Добавлен: 29.10.2018
Просмотров: 48085
Скачиваний: 190

10.3. Процессы в системе Linux
821
ется или истекает ее квант, эта переменная уменьшается на соответствующее значение.
Это значение используется для динамического изменения приоритета на величину от
–5 до +5. Планировщик Linux пересчитывает новый уровень приоритета при переме-
щении потока из списка активных в список закончивших функционирование.
Алгоритм планирования O(1) относится к планировщику, ставшему популярным
в ранних версиях ядра 2.6, а впервые он был введен в нестабильной версии ядра 2.5.
Предыдущие алгоритмы показывали низкую производительность на многопроцес-
сорных системах и не могли хорошо масштабироваться с увеличением количества
задач. Поскольку представленное в предыдущем параграфе описание указывает, что
решение планирования может быть принято путем доступа к соответствующему списку
активных процессов, его можно выполнить за постоянное время О(1), не зависящее
от количества процессов в системе. Но несмотря на положительное свойство, заклю-
чавшееся в постоянном времени проведения операций, у планировщика O(1) имелись
существенные недостатки. Наиболее значимый состоял в том, что эвристическое пра-
вило, используемое для определения степени интерактивности задачи, а следовательно
уровня ее приоритета, было слишком сложным и несовершенным, что выражалось
в низкой производительности интерактивных задач.
Для решения этой проблемы Инго Молнар (Ingo Molnar), который также был созда-
телем планировщика O(1), предложил новый планировщик, названный совершенно
справедливым планировщиком (Completely Fair Scheduler (CFS)). Этот планировщик
был основан на идее, изначально принадлежавшей Кону Коливасу (Con Kolivas) для
более раннего планировщика, и впервые был интегрирован в ядро версии 2.6.23. Он
и сейчас является планировщиком по умолчанию для задач, не являющихся задачами
реального времени.
Главная идея, положенная в основу CFS, заключается в использовании в качестве
структуры очереди выполнения красно-черного дерева. Задачи в дереве выстраиваются
на основе времени, которое затрачивается на их выполнение на ценральном процессоре
и называется виртуальным временем выполнения — vruntime. CFS подсчитывает время
выполнения задачи с точностью до наносекунды. Как показано на рис. 10.4, б, каждый
внутренний узел дерева соотносится с задачей. Дочерние узлы слева соотносятся
с задачами, которые тратят меньше времени центрального процессора, и поэтому их
выполнение будет спланировано раньше, а дочерние записи справа от узла относятся
к задачам, которые до этих пор потребляли больше времени центрального процессора.
Листья дерева не играют в планировщике никакой роли.
Алгоритм планирования может быть кратко изложен следующим образом. CFS всегда
планирует задачу, которой требуется наименьшее количество времени центрального
процессора, обычно это самый левый узел дерева. Периодически CFS увеличивает
значение vruntime задачи на основе того времени, которое уже было затрачено на ее
выполение, и сравнивает его со значением текущего самого левого узла дерева. Если
выполняемая задача все еще имеет наименьшее значение vruntime, ее выполнение про-
должается. В противном случае она будет вставлена в соответствующее место в крас-
но-черном дереве, и центральный процессор получит задачу, соответсвующую новому
самому левому узлу дерева.
Чтобы учесть различия между приоритетами задач и значениями переменной nice, CFS
изменяет эффективную ставку, при которой проходит виртуальное время выполнения
задания, когда оно запущено на центральном процессоре. Для задач с более низким
уровнем приоритета время течет быстрее, их значение vruntime будет расти быстрее,

822
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
и в зависимости от других задач в системе они будут отлучаться от центрального про-
цессора и заново вставляться в дерево раньше, чем если бы у них был более высокий
приоритет. Благодаря этому CFS избегает использования отдельных структур очередей
выполнения для разных уровней приоритетов.
Таким образом, выбор узла для выполнения может быть сделан за постоянное время,
а вот вставка задачи в очередь выполнения осуществляется за время O(log(N)), где
N — количество задач в системе. С учетом уровней загруженности текущих систем это
время продолжает оставаться вполне приемлемым, но с увеличением вычисляемого
объема узлов и количества задач, которые могут выполняться в системах, в частности
в серверном пространстве, вполне возможно, что в дальнейшем будут предложены
новые алгоритмы планирования.
Кроме основных алгоритмов планирования Linux-планировщик имеет специальные
функциональные возможности, которые особенно полезны для многопроцессорных
или многоядерных платформ. Во-первых, с каждым процессором многопроцессорной
системы связана структура очереди выполнения. Планировщик старается использовать
преимущества родственного планирования и планировать задачи на тот процессор, на
котором они выполнялись ранее. Во-вторых, имеется набор системных вызовов для
указания требований к родственной принадлежности потока. И наконец, планировщик
выполняет периодическую балансировку нагрузки между очередями выполнения раз-
ных процессоров, чтобы обеспечить балансировку загрузки системы (выдерживая в то
же время определенные требования к производительности и соблюдению родственной
принадлежности).
Планировщик рассматривает только готовые к выполнению задачи, которые помеща-
ются в соответствующие очереди выполнения. Те задачи, которые не готовы к выпол-
нению и ждут выполнения различных операций ввода-вывода (или других событий
ядра), помещаются в другую структуру данных (очередь ожидания —waitqueue). Такая
очередь связана с каждым событием, которого могут дожидаться задачи. Заголовок
очереди ожидания содержит указатель на связанный список задач и спин-блокировку.
Спин-блокировка нужна для обеспечения одновременного манипулирования очере-
дью ожидания из кода ядра и обработчиков прерываний (или других асинхронных
вызовов).
Синхронизация в Linux
В предыдущих разделах уже упоминалось, что для предотвращения параллельного
изменения структур данных, подобных очередям ожидания, в Linux используются
спин-блокировки. Фактически в коде ядра переменные синхронизации встречаются во
многих местах. Далее будет предоставлен краткий обзор конструкций синхронизации,
доступных в Linux.
Более ранние ядра системы Linux имели просто одну большую блокировку ядра (big
kernel lock (BLK)). Это решение оказалось крайне неэффективным, особенно для
многопроцессорных платформ (поскольку мешало процессам на разных процессорах
одновременно выполнять код ядра). Поэтому было введено множество новых точек
синхронизации (с гораздо большей избирательностью).
Linux предоставляет несколько типов переменных синхронизации, которые исполь-
зуются внутри ядра и доступны приложениям и библиотекам на пользовательском
уровне. На самом нижнем уровне Linux предоставляет оболочки вокруг аппаратно

10.3. Процессы в системе Linux
823
поддерживаемых атомарных инструкций с помощью операций atomic_set и atomic_read.
Кроме этого, поскольку современное оборудование изменяет порядок операций с па-
мятью, Linux предоставляет барьеры памяти. Использование таких операций, как rmb
и wmb, гарантирует, что все относящиеся к памяти операции чтения-записи, предше-
ствующие вызову барьера, завершаются до любого последующего обращения к памяти.
Чаще используемые конструкции синхронизации относятся к более высокому уровню.
Потоки, не желающие осуществлять блокировку (из соображений производительности
или точности), используют обычные спин-блокировки, а также спин-блокировки по
чтению-записи. В текущей версии Linux реализуется так называемая билетная (ticket-
based) спин-блокировка, имеющая выдающуюся производительность на SMP и мульти-
ядерных системах. Потоки, которым разрешено или которые нуждаются в блокировке,
используют такие конструкции, как мьютексы и семафоры. Для выявления состояния
переменной синхронизации без блокировки Linux поддерживает неблокируемые вы-
зовы, подобные mutex_trylock и sem_trywait. Поддерживаются и другие типы перемен-
ных синхронизации вроде фьютексов (futexes), завершений (completions), блокировок
«чтение — копирование — обновление» (read — copy — update (RCU)) и т. д. И наконец,
синхронизация между ядром и кодом, выполняемым подпрограммами обработки пре-
рываний, может также достигаться путем динамического отключения и включения
соответствующих прерываний.
10.3.5. Загрузка Linux
Точные детали процесса загрузки варьируются от системы к системе, но в основном
загрузка состоит из следующих шагов. Когда компьютер включается, система BIOS
выполняет тестирование при включении (Power-On-Self-Test, POST), а также на-
чальное обнаружение устройств и их инициализацию (поскольку процесс загрузки
операционной системы зависит от доступа к дискам, экрану, клавиатуре и т. д.). Затем
в память считывается и исполняется первый сектор загрузочного диска (главная за-
грузочная запись
— Master Boot Record (MBR)). Этот сектор содержит небольшую
(512-байтовую) программу, считывающую автономную программу под названием
boot с загрузочного устройства, например с SATA- или SCSI-диска. Программа boot
сначала копирует саму себя в фиксированный адрес памяти в старших адресах, чтобы
освободить нижнюю память для операционной системы.
После этого перемещения программа boot считывает корневой каталог с загрузочного
устройства. Чтобы сделать это, она должна понимать формат файловой системы и ка-
талога (например, в случае загрузчика GRUB (GRand Unified Bootloader)). Другие
популярные загрузчики (такие, как LILO компании Intel) от файловой системы не
зависят. Им нужны карта блоков и адреса низкого уровня, которые описывают физи-
ческие сектора, головки и цилиндры (для поиска необходимых для загрузки секторов).
Затем boot считывает ядро операционной системы и передает ему управление. На этом
программа boot завершает свою работу, после чего уже работает ядро системы.
Начальный код ядра написан на ассемблере и является в значительной мере машинно
зависимым. Как правило, этот код настраивает стек ядра, определяет тип централь-
ного процессора, вычисляет количество имеющейся в наличии оперативной памяти,
отключает прерывания, разрешает работу блока управления памятью и, наконец, вы-
зывает процедуру main (написанную на языке C), чтобы запустить основную часть
операционной системы.

824
Глава 10. Изучение конкретных примеров: Unix, Linux и Android
Код на языке C также должен проделать значительную работу по инициализации, но
эта инициализация скорее логическая, нежели физическая. Она начинается с того, что
выделяется память под буфер сообщений, что должно помочь отладке проблем с загруз-
кой системы. По мере выполнения инициализации в этот буфер записываются сообще-
ния, информирующие о том, что происходит в системе. В случае неудачной загрузки их
можно выудить оттуда с помощью специальной программы диагностики. Этот буфер
подобен черному ящику, который обычно ищут на месте крушения самолета.
Затем выделяется память для структур данных ядра. Большинство этих структур име-
ют фиксированный размер, но, например, размер кэша страниц и некоторых структур
таблиц страниц зависит от доступного объема оперативной памяти.
Затем операционная система начинает определение конфигурации компьютера. Опе-
рационная система считывает файлы конфигурации, в которых сообщается, какие
типы устройств ввода-вывода могут присутствовать, и проверяет, какие из устройств
действительно присутствуют. Если проверяемое устройство отвечает, то оно добавля-
ется к таблице подключенных устройств. Если устройство не отвечает, то оно считается
отсутствующим и в дальнейшем игнорируется. В отличие от традиционных версий
UNIX, драйверы устройств системы Linux не обязаны быть статически связанными
и могут загружаться динамически (как это, кстати, может быть сделано во всех версиях
MS-DOS и Windows).
Аргументы в пользу динамической загрузки драйверов и против нее весьма интересны,
и их стоит кратко упомянуть. Главный аргумент в пользу динамической загрузки за-
ключается в том, что клиентам с различными конфигурациями может быть поставлен
один и тот же двоичный файл, который автоматически загрузит необходимые ему
драйверы, возможно, даже по сети. Главный аргумент против динамической загрузки
состоит в том, что этот метод противоречит принципам безопасности системы. Если
вы обеспечиваете работу защищенного сайта (например, базы данных банка или кор-
поративного веб-сервера), то, вероятно, захотите сделать невозможной вставку случай-
ного кода в ядро операционной системы. Системный администратор может хранить
исходные тексты операционной системы и объектные файлы на защищенной машине
и выполнять на ней все работы по сборке системы, после чего переносить двоичный
код ядра на другие машины по локальной сети. Если драйверы не могут загружаться
динамически, то такой сценарий предотвращает установку в ядро неотлаженного или
злонамеренного кода (системными операторами или еще кем-либо, кому известен
пароль суперпользователя). Более того, в больших системах конфигурация аппарату-
ры точно известна уже во время компиляции и компоновки операционной системы.
Изменения производятся довольно редко, поэтому перекомпоновка системы при до-
бавлении нового устройства не представляет собой проблемы.
После завершения конфигурации всего аппаратного обеспечения нужно аккуратно за-
грузить процесс 0, настроить его стек и запустить этот процесс. Процесс 0 продолжает
инициализацию, выполняя такие задачи, как программирование таймера реального
времени, монтирование корневой файловой системы и создание процесса 1 (init)
и страничного демона (процесс 2).
Процесс init проверяет свои флаги, в зависимости от которых он запускает опера-
ционную систему либо в однопользовательском, либо в многопользовательском
режиме. В первом случае он создает процесс, выполняющий оболочку, и ждет,
когда тот завершит свою работу. Во втором случае процесс init создает процесс,
исполняющий инициализационный сценарий оболочки системы /etc/rc, который
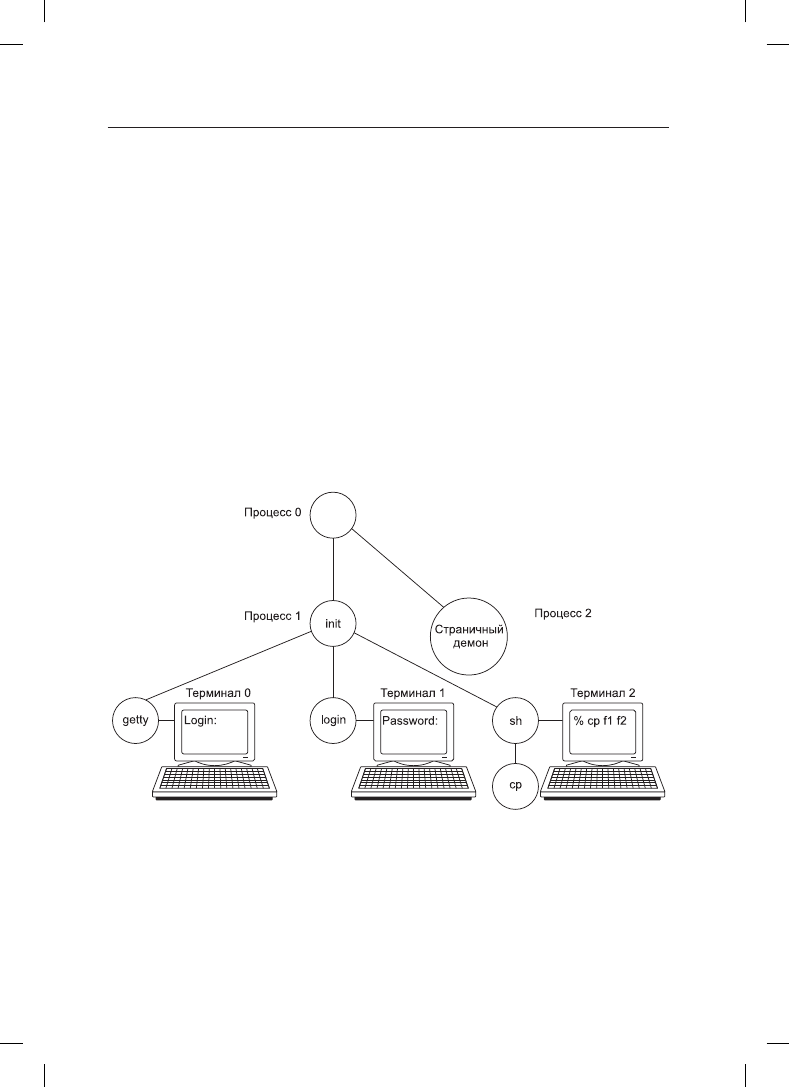
10.3. Процессы в системе Linux
825
может выполнить проверку непротиворечивости файловой системы, смонтировать
дополнительные файловые системы, запустить демонов и т. д. Затем он считывает
файл
/etc/ttys
, в котором перечисляются терминалы и некоторые их свойства. Для
каждого разрешенного терминала он создает копию самого себя, которая затем вы-
полняет программу getty.
Программа getty устанавливает для каждой линии (некоторые из них могут быть,
например, модемами) скорость и прочие свойства, после чего выводит на терминале
приглашение к входу в систему:
login:
После этого программа getty пытается прочитать с клавиатуры имя пользователя. Ког-
да пользователь садится за терминал и вводит свое регистрационное имя, программа
getty завершает свою работу выполнением программы регистрации /bin/login. После
этого программа login запрашивает у пользователя его пароль, шифрует его и срав-
нивает с зашифрованным паролем, хранящимся в файле паролей
/etc/passwd
. Если
пароль введен верно, то программа login вместо себя запускает оболочку пользователя,
которая ожидает первой команды. Если пароль введен неверно, то программа login еще
раз спрашивает имя пользователя. Этот механизм проиллюстрирован на рис. 10.5 для
системы с тремя терминалами.
Рис. 10.5. Последовательность исполняемых процессов при загрузке
некоторых версий системы Linux
На рисунке процесс getty, работающий на терминале 0, все еще ждет ввода. На тер-
минале 1 пользователь ввел имя регистрации, поэтому программа getty запустила
поверх себя процесс login, запрашивающий пароль. На терминале 2 уже произошла
успешная регистрация, в результате чего оболочка вывела приглашение к вводу (%).
Пользователь ввел команду
cp f1 f2