Добавлен: 29.10.2018
Просмотров: 48086
Скачиваний: 190

816
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
Операционная система Linux поддерживает потоки в ядре довольно интересным спо-
собом, с которым стоит познакомиться. Эта реализация основана на идеях из систе-
мы 4.4BSD, но в дистрибутиве 4.4BSD потоки на уровне ядра реализованы не были, так
как у Калифорнийского университета в Беркли деньги кончились раньше, чем библи-
отеки языка C могли быть переписаны так, чтобы решить описанные ранее проблемы.
Исторически процессы были контейнерами ресурсов, а потоки — единицами исполне-
ния. Процесс содержал один или несколько потоков, которые совместно использовали
адресное пространство, открытые файлы, обработчики сигналов и все остальное. Все
было понятно и просто.
В 2000 году в Linux был введен новый мощный системный вызов clone, который размыл
различия между процессами и потоками и, возможно, даже инвертировал первенство
этих двух концепций. Вызова clone нет ни в одной из версий UNIX. Классически при
создании нового потока исходный поток (потоки) и новый поток совместно использо-
вали все, кроме регистров, — в частности, дескрипторы для открытых файлов, обработ-
чики сигналов, прочие глобальные свойства — все это было у каждого процесса, а не
у потока. Системный вызов clone дал возможность все эти аспекты сделать характерны-
ми как для процесса, так и для потока. Формат вызова выглядит следующим образом:
pid = clone(function, stack_ptr, sharing_flags, arg);
Вызов clone создает новый поток либо в текущем, либо в новом процессе (в зависи-
мости от флага sharing_flags). Если новый поток находится в текущем процессе, то он
совместно с существующими потоками использует адресное пространство и каждая
последующая запись в любой байт адресного пространства (любым потоком) тут же
становится видима всем остальным потокам процесса. Если же адресное пространство
совместно не используется, то новый поток получает точную копию адресного про-
странства, но последующие записи из нового потока уже не видны старым потокам.
Здесь используется та же семантика, что и у системного вызова fork по стандарту
POSIX.
В обоих случаях новый поток начинает выполнение функции function с аргументом arg
в качестве единственного параметра. Также в обоих случаях новый поток получает
собственный приватный стек, при этом указатель стека инициализируется парамет-
ром stack_ptr.
Параметр sharing_flags представляет собой битовый массив, обеспечивающий суще-
ственно более тонкую настройку совместного использования, чем традиционные си-
стемы UNIX. Каждый бит может быть установлен независимо от остальных, и каждый
из них определяет, копирует новый поток эту структуру данных или использует ее со-
вместно с вызывающим потоком. В табл. 10.4 показаны некоторые элементы, которые
можно использовать совместно или копировать — в соответствии со значением битов
в sharing_flags.
Бит CLONE_VM определяет, будет виртуальная память (то есть адресное пространство)
использоваться совместно со старыми потоками или будет копироваться. Если этот бит
установлен, то новый поток просто добавляется к старым потокам, так что в результате
системный вызов clone создает новый поток в существующем процессе. Если этот бит
сброшен, то новый поток получает собственное приватное адресное пространство.
Это означает, что результат выданных из него команд процессора STORE не виден
существующим потокам. Такое поведение подобно поведению системного вызова fork.
Создание нового адресного пространства равнозначно определению нового процесса.

10.3. Процессы в системе Linux
817
Таблица 10.4. Биты массива sharing_flags
Флаг
Значение при установке в 1
Значение при установке в 0
CLONE_VM
Создать новый поток
Создать новый процесс
CLONE_FS
Общие рабочий каталог, каталог
root и umask
Не использовать их совместно
CLONE_FILES
Общие дескрипторы файлов
Копировать дескрипторы файлов
CLONE_SIGHAND
Общая таблица обработчика
сигналов
Копировать таблицу
CLONE_PARENT
Новый поток имеет того же ро-
дителя, что и вызывающий
Родителем нового потока является
вызывающий
Бит CLONE_FS управляет совместным использованием рабочего каталога и катало-
га
root
, а также флага umask. Даже если у нового потока есть собственное адресное
пространство, при установленном бите CLONE_FS старый и новый потоки будут
совместно использовать рабочие каталоги. Это означает, что вызов chdir одним из
потоков изменит рабочий каталог другого потока, несмотря на то что у другого по-
тока есть собственное адресное пространство. В системе UNIX вызов chdir потоком
всегда изменяет рабочий каталог всех остальных потоков этого процесса, но никогда
не меняет рабочих каталогов других процессов. Таким образом, этот бит обеспечивает
такую разновидность совместного использования, которая недоступна в традицион-
ных версиях UNIX.
Бит CLONE_FILES аналогичен биту CLONE_FS. Если он установлен, то новый поток
предоставляет свои дескрипторы файлов старым потокам, так что вызовы lseek одним
потоком становятся видимыми для других потоков, что также обычно справедливо
для потоков одного процесса, но не потоков различных процессов. Аналогично бит
CLONE_SIGHAND разрешает или запрещает совместное использование таблицы об-
работчиков сигналов старым и новым потоками. Если таблица общая (даже для пото-
ков в различных адресных пространствах), то изменение обработчика в одном потоке
повлияет на обработчики в других потоках.
И наконец, каждый процесс имеет родителя. Бит CLONE_PARENT управляет тем, кто
является родителем нового потока. Это может быть родитель вызывающего потока
(в таком случае новый поток является братом вызывающего потока) либо сам вызы-
вающий поток (в таком случае новый поток является потомком вызывающего). Есть
еще несколько битов, которые управляют другими вещами, но они не так важны.
Такая детализация вопросов совместного использования стала возможна благодаря
тому, что в системе Linux для различных элементов, перечисленных в начале раздела
«Реализация процессов и потоков в Linux» (параметры планирования, образ памяти
и т. д.), используются отдельные структуры данных. Структура задач просто содержит
указатели на эти структуры данных, поэтому легко создать новую структуру задач для
каждого клонированного потока и сделать так, чтобы она указывала либо на структуры
(планирования потоков, памяти и пр.) старого потока, либо на копии этих структур.
Сам факт возможности такой высокой степени детализации совместного использова-
ния еще не означает, что она полезна, особенно потому что в традиционных версиях
UNIX это не поддерживается. Если какая-либо программа в системе Linux пользуется
этой возможностью, то это означает, что она больше не является переносимой на UNIX.

818
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
Модель потоков Linux порождает еще одну трудность. UNIX-системы связывают с про-
цессом один PID (независимо от того, однопоточный он или многопоточный). Чтобы
сохранять совместимость с другими UNIX-системами, Linux различает идентификато-
ры процесса PID и идентификаторы задачи TID. Оба этих поля хранятся в структуре
задач. Когда вызов clone используется для создания нового процесса (который ничего
не использует совместно со своим создателем), PID устанавливается в новое значение,
в противном случае задача получает новый TID, но наследует PID. Таким образом, все
потоки процесса получат тот же самый PID, что и первый поток процесса.
10.3.4. Планирование в Linux
Теперь мы рассмотрим алгоритм планирования системы Linux. Начнем с того, что по-
токи в системе Linux реализованы в ядре, поэтому планирование основано на потоках,
а не на процессах.
В операционной системе Linux алгоритмом планирования различаются три класса
потоков:
1. Потоки реального времени, обслуживаемые по алгоритму FIFO (First in First
Out — первым прибыл, первым обслужен).
2. Потоки реального времени, обслуживаемые в порядке циклической очереди.
3. Потоки разделения времени.
Обслуживаемые по алгоритму FIFO потоки реального времени имеют наивысшие
приоритеты и не могут вытесняться другими потоками, за исключением такого же
потока реального времени FIFO с более высоким приоритетом, перешедшего в состо-
яние готовности. Обслуживаемые в порядке циклической очереди потоки реального
времени представляют собой то же самое, что и потоки реального времени FIFO, но
с тем отличием, что они имеют квант времени и могут вытесняться по таймеру. Такой
находящийся в состоянии готовности поток выполняется в течение кванта времени,
после чего помещается в конец своей очереди. Ни один из этих классов не является
на самом деле классом реального времени. Здесь нельзя задать предельный срок вы-
полнения задания и гарантировать его выполнение. Эти классы просто имеют более
высокий приоритет, чем потоки стандартного класса разделения времени. Причина, по
которой в системе Linux эти классы называются классами реального времени, состоит
в том, что операционная система Linux соответствует стандарту P1003.4 (расширения
реального времени для UNIX), в котором используются такие имена. Потоки реального
времени внутри представлены приоритетами от 0 до 99, причем 0 — самый высокий,
а 99 — самый низкий приоритет реального времени.
Обычные потоки составляют отдельный класс и планируются по особому алгоритму,
поэтому с потоками реального времени они не конкурируют. Внутри системы этим
потокам ставится в соответствие уровень приоритета от 100 до 139, то есть внутри себя
Linux различает 140 уровней приоритета (для потоков реального времени и обычных).
Так же как и обслуживаемым в порядке циклической очереди потокам реального време-
ни, Linux выделяет обычным потокам время центрального процессора в соответствии
с их требованиями и уровнями приоритета. В Linux время измеряется количеством ти-
ков. В старых версиях Linux таймер работал на частоте 1000 Гц и каждый тик составлял
1 мс — этот интервал называют «джиффи » (jiffy — мгновение, миг, момент). В самых
последних версиях частота тиков может настраиваться на 500, 250 или даже 1 Гц. Чтобы

10.3. Процессы в системе Linux
819
избежать нерационального расхода циклов центрального процессора на обслуживание
прерываний от таймера, ядро может быть даже сконфигурировано в режиме «без ти-
ков», что может пригодиться при запуске в системе только одного процесса или про-
стое центрального процессора и необходимости перехода в энергосберегающий режим.
И наконец, на самых новых системах таймеры с высоким разрешением позволяют ядру
отслеживать время с джиффи-градацией.
Как и большинство UNIX-систем, Linux связывает с каждым потоком значение nice.
По умолчанию оно равно 0, но его можно изменить при помощи системного вызова
nice(value), где value меняется от –20 до +19. Это значение определяет статический
приоритет каждого потока. Вычисляющий в фоновой программе значение числа π
(с точностью до миллиарда знаков) пользователь может использовать этот вызов
в своей программе, чтобы быть вежливым по отношению к другим пользователям.
Только системный администратор может запросить лучшее по сравнению с другими
обслуживание (со значением от –20 до –1). В качестве упражнения вы можете попро-
бовать определить причину этого ограничения.
Далее более подробно будут рассмотрены два применяемых в Linux алгоритма плани-
рования. Их свойства тесно связаны с конструкцией очереди выполнения (runqueue),
основной структуры данных, используемой планировщиком для отслеживания
всех имеющихся в системе задач, готовых к выполнению, и выбора следующей за-
пускаемой задачи. Очередь выполнения связана с каждым имеющимся в системе
центральным процессором. Исторически сложилось так, что самым популярным
Linux-планировщиком был Linux O(1). Свое название он получил из-за способности
выполнять операции управления задачами, такие как выбор задачи или постановка
задачи в очередь выполнения за одно и то же время независимо от количества задач
в системе. В планировщике O(1) очередь выполнения организована в двух массивах:
активных задач и задач, чье время истекло. Как показано на рис. 10.4, а, каждый из
них представляет собой массив из 140 заголовков списков, соответствующих разным
приоритетам. Каждый заголовок списка указывает на дважды связанный список про-
цессов заданного приоритета Основы работы планировщика можно описать следую-
щим образом.
Планировщик выбирает в массиве активных задач задачу из списка задач с самым
высоким приоритетом. Если квант времени этой задачи истек, то она переносится
в список задач, чье время истекло (возможно, с другим уровнем приоритета). Если
задача блокируется (например, в ожидании события ввода-вывода) до истечения
ее кванта времени, то после события она помещается обратно в исходный массив
активных задач, а ее квант уменьшается на количество уже использованного вре-
мени процессора. После полного истечения кванта времени она также будет поме-
щена в массив задач, чье время истекло. Когда в массиве активных задач ничего не
остается, планировщик просто меняет указатели, чтобы массивы задач, чье время
истекло, стали массивами активных задач, и наоборот. Этот метод гарантирует, что
задачи с низким приоритетом не «умирают от голода» (за исключением случая,
когда потоки реального времени со схемой FIFO полностью захватывают ресурсы
процессора, что маловероятно).
При этом разным уровням приоритета присваиваются разные размеры квантов време-
ни и больший квант времени присваивается процессам с более высоким приоритетом.
Например, задачи с уровнем приоритета 100 получат квант времени 800 мс, а задачи
с уровнем приоритета 139 — 5 мс.
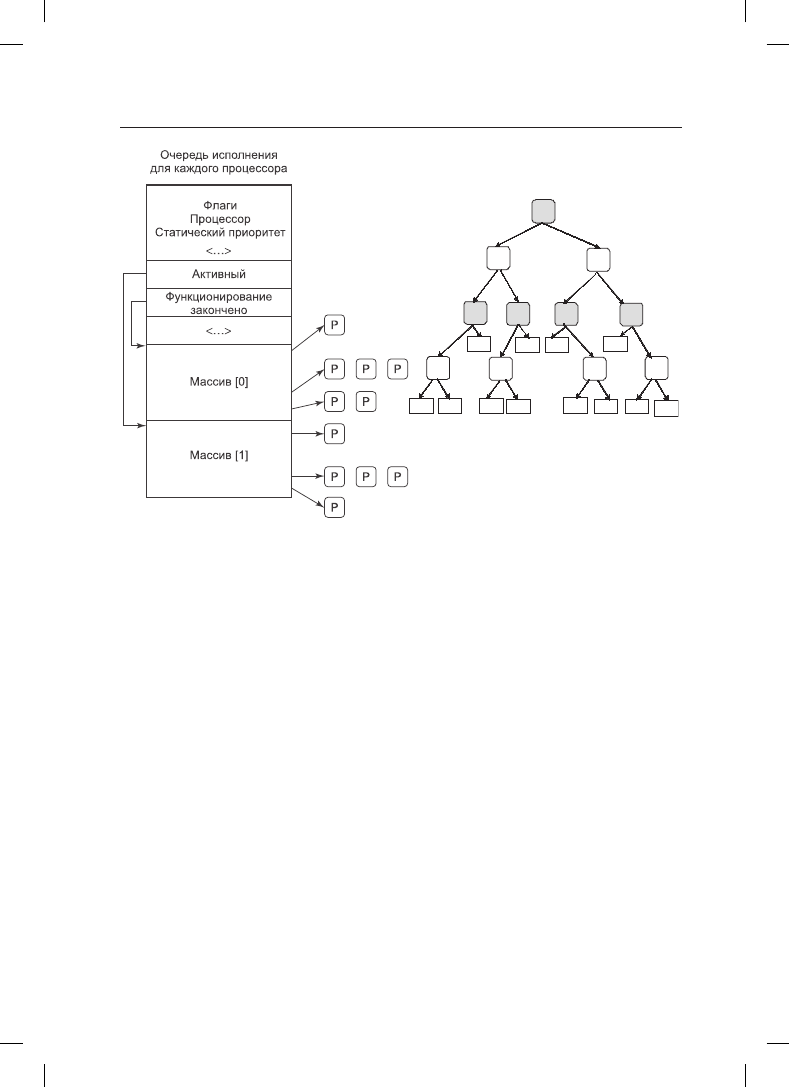
820
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
Priority 0
Priority 139
а) очередь выполнения для каждого
центрального процессора
в Linux-планировщике O(1);
35
26
47
10
30
38
62
3
27
45
86
NIL
NIL
NIL
NIL
NIL
NIL
NIL
NIL
NIL
NIL
NIL
NIL
б) красно-черное дерево для каждого
центрального процессора
в планировщике CFS
Priority 0
Priority 139
Рис. 10.4. Иллюстрация очереди исполнения: а — для Linux-планировщика O(1);
б — для планировщика Completely Fair Scheduler
Идея данной схемы в том, чтобы быстро убрать процессы из ядра. Если процесс пы-
тается читать дисковый файл, то секунда ожидания между вызовами read невероятно
затормозит его. Гораздо лучше позволить ему выполняться сразу же после завершения
каждого запроса, чтобы он мог быстро выполнить следующий запрос. Аналогично,
если процесс был блокирован в ожидании клавиатурного ввода, то это точно интерак-
тивный процесс, и ему нужно дать высокий приоритет сразу же, как он станет готов
к выполнению, чтобы обеспечить хорошее обслуживание интерактивных процессов.
Поэтому интенсивно использующие процессор процессы получают все, что остается
(когда блокированы все завязанные на ввод-вывод и интерактивные процессы).
Поскольку Linux (как и любая другая операционная система) заранее не знает, будет
задача интенсивно использовать процессор или ввод-вывод, она применяет эвристику
интерактивности. Для этого Linux различает статический и динамический приори-
тет. Динамический приоритет потока постоянно пересчитывается для того, чтобы,
во-первых, поощрять интерактивные потоки, а во-вторых, наказывать пожирателей
процессорных ресурсов. В планировщике O(1) максимальное увеличение приоритета
равно –5, поскольку более низкое значение приоритета соответствует более высокому
приоритету, полученному планировщиком. Максимальное снижение приоритета равно
+5. Планировщик поддерживает связанную с каждой задачей переменную sleep_avg.
Когда задача просыпается, эта переменная получает приращение, когда задача вытесня-