Файл: Федеральное государственное автономное образовательное учреждение высшего образования казанский (приволжский) федеральный университет высшая школа информационных технологий и информационных систем.docx
Добавлен: 08.11.2023
Просмотров: 96
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
Реализация
Практической частью моей дипломной работы является реализация High Availability кластера.
Я реализую свой HA-кластер для одноплатного компьютера Raspberry Pi, на который установлена операционная система Raspbian GNU/Linux 8.0. Кластер представляет собой имитатор исполнительного механизма, для того, чтобы отобразить режимы работы платы.
Raspberry Pi – это одноплатный компьютер размером с банковскую карту. Приложение разрабатывалось на плате Raspberry Pi версии 3В. На этой плате имеются все составляющие обычного компьютера, такие как: процессор, оперативная память, разъём HDMI, композитный выход, USB, Ethernet, Wi-Fi и Bluetooth.
Raspbian GNU/Linux – операционная система, основанная на Debian GNU/Linux для Raspberry Pi. В настоящее время эта ОС официально предоставляется Raspberry Pi Foundation, как основная операционная система для одноплатных компьютеров. ОС состоит из базовый про гамм и утилит, которые можно запустить на Raspberry Pi. Все еще находится в активной разработке.
Реализованный мной кластер состоит из:
-
Демона, который реализован на C++ -
Сервисного приложения, которое реализовано на python -
Клиентского приложения, которое реализовано на python
Демон стартует при загрузке операционной системы. Клиентское и сервисное приложение запускаются демоном. Демон и сервисное приложение запускаются на обоях машинах. Сервисное приложение запускается на локалхосте машины, и оно будет доступно только с самой платы. Клиентское приложение можно запустить с помощью сервисного на одной любой ноде, оно запускается с публичным адресом. В случае, когда другой узел перестает посылать heartbeat-сигналы, он считается неисправноым, и если на нем было запущено клиентское приложение, оно перезапускается на работающем узле.
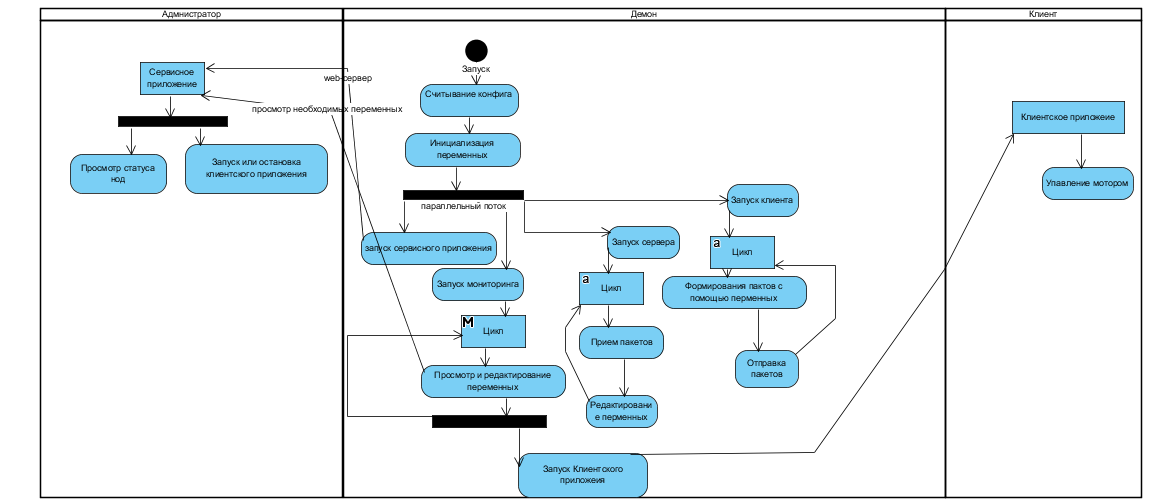
2.1 Демон
Демон в Linux – это процесс, который работает в фоновом режиме и не взаимодействует с пользователем. Демон стартует при запуске операционной системы и завершает свою работу при выключении системы. Демон запускается на обеих нодах.
В качестве языка реализации был выбран С++ версии 4.9. Этот язык наиболее удобным для разработки демона, так как синтаксис языка прост и понятен, его можно скомпилировать прямо в машинный код, поэтому он является одним из самых быстрых языков в мире
, так же у него очень много компиляторов, которые могут работать на различных платформах. Стандартные библиотеки этого языка работают во многих платформах. Все библиотеки, работающие в Си, будут работать и в C++.
В качестве среды разработки выбор пал на Eclipse C/C++ Development Tools (CDT). Возможности этой среды включают в себя: поддержку для создания проектов и управляемой сборки для различных инструментальных цепей, стандартную сборку, навигацию по источникам, различные исходные инструменты знаний, такие как иерархия типов, диаграмма вызовов, браузер, браузер макроопределений, редактор кода с подсветкой синтаксиса, сворачивание и гиперссылка для навигации, рефакторинга исходного кода и генерации кода, визуальных средств отладки, в том числе памяти, регистров и разборщиков.
Для реализации демона необходимо было изучить принцип работы демона в linux, и узнать, как можно реализовать его на языке С++. Также нужно было изучить принцип работы сетевого общения по udp (сокеты) и запустить в каждой ноде udp-сервер и udp- клиент.
Для успешного запуска и работы демона были реализованы данные функции:
-
int LoadConfig(char* FileName) - для загрузки конфигураций из файла -
int WriteLog(string Msg, ...) – для записи логов в файл -
void *Client(void*) – для запуска udp-клиента -
void *Server(void*) – для запуска udp-сервера -
void ServiceApp() – для запуска сервисного приложения -
void ClientApp() – для запуска клиентского приложения -
void *Monitoring(void*) – для проверки переменных, отвечающих за статус соседней ноды и клиентского приложения -
int InitWorkThread() – для инициализации потоков для клиента, сервера и мониторинга -
int WorkProc() – следит за работой InitWorkThread() и возвращает статус главному потоку -
void InitVars() – для инициализации глобальных переменных -
int Daemon() – главный поток, который следит за состоянием дочернего потока WorkProc и, в зависимости от кода завершения, может либо завершить работу или перезапустить дочерний поток WorkProc() -
static void signal_error(int sig, siginfo_t *si, void *ptr) – для обработки сигналов и вывод ошибок в лог -
int SetFdLimit(int MaxFd) - для установки максимального количества дескрипторов, которое может быть открыты. При исчерпывании дескрипторов невозможно будет открыть файл или создать сокет -
void SetPidFile(string Filename) – для создания PID файла -
int main(int argc, char** argv) – главная функция, которая создает поток.
После считывания конфигурационного файла, каждая функция начинает выводить в лог всю необходимою информацию. Запись в лог файл осуществляется функцией fput, которая позволяет записывать строку в файл.
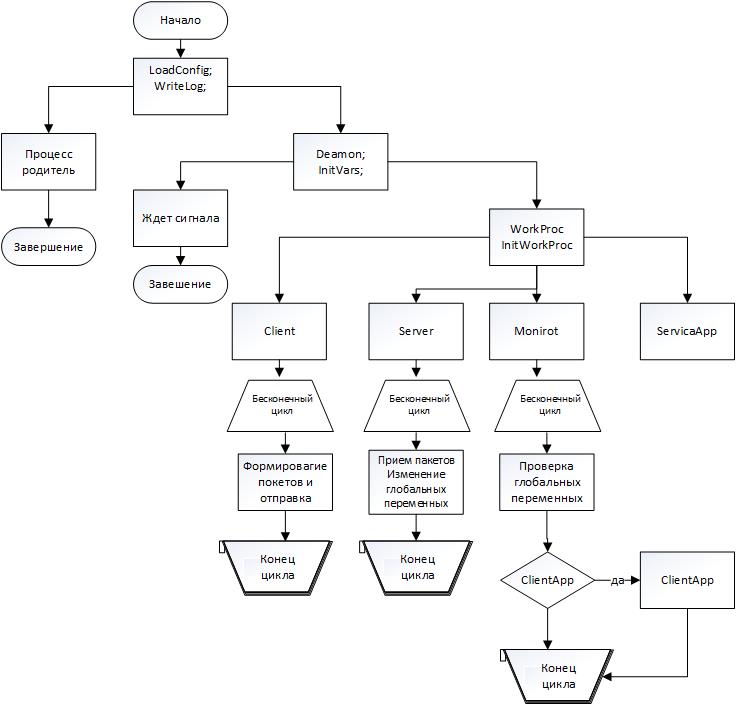
Реализация демона:
-
При страте ОС запускается демон и считывает информацию из конфигурационного файла:

Где:
-
log_file файл, в который записываются логи демона; -
my_ip – ip- адрес данной ноды; -
listen_port – порт, который слушает нода; -
another_ip – ip- адрес соседней ноды; -
another_port – порт, на который будет посылаться пакет; -
timeout – время, через которое демон определит другую ноду как недоступную и, при необходимости, запустить приложение у себя; -
app - пусть до запускаемого клиентского приложения.
Для считывания xml документа используется библиотека TinyXml, которая находится в директиве "tinyxml.lib".
-
Инициализируются переменные, которые будут отвечать за статус клиентского приложения и соседней ноды. В начале все переменные равны 0.
intnode_status; // статус соседней ноды: «0» – выключена, «1» - включена
intneed_start_app; // необходимость запуска или остановки клиентского приложения на данной ноде: «0» – не нужно запускать, «1» – нужно, «-1» – нужно остановить
intdiff_need_start; // необходимость запуска или остановки клиентского приложения на соседней ноде: «0» – не нужно запускать, «1» - нужно, «-1» – нужно остановить
int diff_app_status; // статус клиентского приложения на соседней ноде: «0» – не запущено, «1» - запущено
intmy_app_status; // статус приложения на данной ноде: «0» – не запущено, «1» - запущено
time_tlast_time; // время последнего прибывшего пакета от соседней ноды
-
Инициализируется дочерний поток, который будет следить за работой потока демона
-
Новый поток создается с помощью команды fork(), эта команда создаёт процесс-потомок, который является почти полной копией процесса родителя и она возвращает идентификатор PID потомка родителю, с помощью этого идентификатора родитель может «убить» потомка. -
Далее уже в потомке необходимо будет разрешить все права для создания новых файлов, с помощью команды umask(0). -
Чтобы не произошло проблем с размонтированием дисков, необходимо сменить корневую директорию chdir("/"). -
Для того, чтобы демон не имел доступ к консоли и не выводил ничего, необходимо закрыть все дескрипторы ввода, вывода и ошибок командами close(STDIN_FILENO), close(STDOUT_FILENO), close(STDERR_FILENO) – это позволит сэкономить ресурсы.
-
Создается новый поток демон, который может передать необходимые сигналы потоку родителю. -
Далее создаются потоки
Потоки создаются с помощью библиотеки POSIX thread (pthread). Она позволяет создавать новый параллельный поток процессов. Для потоков требуется меньше накладных расходов, чем для «forking»а. Все потоки внутри процесса имеют одинаковое адресное пространство. За создание нового потока отвечает функция pthread_create(thread, attr, start_routine, arg), где thread – это уникальных идентификатор для потока, attr - Объект непрозрачного атрибута, который может использоваться для установки атрибутов потока (можно NULL), start_routine – вызываемая функция, arg – единственный аргумент функции типа void (может быть NULL). Для того, чтобы два потока одновременно не обращались к одной переменной, необходимо на время блокировать доступ к ней, для этого есть специальная функция pthread_mutex_lock, и для разблокировки pthread_mutex_unlock. Область памяти, на которую ссылается код между этими функциями блокируется при вызове первой и освобождается, при вызове второй.
Создаются 4 потока:
-
Client:
Udp-клиент, который инициализирует соединение и каждые 2 секунды посылает значение переменных diff_need_startи my_app_status.
-
Server:
Udp-сервер, который инициализирует соединение и принимает пакеты и сохраняет время последнего прибывшего пакета и записывает в лог информацию. В пакете содержится информация, которая сохраняется в переменные need_start_appи diff_app_status.
-
Monitor:
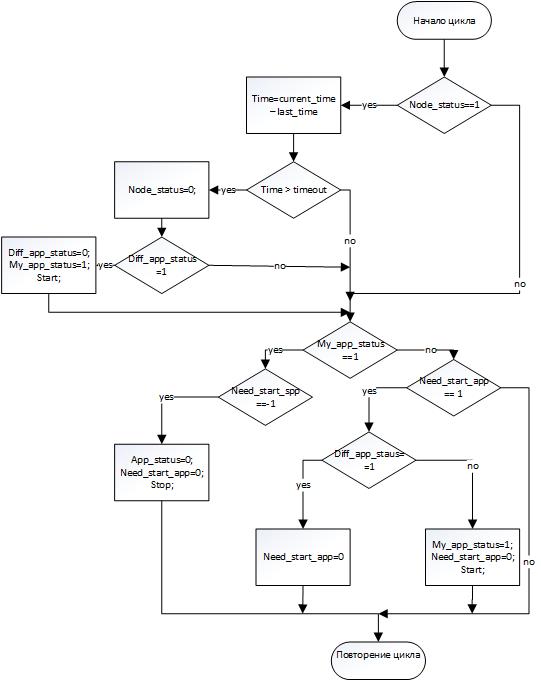
Функция, которая следит за состоянием соседней ноды, а также отвечает за запуск или остановку клиентского приложения. На блоксхеме изображен алгоритм работы функции. Далее показана блоксхема работы функции монитор. Запуск и остановка клиентского приложения осуществляется функцией мониторинга. Для остановки клиентского приложения используется PID процесса, в котором оно было запущено.
-
ServerceApp
Поток запускает приложение сервиса
В данном случае время недоступности клиентского приложения, при отказе сервера, на котором оно запущено, зависит от значения переменной timeout и времени, которое занимает поднятия web-сервера.