Файл: Федеральное государственное автономное образовательное учреждение высшего образования казанский (приволжский) федеральный университет высшая школа информационных технологий и информационных систем.docx
Добавлен: 08.11.2023
Просмотров: 98
Скачиваний: 2
ВНИМАНИЕ! Если данный файл нарушает Ваши авторские права, то обязательно сообщите нам.
СОДЕРЖАНИЕ
2.2 Сервисное приложение
Сервисное приложение реализовано на Python 3 c использованием фреймворка, для создания web-приложений, Flask. Flask – это небольшой фреймворк для создания веб-сайтов. Flask является простым, но быстро расширяемым ядром.
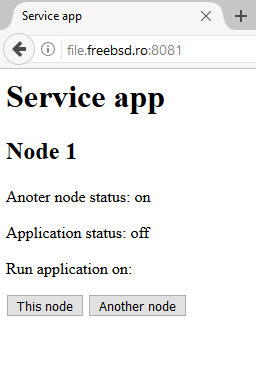
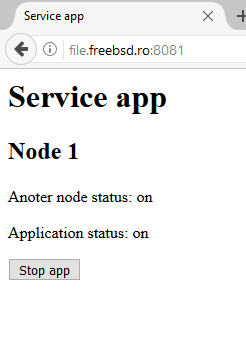
Сервисное приложение запускается каждым демоном на обеих нодах. Необходимые данные о статусе приложения и ноды считываются из файла, который генерирует демон.
Администратор, может сам выбрать, ноду, на которой запустить, а также остановить сервисное приложения. После чего данные о запуске и остановке клиентского приложения передаются демону.
Чтобы запустить сервер используется функция app.run(host='0.0.0.0',port=8081), где host – это ip-адрес, а port – это порт, на котором подниается сервер.
Для того, чтобы привязать функцию к URL используются декораторы. Вызов декоратора выглядит так @app.route('/', methods=['GET', 'POST']). Это означает, что при вводе в адресной строке браузера 'http://0.0.0.0:8081/' сервер вернет страницу, которая описана в функции под декоратором. При запрашивании браузером метода GET, сервером должна предоставляется html страница. Проверить вызываемый метод можно с помощью условие request.method = 'GET', после которого необходимо вернуть html страницу с помощью функции return render_template('index_3.html') Если происходит вызов метода POST, значить браузер хочет сообщить некоторую информацию серверу, и сервер должен ее обработать и что-то вернуть браузеру, это проверяется с помощью условия request.method = 'POST'. Проверка нажатия кнопки происходит с помощью метода request.form['submit'] == 'This node', где 'This node' это название кнопки в html коде. Далее можно вернуть любую страниу, с помощью метода return redirect(url_for('.contact')) , где contact, это функция, которая привязана к декоратору.
Для успешного запуска сервера также необходимо создать html страницы, которые будут предоставляться при запросе браузера. Все страницы, которые будут необходимы для работы сервера должны находиться подпапке templates, которая находиться в той же папке, что и скрипт питона. В html коде также описывается метод POST, который включается в себя кнопки
, на которые будет нажимать администратор.
2.3 Клиентское приложение.
Реализовано на Python 3 c использованием фреймворка, для создания web-приложений, Flask. Клиентское приложение запускается демоном, при поступлении сигнала о запуске из серверного приложения. Клиентское приложение управляет работой физического моторчика, который двигается вокруг своей оси, в зависимости от выбранного варианта.
Чтобы запустить сервер используется функция app.run(host='0.0.0.0',port=8081), где host – это ip-адрес, а port – это порт, на котором подниается сервер.
Для того, чтобы привязать функцию к URL используются декораторы. Вызов декоратора выглядит так @app.route('/', methods=['GET', 'POST']). Это означает, что при вводе в адресной строке браузера 'http://0.0.0.0:8081/' сервер вернет страницу, которая описана в функции под декоратором. При запрашивании браузером метода GET, сервером должна предоставляется html страница. Проверить вызываемый метод можно с помощью условие request.method = 'GET', после которого необходимо вернуть html страницу с помощью функции return render_template('index_3.html') Если происходит вызов метода POST, значить браузер хочет сообщить некоторую информацию серверу, и сервер должен ее обработать и что-то вернуть браузеру, это проверяется с помощью условия request.method = 'POST'. Проверка нажатия кнопки происходит с помощью метода request.form['submit'] == 'Left', где 'Left' это название кнопки в html коде, после чего запускается метод, который управляет макетом. Далее можно вернуть любую страницу, с помощью метода return redirect(url_for('.web_function')) , где web_function, это функция, которая привязана к декоратору.
Для успешного запуска сервера также необходимо создать html страницы, которые будут предоставляться при запросе браузера. Все страницы, которые будут необходимы для работы сервера должны находиться подпапке templates, которая находиться в той же папке, что и скрипт питона. В html коде также описывается метод POST, который включается в себя кнопки, на которые будет нажимать администратор.
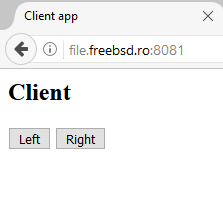
Пока клиент удерживает одну из кнопок, происходит поворот мотора на импровизированном моторе, После того, как кнопка была опущена, мотор прекращает свое движение.
Вывод.
Главным преимуществом кластерных решений являются обеспечение более высокий уровень доступности, по сравнению с единичным сервером или компьютером, высокая степень масштабируемости и также удобство в администрировании. Высокий уровень доступности позволяет уменьшить время, во время которого сервис не предоставляется. Клстерное решение может гарантировать, что в случае отказа, какого-либо модуля сервера, его функции продолжит выполнять другой сервер.
В дипломной работе было проведено исследование кластерных технологий, дана общая характеристика кластеров и из видов. Также были рассмотрены аналоги, существующие на рынки. После чего было реализовано свое кластерное решение, которое работает на всех дистрибутивах ОС Linux. Также было реализовано приложения, которые осуществляли управление кластером и приложение, которое работало в кластере и позволяло управлять макетным механизмом.
Список литературы.
-
https://m.habrahabr.ru/company/ispsystem/blog/313066/ -
http://pubs.vmware.com/vsphere-60/topic/com.vmware.ICbase/PDF/vsphere-esxi-vcenter-server-601-availability-guide.pdf -
http://xgu.ru/wiki/Remus -
https://github.com/corosync/corosync -
http://www.vmgu.ru/news/vmware-fault-tolerance-performance -
http://research.microsoft.com/en-us/um/people/moscitho/publications/icdcs06.pdf -
https://www.ibm.com/support/knowledgecenter/en/SSPHQG_6.1.0/com.ibm.hacmp.concepts/ha_concepts_continuum.htm -
https://www.mulesoft.com/resources/esb/high-availability-cluster -
https://www.globalscape.com/managed-file-transfer/high-availability -
http://gridbus.csse.unimelb.edu.au/papers/ic_cluster.pdf -
http://www.intuit.ru/studies/courses/1147/223/lecture/5756?page=2 -
http://old.ci.ru/inform10_99/p_08_9.htm -
http://www.ibm.com/developerworks/ru/library/l-Cluster_Linux_1/ -
http://www.computer-museum.ru/technlgy/klaster.htm -
https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/5/html/Cluster_Suite_Overview/s1-rhcs-intro-CSO.html -
https://de.wikipedia.org/wiki/HP_Serviceguard -
http://www8.hp.com/ru/ru/products/servers/hp-ux.html?compURI=1454628#.WGJznrJ95hE -
https://habrahabr.ru/post/129207 -
https://pastebin.com/jdX5wn0E -
http://flask.pocoo.org/docs/0.12/.latex/Flask.pdf -
http://www.yolinux.com/TUTORIALS/LinuxTutorialPosixThreads.html -
http://pubs.opengroup.org/onlinepubs/009695399/functions/pthread_mutex_lock.html -
https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BC%D0%BE%D0%BD_(%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B0) -
https://rsdn.org/article/unix/sockets.xml -
https://ru.wikipedia.org/wiki/Flask_(%D0%B2%D0%B5%D0%B1-%D1%84%D1%80%D0%B5%D0%B9%D0%BC%D0%B2%D0%BE%D1%80%D0%BA) -
https://flask-russian-docs.readthedocs.io/ru/latest/
Приложение
Приложение 1.
| Решение | Время простоя (отключения) | Доступность данных | Стоимость |
| Автономное (Standalone) | Дни | С последней резервной копии | Базовые затраты на аппаратное и программное обеспечение ($) |
| Улучшенное автономное (Enhanced standalone) | Часы | До последней транзакции | Двойные затраты на аппаратное обеспечение ($$) |
| Кластеры высокой доступности (High availability clusters) | Минуты | До последней транзакции | Двойные затраты на аппаратное обеспечение и дополнительное обслуживание ($$+) |
| Отказоустойчивые вычислительные системы (fault-tolerant computing) | Никогда не отключаются | Без потери данных | Специализированное аппаратное и программное обеспечение, очень дорогостоящее ($$$$$$) |
| PowerHA | Минуты | До последней транзакции | Двойная или тройная стоимость аппаратного обеспечения + дополнительные затраты на связь ($$$$) |
Приложение 2.
| Volume Size | Cluster Size | ||||
| FAT16 | FAT32 | exFAT | NTFS | ReFS | |
| 7 MBs to 16 MBs | 512 bytes | N/A | 4 KBs | 512 bytes | N/A |
| 17 MBs to 32 MBs | 512 bytes | N/A | 4 KBs | 512 bytes | N/A |
| 33 MBs to 64 MBs | 1 KB | 512 bytes | 4 KBs | 512 bytes | N/A |
| 65 MBs to 128 MBs | 2 KBs | 1 KB | 4 KBs | 512 bytes | N/A |
| 129 MBs to 256 MBs | 4 KBs | 2 KBs | 4 KBs | 512 bytes | N/A |
| 257 MBs to 512 MBs | 8 KBs | 4 KBs | 32 KBs | 512 bytes | N/A |
| 513 MBs to 1024 MBs | 16 KBs | 4 KBs | 32 KBs | 1 KB | 64 KBs |
| 1025 MBs to 2 GBs | 32 KBs | 4 KBs | 32 KBs | 4 KBs | 64 KBs |
| 2 GBs to 4 GBs | 64 KBs | 4 KBs | 32 KBs | 4 KBs | 64 KBs |
| 4 GBs to 8 GBs | N/A | 4 KBs | 32 KBs | 4 KBs | 64 KBs |
| 8 GBs to 16 GBs | N/A | 8 KBs | 32 KBs | 4 KBs | 64 KBs |
| 16 GBs to 32 GBs | N/A | 16 KBs | 32 KBs | 4 KBs | 64 KBs |
| 32 GBs to 2 TBs | N/A | * | 128 KBs | 4 KBs | 64 KBs |
| 2 TBs to 16 TBs | N/A | * | 128 KBs | 4 KBs | 64 KBs |
| 16 TBs to 32 TBs | N/A | * | 128 KBs | 8 KBs | 64 KBs |
| 32 TBs to 64 TBs | N/A | * | 128 KBs | 16 KBs | 64 KBs |
| 64 TBs to 128 TBs | N/A | * | 128 KBs | 32 KBs | 64 KBs |
| 128 TBs to 256 TBs | N/A | * | 128 KBs | 64 KBs | 64 KBs |