процессы в Linux идентифицируются
при помощи идентификатора процесса (Process Identifier (PID)). Ядро организует все
процессы в двунаправленный список структур задач. В дополнение к доступу к дескрип-
торам процессов при помощи перемещения по связанным спискам PID можно отобра-
зить на адрес структуры задач и немедленно получить доступ к информации процесса.
Структура задачи содержит множество полей. Некоторые из этих полей содержат
указатели на другие структуры данных или сегменты (например, содержащие инфор-
мацию об открытых файлах). Некоторые из этих сегментов относятся к структуре
процесса для пользовательского уровня (которая не представляет никакого интереса,
если пользовательский процесс не выполняется). Поэтому они могут быть вытеснены
в файл подкачки (чтобы не расходовать память на ненужную информацию). Например,
несмотря на то что процессу может быть послан сигнал в то время, когда он вытеснен,
он не может читать файл. По этой причине информация о сигналах всегда должна
находиться в памяти — даже когда процесса в памяти нет. В то же время информация
о дескрипторах файлов может храниться в пользовательской структуре и доставляться
только тогда, когда процесс находится в памяти и может выполняться.
Информация в дескрипторе процесса подразделяется на следующие категории:
1. Параметры планирования. Приоритет процесса, израсходованное за последний
учитываемый период процессорное время, количество проведенного в режиме
ожидания времени. Вся эта информация используется для выбора процесса, ко-
торый будет выполняться следующим.
2. Образ памяти. Указатели на сегменты: текста, данных и стека или на таблицы
страниц. Если сегмент текста используется совместно, то указатель текста ука-
зывает на общую таблицу текста. Когда процесса нет в памяти, то здесь также
содержится информация о том, как найти части процесса на диске.
3. Сигналы. Маски, указывающие, какие сигналы игнорируются, какие перехваты-
ваются, какие временно заблокированы, а какие находятся в процессе доставки.
4. Машинные регистры. Когда происходит эмулированное прерывание в ядро, то
машинные регистры (включая регистры с плавающей точкой) сохраняются здесь.
5. Состояние системного вызова. Информация о текущем системном вызове (вклю-
чая параметры и результаты).
6. Таблица дескрипторов файлов. Когда делается системный вызов, использующий
дескриптор файла, то файловый дескриптор используется как индекс в этой табли-
це для обнаружения соответствующей этому файлу структуры данных (i-node).

10.3. Процессы в системе Linux
813
7. Учетные данные. Указатель на таблицу, в которой отслеживается использованное
процессом пользовательское и системное время процессора. Некоторые системы
также хранят здесь предельные значения времени процессора, которое может ис-
пользовать процесс, максимальный размер его стека, количество блоков страниц,
которое он может использовать, и пр.
8. Стек ядра. Фиксированный стек для использования той частью процесса, которая
работает в режиме ядра.
9. Разное. Текущее состояние процесса, ожидаемые процессом события (если тако-
вые есть), время до истечения интервала будильника, PID процесса, PID роди-
тельского процесса, идентификаторы пользователя и группы.
Зная все это, легко объяснить, как в системе Linux создаются процессы. Механизм
создания нового процесса довольно прост. Для дочернего процесса создаются новый
дескриптор процесса и пользовательская область, которая заполняется в большей сте-
пени из родительского процесса. Дочерний процесс получает PID, затем настраивается
его карта памяти. Кроме того, дочернему процессу предоставляется совместный доступ
к файлам родительского процесса. Затем настраиваются регистры дочернего процесса,
после чего он готов к запуску.
Когда выполняется системный вызов fork, вызывающий процесс выполняет эмули-
рованное прерывание в ядро и создает структуру задач и несколько других сопут-
ствующих структур данных (таких, как стек режима ядра и структура thread_info).
Эта структура выделяется на фиксированном смещении от конца стека процесса
и содержит несколько параметров процесса (вместе с адресом дескриптора процесса).
Поскольку дескриптор процесса хранится в определенном месте, системе Linux нужно
всего несколько эффективных операций, чтобы найти структуру задачи для выполня-
ющегося процесса.
Большая часть содержимого дескриптора процесса заполняется значениями из де-
скриптора родителя. Затем Linux ищет доступный PID, который в этот момент не
используется любыми другими процессами, и обновляет элемент хэш-таблицы PID,
чтобы там был указатель на новую структуру задачи. В случае конфликтов в хэш-
таблице дескрипторы процессов могут быть сцеплены. Она также настраивает поля
в task_struct, чтобы они указывали на соответствующий предыдущий/следующий
процесс в массиве задач.
В принципе, теперь следует выделить память для данных потомка и сегментов стека
и сделать точные копии сегментов родителя, поскольку семантика системного вызова
fork говорит о том, что никакая область памяти не используется совместно родитель-
ским и дочерним процессами. Текстовый сегмент может либо копироваться, либо
использоваться совместно (поскольку он доступен только для чтения). В этот момент
дочерний процесс готов работать.
Однако копирование памяти является дорогим удовольствием, поэтому все совре-
менные Linux-системы слегка жульничают. Они выделяют дочернему процессу его
собственные таблицы страниц, но эти таблицы указывают на страницы родительского
процесса, помеченные как доступные только для чтения. Когда какой-либо процесс
(дочерний или родительский) пытается писать в такую страницу, происходит наруше-
ние защиты. Ядро видит это и выделяет процессу, нарушившему защиту, новую копию
этой страницы, которую помечает как доступную для чтения и записи. Таким образом,
копируются только те страницы, в которые дочерний процесс пишет. Такой механизм

814
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
называется копированием при записи (copy on write) . При этом дополнительно эко-
номится память, так как страницы с программой не копируются.
После того как дочерний процесс начинает работу, его код (в нашем примере это копия
оболочки) делает системный вызов exec, задавая имя команды в качестве параметра. При
этом ядро находит и проверяет исполняемый файл, копирует в ядро аргументы и строки
окружения, а также освобождает старое адресное пространство и его таблицы страниц.
Теперь надо создать и заполнить новое адресное пространство. Если системой поддер-
живается отображение файлов на адресное пространство памяти (как это делается, на-
пример, в Linux и практически во всех остальных системах на основе UNIX), то новые
таблицы страниц настраиваются следующим образом: в них указывается, что страниц
в памяти нет (кроме, возможно, одной страницы со стеком), а содержимое адресного
пространства зарезервировано исполняемым файлом на диске. Когда новый процесс
начинает работу, он немедленно вызывает страничную ошибку, в результате которой
первая страница кода подгружается из исполняемого файла. Таким образом, ничего
не нужно загружать заранее, что позволяет быстро запускать программы, а в память
загружать только те страницы, которые действительно нужны программам. (Эта стра-
тегия фактически является подкачкой по требованию в ее самом чистом виде — см.
главу 3.) Наконец, в новый стек копируются аргументы и строки окружения, сигналы
сбрасываются, а все регистры устанавливаются в нуль. С этого момента новая команда
может начинать исполнение.
Описанные шаги показаны на рис. 10.3 при помощи следующего примера: пользователь
вводит с терминала команду ls, оболочка создает новый процесс, клонируя себя с по-
мощью системного вызова fork. Новая оболочка затем делает системный вызов exec,
чтобы считать в свою область памяти содержимое исполняемого файла
ls
. После этого
можно приступать к выполнению
ls
.
Потоки в Linux
Потоки в общих чертах обсуждались в главе 2. Здесь мы сосредоточимся на потоках
ядра в Linux, и в особенности на различиях модели потоков в Linux и других UNIX-
системах. Чтобы лучше понять предоставляемые моделью Linux уникальные возмож-
ности, начнем с обсуждения некоторых трудных решений, присутствующих в много-
поточных системах.
При знакомстве с потоками основная проблема заключается в выдерживании кор-
ректной традиционной семантики UNIX. Рассмотрим сначала системный вызов fork.
Предположим, что процесс с несколькими (реализуемыми в ядре) потоками делает
системный вызов fork. Следует ли в новом процессе создавать все остальные потоки?
Предположим, что мы ответили на этот вопрос утвердительно. Допустим также, что
один из остальных потоков был блокирован (в ожидании ввода с клавиатуры). Должен
ли поток в новом процессе также быть блокирован ожиданием ввода с клавиатуры?
Если да, то какому потоку достанется следующая набранная на клавиатуре строка?
Если нет, то что должен делать этот поток в новом процессе?
Эта проблема касается и многих других аспектов. В однопоточном процессе такой про-
блемы не возникает, так как единственный поток не может быть блокирован при вызове
fork. Теперь рассмотрим случай, при котором в дочернем процессе остальные потоки
не создаются. Предположим, что один из несозданных потоков удерживает мьютекс,
который пытается получить единственный созданный поток нового процесса (после
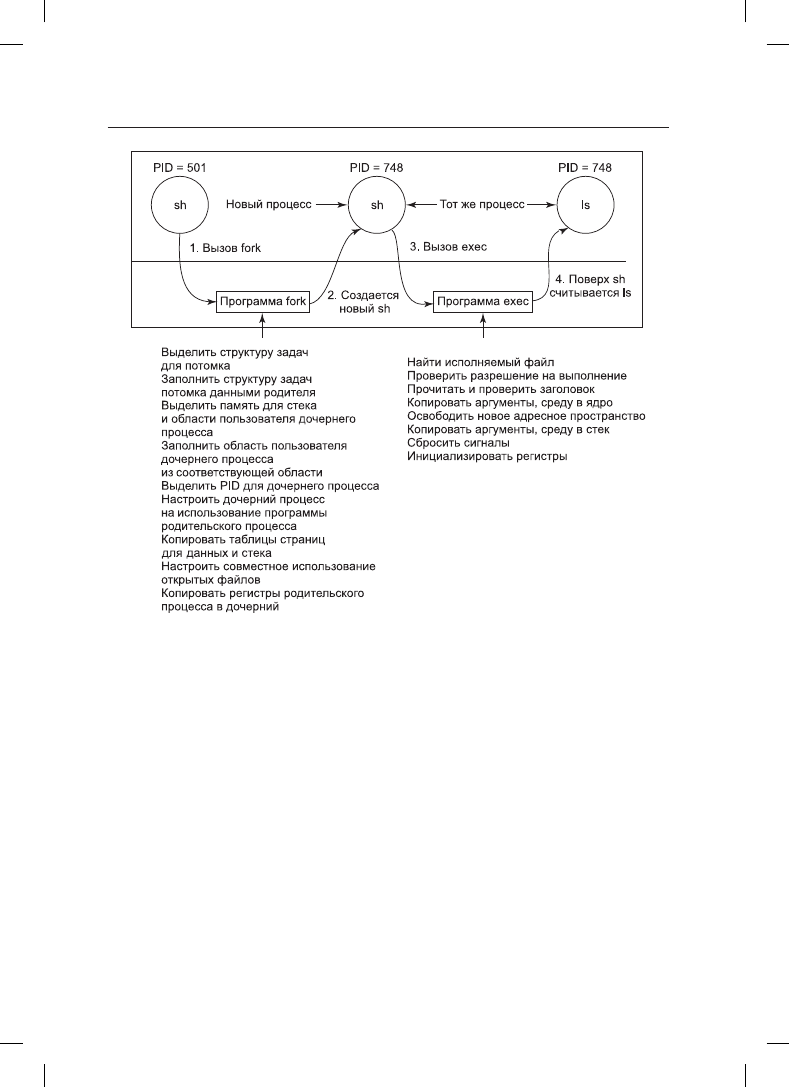
10.3. Процессы в системе Linux
815
Рис. 10.3. Шаги выполнения команды ls, введенной в оболочке
выполнения вызова fork). В этом случае мьютекс никогда не будет освобожден и новый
поток повиснет навсегда. Существует также множество других проблем. И простого
решения нет.
Файловый ввод-вывод представляет собой еще одну проблемную область. Предпо-
ложим, что один поток блокирован при чтении из файла, а другой поток закрывает
файл или делает системный вызов lseek, чтобы изменить текущий указатель файла.
Что произойдет дальше? Кто знает?
Обработка сигналов тоже представляет собой сложный вопрос. Должны ли сигналы
направляться определенному потоку или всему процессу в целом? Вероятно, сигнал
SIGFPE (Floating-Point Exception SIGnal — сигнал исключения при выполнении
операции с плавающей точкой) должен перехватываться тем потоком, который его
вызвал. А что, если он его не перехватывает? Следует ли убить этот поток? Или сле-
дует убить все потоки? Рассмотрим теперь сигнал SIGINT, генерируемый сидящим за
клавиатурой пользователем. Какой поток должен перехватывать этот сигнал? Должен
ли у всех потоков быть общий набор масок сигналов? При решении подобных проблем
любые попытки вытянуть нос в одном месте приводят к тому, что в каком-либо другом
месте увязает хвост. Корректная реализация семантики потоков (не говоря уже о коде)
представляет собой нетривиальную задачу.